latin专题

hive学习2:Hive drop table卡住的问题,mysql字符集修改了latin,但是还是不行解决方案
刚开始接触hive,在删除表时卡住了,根据网上播客修改mysql字符集为latin,测试后还是不行,给下修改mysql字符串地址:修改mysql字符串地址 我这边修改后是还是无法删除,搞了大半个小时还是不行,最后,只能报着试试的心态升级mysql驱动jar试试,成功了,我之前的旧的jar版本是mysql-connector-java-5.1.6.jar 替换为mysql-con

python3 pymysql 'latin-1' codec can't encode character 错误 问题解决
完整代码: #coding: utf-8 import pymysql # 打开数据库连接 db = pymysql.connect("localhost","root","00000000","TESTDB" ,use_unicode=True, charset="utf8") # 若没有 use_unicode=True, charset="utf8" 那么就会发生如


matplotlib保存eps出错:'latin-1'codec can't encode characters in position 9-12:ordinal not in range(256)
原因:保存路径含有中文。 matplotlib保存eps的两种方法: 1. 图片右上角保存按钮 2. 代码方式 out_fig = plt.gcf()out_fig.savefig('out.eps', format='eps', dpi=1000)
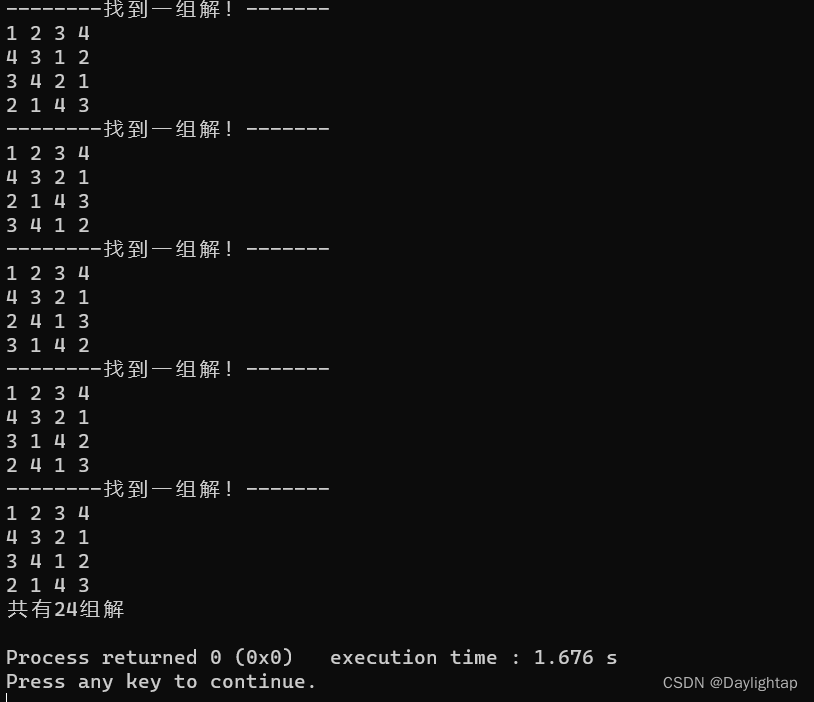
回溯法解决Latin方格(每个数在每行每列只出现一次)
填入每一个数都是一层递归 使用k来把每一个数的二维数组坐标求出来: int row=(k-1)/n;int col=(k-1)%n; 完整代码: #include<iostream>using namespace std;const int N=1010;int A[N][N],t[N];int n,cnt;bool judge(int row,int col){

824. Goat Latin
824. 山羊拉丁文 给定一个由空格分割单词的句子 S。每个单词只包含大写或小写字母。 我们要将句子转换为 “Goat Latin”(一种类似于 猪拉丁文 - Pig Latin 的虚构语言)。 山羊拉丁文的规则如下: 如果单词以元音开头(a, e, i, o, u),在单词后添加"ma"。 例如,单词"apple"变为"applema"。 如果单词以辅音字母开头(即非元音字母),移除

解决python中requests请求时报错:UnicodeEncodeError: ‘latin-1‘ codec can‘t encode character
出问题的代码: import requestsfrom fake_useragent import UserAgentmy_cookie = ("cna=DbGFGMr/uwYCAWdVkMXhdvE2; t=345dcf6624b93228c09a5d0b4b9c39f""d; tracknick=\u5317\u5BAB\u4F9D\u4E91; enc=rk/rlSa2hHpBpCAzJ

jpa创建数据库表 字符集默认latin 拉丁字符集,不支持中文导致错误,
解决办法,修改数据库字符集 执行如下sql alter table student convert to character set utf8;
![[oeasy]python0 113_字符编码_VT100控制码_iso_8859_1_拉丁字符_latin](https://img-blog.csdnimg.cn/img_convert/d2f9aba5a951a5c31b1388b48e121535.png)
[oeasy]python0 113_字符编码_VT100控制码_iso_8859_1_拉丁字符_latin
拉丁字符 回忆上次内容 上次回顾了字型编码的进化过程 7-bit 的 点阵字库终于让 字母、数字、标点 明确了字型 但是 7-bit 的 ascii中 没有法文字符的位置 如果扩展位为1 不同的计算机厂商 有各自不同的 扩展方式 这噩梦 比法语不兼容 更可怕!😱这以后 编码就越来越多了互认对方为乱码 法文字符 完全被 不同的字符集 直接 变成乱码 这可怎么办呢?🤔 那可是法国