本文主要是介绍Linux 4 6内核对TCP REUSEPORT的优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
繁忙了一整天,下班回家总会有些许轻松,这是肯定的。时间不等人,只要有剩余的时间,就想来点自己喜欢的东西。下班的班车上,用手机那令人遗憾的屏幕目睹了Linux 4.6的一些新特性,让我感兴趣的有两点,第一是关于reuseport的,这也是本文要阐释的,另外一个是关于KCM(Kernel Connection Multiplexor)的,而这个是我本周末计划要写的内容,这些都是回忆,且都是我本身经历过的,正巧天气预报说今晚有暴雨,激起了一些兴趣,于是信手拈来,不足之处或者写的不明之处,还望有人可以指出。我想从Q&A说起,这也符合大众的预期,如果你真的能理解我的Q&A想说什么,那么Q&A之后接下来的内容,不看也罢。
Q1:什么是reuseport?
A1:reuseport是一种套接字复用机制,它允许你将多个套接字bind在同一个IP地址/端口对上,这样一来,就可以建立多个服务来接受到同一个端口的连接。
Q2:当来了一个连接时,系统怎么决定到底是哪个套接字来处理它?
A2:对于不同的内核,处理机制是不一样的,总的说来,reuseport分为两种模式,即热备份模式和负载均衡模式,在早期的内核版本中,即便是加入对reuseport选项的支持,也仅仅为热备份模式,而在3.9内核之后,则全部改为了负载均衡模式,两种模式没有共存,虽然我一直都希望它们可以共存。
【我并没有进一步说什么是热备份模式和负载均衡模式,这意味着我在等待提问者进一步发问】
Q3:什么是热备份模式和负载均衡模式呢?
A3:这个我来分别解释一下。
热备份模式:即你创建了N个reuseport的套接字,然而工作的只有一个,其它的作为备份,只有当前一个套接字不再可用的时候,才会由后一个来取代,其投入工作的顺序取决于实现。
负载均衡模式:即你创建的所有N个reuseport的套接字均可以同时工作,当连接到来的时候,系统会取一个套接字来处理它。这样就可以达到负载均衡的目的,降低某一个服务的压力。
Q4:到底怎么取套接字呢?
A4:这个对于热备份模式和负载均衡模式是不同的。
热备份模式:一般而言,会将所有的reuseport同一个IP地址/端口的套接字挂在一个链表上,取第一个即可,如果该套接字挂了,它会被从链表删除,然后第二个便会成为第一个。
负载均衡模式:和热备份模式一样,所有reuseport同一个IP地址/端口的套接字会挂在一个链表上,你也可以认为是一个数组,这样会更加方便,当有连接到来时,用数据包的源IP/源端口作为一个HASH函数的输入,将结果对reuseport套接字数量取模,得到一个索引,该索引指示的数组位置对应的套接字便是工作套接字。
Q5:那么会不会第一个数据包由套接字m处理,后续来的数据包由套接字n处理呢?
A5:这个问题其实很容易,仔细看一下算法就会发现,只要这些数据包属于同一个流(同一个五元组),那么它每次HASH的结果将会得到同一个索引,因此处理它的套接字始终是同一个!
Q6:我怎么觉得有点玄呢?【这最后一个问题是我在一个同事的启发下自问自答的...】
A6:确实玄!TCP自己会保持连接,我们暂且不谈。对于UDP而言,比如一个事务中需要交互4个数据包,第一个数据包的元组HASH结果索引到了线程1的套接字的问题,它理所当然被线程1处理,在第二个数据包到达之前,线程1挂了,那么该线程的套接字的位置将会被别的线程,比如线程2的套接字取代!在第二个数据包到达的时候,将会由线程2的套接字来处理之,然而线程2并不知道线程1保存的关于此连接的事务状态...
我们来看下Q6/A6,这个问题确实存在,但是却不是什么大问题,这个是和实现相关的,所以并不是reuseport机制本身的问题。我们完全可以用数组代替链表,并且维持数组的大小,即使线程n挂了,它的套接字所在的位置并不被已经存在的套接字占据,而必须是被新建的替补线程(毕竟线程n已经挂了,要新建一个补充)的套接字占据,这样就能解决问题,所需的仅仅是任何线程在挂之前把状态信息序列化,然后在新线程启动的时候重新反序列化信息即可。
到此为止,我没有提及任何关于Linux 4.6内核对TCP reuseport优化的任何信息,典型的标题党!
然而,以上几乎就是全部信息,如果说还有别的,那就只能贴代码了。事实上,在Linux 4.6(针对TCP)以及Linux 4.5(针对UDP)的优化之前,我上述的Answer是不准确的,在4.5之前,Linux内核中关于reuseport的实现并非我想象的那样,然而为了解释概念和机制,我不得不用上述更加容易理解的方式去阐述,原理是一回事,实现又是一回事,请原谅我一直以来针对原理的阐述与Linux实现并不相符。
可想而知,4.5/4.6的所谓reuseport的优化,它仅仅是一种更加自然的实现方式罢了,相反,之前的实现反而并不自然!回忆三年来,有多少人问过我关于reuseport的事情,其中也不乏几位面试官,如果被进一步追问“Q:你确定Linux就是这么实现的吗?”那么我一定回答:“不!不是这么实现的,Linux的实现方法很垃圾!”,然后就会听到我滔滔不绝的阐释大量的形而上的东西,最终在一种不那么缓和的气氛中终止掉对话。
总结一下吧,事实上Linux 4.5/4.6所谓的对reuseport的优化主要体现在查询速度上,在优化前,不得不在HASH冲突链表上遍历所有的套接字之后才能知道到底取哪个(基于一种冒泡的score打分机制,不完成一轮冒泡遍历,不能确定谁的score最高),之所以如此低效是因为内核将reuseport的所有套接字和其它套接字混合在了一起,查找是平坦的,正常的做法应该是将它们分为一个组,进行分层查找,先找到这个组(这个很容易),然后再在组中找具体的套接字。Linux 4.5针对UDP做了上述优化,而Linux 4.6则将这个优化引入到了TCP。
设想系统中一共有10000个套接字被HASH到同一个冲突链表,其中9950个是reuseport的同一组套接字,如果按照老的算法,需要遍历10000个套接字,如果使用基于分组的算法,最多只需要遍历51个套接字即可,找到那个组之后,一步HASH就可以找到目标套接字的索引!
之所以要遍历是因为所有的reuseport套接字和其它的套接字都被平坦地插入到同一个表中,事先并不知道有多少组reuseport套接字以及每一组中有多少个套接字,比如下列例子:
reuseport group1-0.0.0.0:1234(sk1,sk2,sk3,sk4)
reuseport group2-1.1.1.1:1234(sk5,sk6,sk7)
other socket(sk8,sk9,sk10,sk11)
假设它们均被HASH到同一个位置,那么可能的顺序如下:
sk10-sk2-sk3-sk8-sk5-sk7-...
虽然sk2就已经匹配了,然而后面还有更精确的sk5,这就意味着必须把11个套接字全部遍历完后才知道谁会冒泡到最上面。
我们着重看一下reuseport_select_sock,这个函数是第二层组内查找的关键,其实不应该叫做查找,而应该叫做定位更加合适:
也不是那么神奇,不是吗?基本上在Q&A中都已经涵盖了。
因为我可以确定系统中不会有任何其它的reuseport套接字,且我可以确定设备的CPU个数是16个,因此定义数组如下:
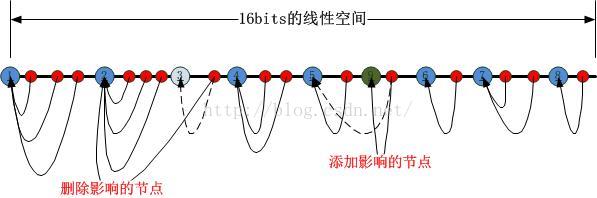
Q7:有没有什么统一的方法可以应对reuseport套接字的新增和删除呢?比如新建一个工作负载线程,一个工作线程挂掉这种动态行为。
A7:有的。那就是“一致性HASH”算法。
理解了原理之后,我们看一下怎么实现这个mini一致性HASH。真正的一致性HASH实现起来太重了,网上也有很多的资料可查,我这里只是给出一个思路,谈不上最优。根据上图,我们可以看到,归根结底需要一个“区间查找”,也就是说最终需要做的就是“判定第二类HASH结果落在了由第一类HASH结果分割的哪个区间内”,因此在直观上,可以采用的就是二叉树区间匹配,在此,我把上述的区间分割整理成一颗二叉树:
日耳曼向左,罗马向右!接下来就可以在这个二叉树上进行二分查找了。
Q8:在reuseport的查找处理上,TCP和UDP的区别是什么?
A8:TCP的每一条连接均可以由完全的五元组信息自行维护一个唯一的标识,只需要按照唯一的五元组信息就可以找出一个TCP连接,但是对于Listen状态的TCP套接字就不同了,一个来自客户端的SYN到达时,五元组信息尚未确立,此时正是需要找出是reuseport套接字组中到底哪个套接字来处理这个SYN的时候。待这个套接字确定以后,就可以和发送SYN的客户端建立唯一的五元组标识了,因此对于TCP而言,只有Listen状态的套接字需要reuseport机制的支持。对于UDP而言,则所有的套接字均需要reuseport机制的支持,因为UDP不会维护任何连接信息,也就是说,协议栈不会记录哪个客户端曾经来过或者正在与之通信,没有这些信息,因此对于每一个数据包,均需要reuseport的查找逻辑来为其对应一个处理它的套接字。
你知道每天最令人悲哀的事情是什么吗?那就是重复着一遍又一遍每天都在重复的话。
Q&A
当有人问起我关于reuseport的一些事的时候,我们的对话基本如下:Q1:什么是reuseport?
A1:reuseport是一种套接字复用机制,它允许你将多个套接字bind在同一个IP地址/端口对上,这样一来,就可以建立多个服务来接受到同一个端口的连接。
Q2:当来了一个连接时,系统怎么决定到底是哪个套接字来处理它?
A2:对于不同的内核,处理机制是不一样的,总的说来,reuseport分为两种模式,即热备份模式和负载均衡模式,在早期的内核版本中,即便是加入对reuseport选项的支持,也仅仅为热备份模式,而在3.9内核之后,则全部改为了负载均衡模式,两种模式没有共存,虽然我一直都希望它们可以共存。
【我并没有进一步说什么是热备份模式和负载均衡模式,这意味着我在等待提问者进一步发问】
Q3:什么是热备份模式和负载均衡模式呢?
A3:这个我来分别解释一下。
热备份模式:即你创建了N个reuseport的套接字,然而工作的只有一个,其它的作为备份,只有当前一个套接字不再可用的时候,才会由后一个来取代,其投入工作的顺序取决于实现。
负载均衡模式:即你创建的所有N个reuseport的套接字均可以同时工作,当连接到来的时候,系统会取一个套接字来处理它。这样就可以达到负载均衡的目的,降低某一个服务的压力。
Q4:到底怎么取套接字呢?
A4:这个对于热备份模式和负载均衡模式是不同的。
热备份模式:一般而言,会将所有的reuseport同一个IP地址/端口的套接字挂在一个链表上,取第一个即可,如果该套接字挂了,它会被从链表删除,然后第二个便会成为第一个。
负载均衡模式:和热备份模式一样,所有reuseport同一个IP地址/端口的套接字会挂在一个链表上,你也可以认为是一个数组,这样会更加方便,当有连接到来时,用数据包的源IP/源端口作为一个HASH函数的输入,将结果对reuseport套接字数量取模,得到一个索引,该索引指示的数组位置对应的套接字便是工作套接字。
Q5:那么会不会第一个数据包由套接字m处理,后续来的数据包由套接字n处理呢?
A5:这个问题其实很容易,仔细看一下算法就会发现,只要这些数据包属于同一个流(同一个五元组),那么它每次HASH的结果将会得到同一个索引,因此处理它的套接字始终是同一个!
Q6:我怎么觉得有点玄呢?【这最后一个问题是我在一个同事的启发下自问自答的...】
A6:确实玄!TCP自己会保持连接,我们暂且不谈。对于UDP而言,比如一个事务中需要交互4个数据包,第一个数据包的元组HASH结果索引到了线程1的套接字的问题,它理所当然被线程1处理,在第二个数据包到达之前,线程1挂了,那么该线程的套接字的位置将会被别的线程,比如线程2的套接字取代!在第二个数据包到达的时候,将会由线程2的套接字来处理之,然而线程2并不知道线程1保存的关于此连接的事务状态...
关于REUSEPORT的实现
以上基本就是关于reuseport的问答,其实还可以引申出更多的有趣的问题和答案,强烈建议这个作为面试题存在。我们来看下Q6/A6,这个问题确实存在,但是却不是什么大问题,这个是和实现相关的,所以并不是reuseport机制本身的问题。我们完全可以用数组代替链表,并且维持数组的大小,即使线程n挂了,它的套接字所在的位置并不被已经存在的套接字占据,而必须是被新建的替补线程(毕竟线程n已经挂了,要新建一个补充)的套接字占据,这样就能解决问题,所需的仅仅是任何线程在挂之前把状态信息序列化,然后在新线程启动的时候重新反序列化信息即可。
到此为止,我没有提及任何关于Linux 4.6内核对TCP reuseport优化的任何信息,典型的标题党!
然而,以上几乎就是全部信息,如果说还有别的,那就只能贴代码了。事实上,在Linux 4.6(针对TCP)以及Linux 4.5(针对UDP)的优化之前,我上述的Answer是不准确的,在4.5之前,Linux内核中关于reuseport的实现并非我想象的那样,然而为了解释概念和机制,我不得不用上述更加容易理解的方式去阐述,原理是一回事,实现又是一回事,请原谅我一直以来针对原理的阐述与Linux实现并不相符。
可想而知,4.5/4.6的所谓reuseport的优化,它仅仅是一种更加自然的实现方式罢了,相反,之前的实现反而并不自然!回忆三年来,有多少人问过我关于reuseport的事情,其中也不乏几位面试官,如果被进一步追问“Q:你确定Linux就是这么实现的吗?”那么我一定回答:“不!不是这么实现的,Linux的实现方法很垃圾!”,然后就会听到我滔滔不绝的阐释大量的形而上的东西,最终在一种不那么缓和的气氛中终止掉对话。
总结一下吧,事实上Linux 4.5/4.6所谓的对reuseport的优化主要体现在查询速度上,在优化前,不得不在HASH冲突链表上遍历所有的套接字之后才能知道到底取哪个(基于一种冒泡的score打分机制,不完成一轮冒泡遍历,不能确定谁的score最高),之所以如此低效是因为内核将reuseport的所有套接字和其它套接字混合在了一起,查找是平坦的,正常的做法应该是将它们分为一个组,进行分层查找,先找到这个组(这个很容易),然后再在组中找具体的套接字。Linux 4.5针对UDP做了上述优化,而Linux 4.6则将这个优化引入到了TCP。
设想系统中一共有10000个套接字被HASH到同一个冲突链表,其中9950个是reuseport的同一组套接字,如果按照老的算法,需要遍历10000个套接字,如果使用基于分组的算法,最多只需要遍历51个套接字即可,找到那个组之后,一步HASH就可以找到目标套接字的索引!
Linux 4.5之前的reuseport查找实现(4.3内核)
以下是未优化前的Linux 4.3内核的实现,可见是多么地不直观。它采用了遍历HASH冲突链表的方式进行reuseport套接字的精确定位: result = NULL; badness = 0; udp_portaddr_for_each_entry_rcu(sk, node, &hslot2->head) { score = compute_score2(sk, net, saddr, sport, daddr, hnum, dif); if (score > badness) { // 冒泡排序 // 找到了更加合适的socket,需要重新hash result = sk; badness = score; reuseport = sk->sk_reuseport; if (reuseport) { hash = udp_ehashfn(net, daddr, hnum, saddr, sport); matches = 1; } } else if (score == badness && reuseport) { // reuseport套接字散列定位 // 找到了同样reuseport的socket,进行定位 matches++; if (reciprocal_scale(hash, matches) == 0) result = sk; hash = next_pseudo_random32(hash); } }之所以要遍历是因为所有的reuseport套接字和其它的套接字都被平坦地插入到同一个表中,事先并不知道有多少组reuseport套接字以及每一组中有多少个套接字,比如下列例子:
reuseport group1-0.0.0.0:1234(sk1,sk2,sk3,sk4)
reuseport group2-1.1.1.1:1234(sk5,sk6,sk7)
other socket(sk8,sk9,sk10,sk11)
假设它们均被HASH到同一个位置,那么可能的顺序如下:
sk10-sk2-sk3-sk8-sk5-sk7-...
虽然sk2就已经匹配了,然而后面还有更精确的sk5,这就意味着必须把11个套接字全部遍历完后才知道谁会冒泡到最上面。
Linux 4.5(针对UDP)/4.6(针对TCP)的reuseport查找实现
我们来看看在4.5和4.6内核中对于reuseport的查找增加了一些什么神奇的新东西: result = NULL; badness = 0; udp_portaddr_for_each_entry_rcu(sk, node, &hslot2->head) { score = compute_score2(sk, net, saddr, sport, daddr, hnum, dif); if (score > badness) { // 在reuseport情形下,意味着找到了更加合适的socket组,需要重新hash result = sk; badness = score; reuseport = sk->sk_reuseport; if (reuseport) { hash = udp_ehashfn(net, daddr, hnum, saddr, sport); if (select_ok) { struct sock *sk2; // 找到了一个组,接着进行组内hash。 sk2 = reuseport_select_sock(sk, hash, skb, sizeof(struct udphdr)); if (sk2) { result = sk2; select_ok = false; goto found; } } matches = 1; } } else if (score == badness && reuseport) { // 这个else if分支的期待是,在分层查找不适用的时候,寻找更加匹配的reuseport组,注意4.5/4.6以后直接寻找的是一个reuseport组。 // 在某种意义上,这回退到了4.5之前的算法。 matches++; if (reciprocal_scale(hash, matches) == 0) result = sk; hash = next_pseudo_random32(hash); } }我们着重看一下reuseport_select_sock,这个函数是第二层组内查找的关键,其实不应该叫做查找,而应该叫做定位更加合适:
struct sock *reuseport_select_sock(struct sock *sk, u32 hash, struct sk_buff *skb, int hdr_len){ ... prog = rcu_dereference(reuse->prog); socks = READ_ONCE(reuse->num_socks); if (likely(socks)) { /* paired with smp_wmb() in reuseport_add_sock() */ smp_rmb(); if (prog && skb) // 可以用BPF来从用户态注入自己的定位逻辑,更好实现基于策略的负载均衡 sk2 = run_bpf(reuse, socks, prog, skb, hdr_len); else // reciprocal_scale简单地将结果限制在了[0,socks)这个区间内 sk2 = reuse->socks[reciprocal_scale(hash, socks)]; } ...}也不是那么神奇,不是吗?基本上在Q&A中都已经涵盖了。
我自己的reuseport查找实现
当年看到了google的这个idea之后,Linux内核还没有内置这个实现,我当时正在基于2.6.32内核搞一个关于OpenVPN的多处理优化,而且使用的是UDP,在亲历了折腾UDP多进程令人绝望的失败后,我移植了google的reuseport补丁,然而它的实现更加令人绝望,多么奇妙且简单(奇妙的东西一定要简单!)的一个idea,怎么可能实现成了这个样子(事实上这个样子一直持续到了4.5版本的内核)??因为我可以确定系统中不会有任何其它的reuseport套接字,且我可以确定设备的CPU个数是16个,因此定义数组如下:
#define MAX 18struct sock *reusesk[MAX]; result = NULL; badness = 0; udp_portaddr_for_each_entry_rcu(sk, node, &hslot2->head) { score = compute_score2(sk, net, saddr, sport, daddr, hnum, dif); if (score > badness) { result = sk; badness = score; reuseport = sk->sk_reuseport; if (reuseport) { hash = inet_ehashfn(net, daddr, hnum, saddr, htons(sport));#ifdef EXTENSION // 直接取索引指示的套接字 result = reusesk[hash%MAX]; // 如果只有一组reuseport的套接字,则直接返回,否则回退到原始逻辑 if (num_reuse == 1) break;#endif matches = 1; } } else if (score == badness && reuseport) { matches++; if (((u64)hash * matches) >> 32 == 0) result = sk; hash = next_pseudo_random32(hash); } }Q7&A7,Q8&A8
最后一个问题Q7:有没有什么统一的方法可以应对reuseport套接字的新增和删除呢?比如新建一个工作负载线程,一个工作线程挂掉这种动态行为。
A7:有的。那就是“一致性HASH”算法。
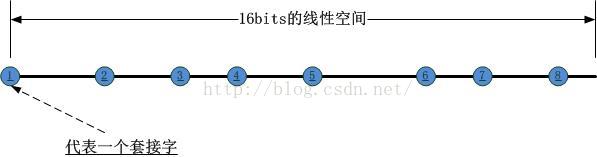
首先,我们可以将一个reuseport套接字组中所有的套接字按照其对应的PID以及内存地址之类的唯一标识,HASH到以下16bits的线性空间中(其中第一个套接字占据端点位置),如下图所示:
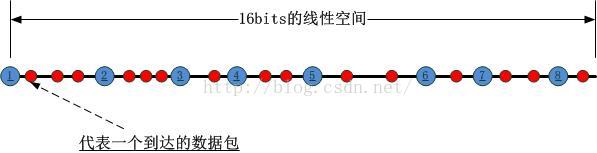
这样N个socket就将该线性空间分割成了N个区间,我们把这个HASH的过程称为第一类HASH!接下来,当一个数据包到达时,如何将其对应到某一个套接字呢?此时要进行第二类hash运算,这个运算的对象是数据包携带的源IP/源端口对,HASH的结果对应到前述16bits的线性空间中,如下图所示:
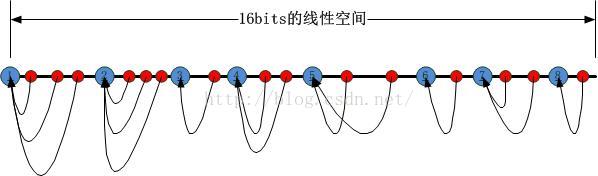
理解了原理之后,我们看一下怎么实现这个mini一致性HASH。真正的一致性HASH实现起来太重了,网上也有很多的资料可查,我这里只是给出一个思路,谈不上最优。根据上图,我们可以看到,归根结底需要一个“区间查找”,也就是说最终需要做的就是“判定第二类HASH结果落在了由第一类HASH结果分割的哪个区间内”,因此在直观上,可以采用的就是二叉树区间匹配,在此,我把上述的区间分割整理成一颗二叉树:
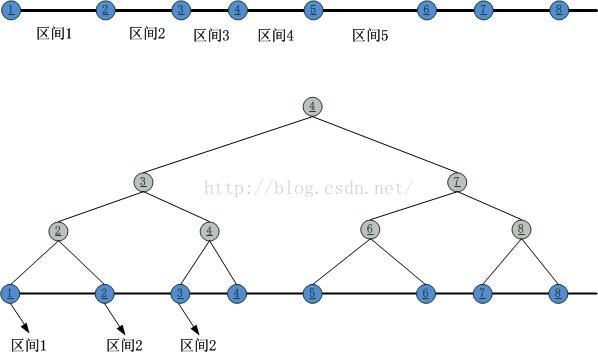
日耳曼向左,罗马向右!接下来就可以在这个二叉树上进行二分查找了。
Q8:在reuseport的查找处理上,TCP和UDP的区别是什么?
A8:TCP的每一条连接均可以由完全的五元组信息自行维护一个唯一的标识,只需要按照唯一的五元组信息就可以找出一个TCP连接,但是对于Listen状态的TCP套接字就不同了,一个来自客户端的SYN到达时,五元组信息尚未确立,此时正是需要找出是reuseport套接字组中到底哪个套接字来处理这个SYN的时候。待这个套接字确定以后,就可以和发送SYN的客户端建立唯一的五元组标识了,因此对于TCP而言,只有Listen状态的套接字需要reuseport机制的支持。对于UDP而言,则所有的套接字均需要reuseport机制的支持,因为UDP不会维护任何连接信息,也就是说,协议栈不会记录哪个客户端曾经来过或者正在与之通信,没有这些信息,因此对于每一个数据包,均需要reuseport的查找逻辑来为其对应一个处理它的套接字。
你知道每天最令人悲哀的事情是什么吗?那就是重复着一遍又一遍每天都在重复的话。
给我老师的人工智能教程打call!http://blog.csdn.net/jiangjunshow

这篇关于Linux 4 6内核对TCP REUSEPORT的优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





