本文主要是介绍LLMs之ROME:《Locating and Editing Factual Associations in GPT》—翻译与解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LLMs之ROME:《Locating and Editing Factual Associations in GPT》—翻译与解读
目录
一、《Locating and Editing Factual Associations in GPT》—翻译与解读
Abstract
1 Introduction引言
5 Conclusion结论
6 Ethical Considerations道德考虑
二、《Locating and Editing Factual Associations in GPT》博客文章—翻译与解读
1、语言模型内的事实存储在哪里?:模型权重、语境
2、为什么要定位事实?:可解释性+修正错误知识
3、我们发现了什么?:事实关联可以沿着三个维度局部化、通过对单个 MLP 模块进行小的秩一改变可以改变单个事实关联
4、如何定位事实检索:因果跟踪,通过多次干扰+恢复
5、如何编辑事实存储:采用ROME(秩一模型编辑的方法)
6、如何区分知道事实和陈述事实:特定性(不会改变其它事实—每个事实是独立的)和泛化性(对变化有鲁棒性—触类旁通)
三、ROME的GitHub实现
T1、Rank-One Model Editing (ROME)实现ROME算法
(1)、安装
(2)、因果追踪
(3)、Rank-One模型编辑(ROME)
(4)、评估
4.1)、运行完整评估套件
4.2)、集成新的编辑方法
T2、FastEdit实现ROME算法
LLMs:FastEdit(一款可在10秒内编辑和更新大型语言模型事实知识的高效工具)的简介、安装、使用方法之详细攻略
一、《Locating and Editing Factual Associations in GPT》—翻译与解读
| 地址 | 论文:《Locating and Editing Factual Associations in GPT》https://arxiv.org/abs/2202.05262 博客文章:Locating and Editing Factual Associations in GPT 解读文章:https://yunyaniu.blog.csdn.net/article/details/130312546 GitHub官网:https://github.com/kmeng01/rome GitHub官网:GitHub - hiyouga/FastEdit: 🩹Editing large language models within 10 seconds⚡ |
| 时间 | 2022年2月10日 最新版本,2023年1月13日 |
| 作者 | Kevin Meng*1, David Bau*2, Alex Andonian1, Yonatan Belinkov3 1MIT CSAIL, 2Northeastern University, 3Technion - IIT; *Equal Contribution |
Abstract
| We analyze the storage and recall of factual associations in autoregressive transformer language models, finding evidence that these associations correspond to localized, directly-editable computations. We first develop a causal intervention for identifying neuron activations that are decisive in a model’s factual predictions. This reveals a distinct set of steps in middle-layer feed-forward modules that me-diate factual predictions while processing subject tokens. To test our hypothesis that these computations correspond to factual association recall, we modify feed-forward weights to update specific factual associations using Rank-One Model Editing (ROME). We find that ROME is effective on a standard zero-shot relation extraction (zsRE) model-editing task. We also evaluate ROME on a new dataset of difficult counterfactual assertions, on which it simultaneously maintains both specificity and generalization, whereas other methods sacrifice one or another. Our results confirm an important role for mid-layer feed-forward modules in storing fac-tual associations and suggest that direct manipulation of computational mechanisms may be a feasible approach for model editing. The code, dataset, visualizations, and an interactive demo notebook are available at https://rome.baulab.info/. | 我们分析了自回归transformer语言模型中事实关联的存储和检索,发现这些关联与局部化的、可直接编辑的计算相对应。我们首先开发了一种因果干预方法,用于识别模型在事实预测中决定性的神经元激活。这揭示了在处理主体标记时介导事实预测的中间层前馈模块的一组明确步骤。 为了测试我们的假设,即这些计算对应于事实关联的回忆,我们使用秩一模型编辑(ROME)修改前馈权重,以更新特定的事实关联。我们发现 ROME 在标准的零射关系抽取(zsRE)模型编辑任务上效果良好。 我们还在一个新的难以虚构的断言数据集上评估了 ROME,在这个数据集上,它同时保持了特定性和泛化性,而其他方法则牺牲了其中之一。我们的结果确认了中层前馈模块在存储事实关联方面的重要作用,并暗示了直接操纵计算机制可能是一种可行的模型编辑方法。代码、数据集、可视化和交互式演示笔记本可在https://rome.baulab.info/上获得。 |
1 Introduction引言
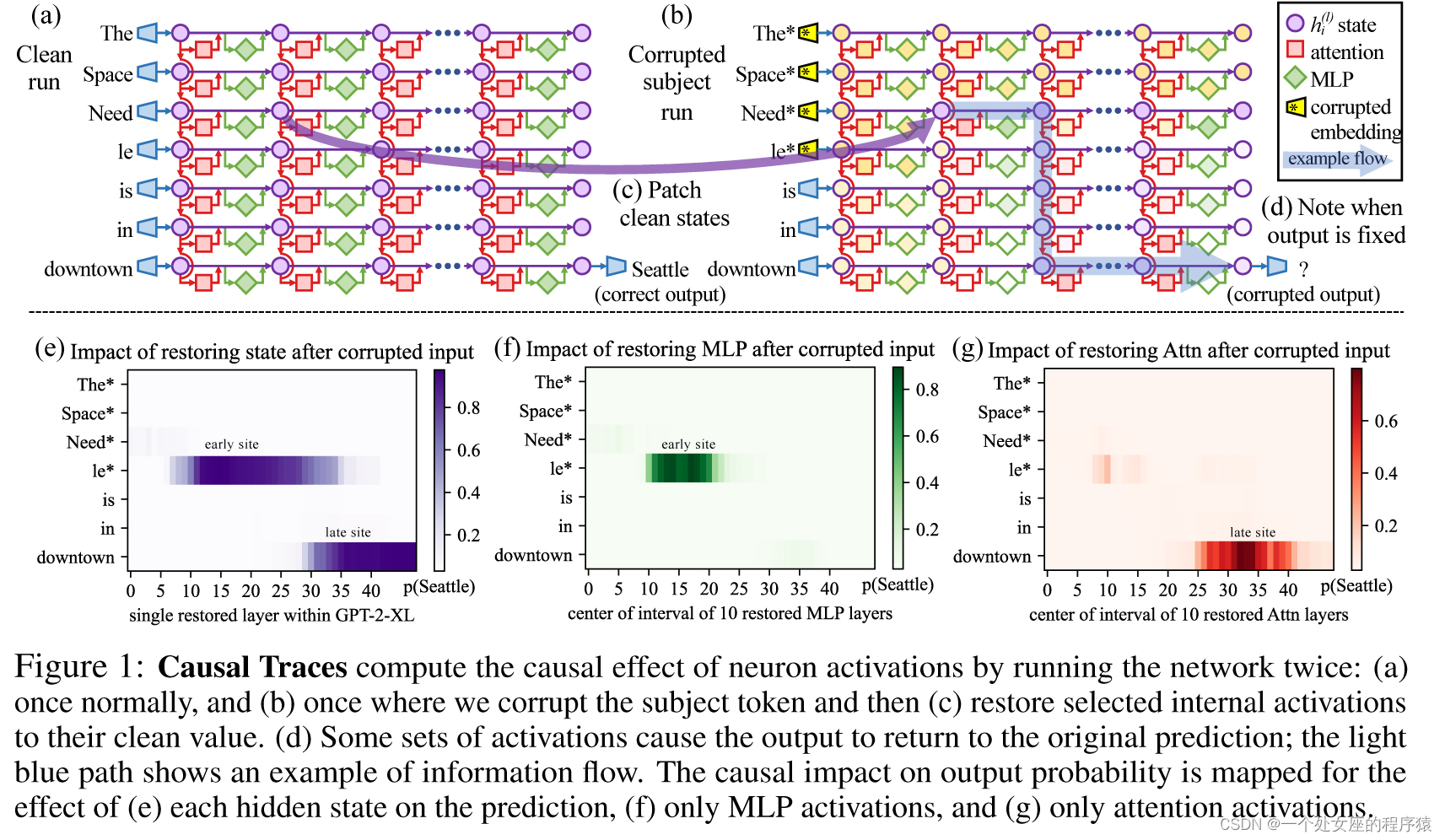
| Where does a large language model store its facts? In this paper, we report evidence that factual associations in GPT correspond to a localized computation that can be directly edited. Large language models can predict factual statements about the world (Petroni et al., 2019; Jiang et al., 2020; Roberts et al., 2020). For example, given the prefix “The Space Needle is located in the city of,” GPT will reliably predict the true answer: “Seattle” (Figure 1a). Factual knowledge has been observed to emerge in both autoregressive GPT models (Radford et al., 2019; Brown et al., 2020) and masked BERT models (Devlin et al., 2019). In this paper, we investigate how such factual associations are stored within GPT-like autoregressive transformer models. Although many of the largest neural networks in use today are autoregressive, the way that they store knowledge remains under-explored. Some research has been done for masked models (Petroni et al., 2019; Jiang et al., 2020; Elazar et al., 2021a; Geva et al., 2021; Dai et al., 2022; De Cao et al., 2021), but GPT has architectural differences such as unidirectional attention and generation capabilities that provide an opportunity for new insights. | 一个大型语言模型存储其事实的地方在哪里?在本文中,我们报道了证据表明GPT中的事实关联与局部化的计算相对应,这些计算可以直接进行编辑。大型语言模型可以预测关于世界的事实陈述(Petroni等,2019;Jiang等,2020;Roberts等,2020)。例如,给定前缀“Space Needle位于城市”,GPT将可靠地预测出真实答案:“西雅图”(图1a)。已观察到事实知识在自回归的GPT模型(Radford等,2019;Brown等,2020)和掩蔽的BERT模型(Devlin等,2019)中出现。 在本文中,我们研究了这种事实关联在类似GPT的自回归transformer模型内部是如何存储的。尽管当今许多最大的神经网络都是自回归的,但它们存储知识的方式仍未被充分探索。一些研究已经针对掩蔽模型进行了研究(Petroni等,2019;Jiang等,2020;Elazar等,2021a;Geva等,2021;Dai等,2022;De Cao等,2021),但是GPT具有单向注意力和生成能力等架构差异,这为新的见解提供了机会。 |
| We use two approaches. First, we trace the causal effects of hidden state activations within GPT using causal mediation analysis (Pearl, 2001; Vig et al., 2020b) to identify the specific modules that mediate recall of a fact about a subject (Figure 1). Our analysis reveals that feedforward MLPs at a range of middle layers are decisive when processing the last token of the subject name (Figures 1b,2b,3). Second, we test this finding in model weights by introducing a Rank-One Model Editing method (ROME) to alter the parameters that determine a feedfoward layer’s behavior at the decisive token. Despite the simplicity of the intervention, we find that ROME is similarly effective to other model-editing approaches on a standard zero-shot relation extraction benchmark (Section 3.2). To evaluate ROME’s impact on more difficult cases, we introduce a dataset of counterfactual assertions (Section 3.3) that would not have been observed in pretraining. Our evaluations (Section 3.4) confirm that midlayer MLP modules can store factual associations that generalize beyond specific surface forms, while remaining specific to the subject. Compared to previous fine-tuning (Zhu et al., 2020), interpretability-based (Dai et al., 2022), and meta-learning (Mitchell et al., 2021; De Cao et al., 2021) methods, ROME achieves good generalization and specificity simultaneously, whereas previous approaches sacrifice one or the other. | 我们采用两种方法。首先,我们使用因果中介分析(Pearl,2001;Vig等,2020b)来追踪GPT内部隐藏状态激活的因果效应,以识别中介检索关于主体的事实的特定模块(图1)。我们的分析揭示了在处理主体名称的最后一个标记时,中间层的前馈MLP至关重要(图1b、2b、3)。 其次,我们在模型权重中测试了这一发现,引入了一种名为Rank-One模型编辑(ROME)的方法,以改变决定性标记处的前馈层行为的参数。 尽管干预的方法很简单,但我们发现ROME在标准的零射关系抽取基准测试上与其他模型编辑方法同样有效(第3.2节)。 为了评估ROME对更困难情况的影响,我们引入了一个虚构断言数据集(第3.3节),这些断言在预训练中不会被观察到。我们的评估(第3.4节)确认了中层MLP模块可以存储能够超越特定表面形式的事实关联,同时保持对主体的特定性。与先前的微调(Zhu等,2020)、基于解释的方法(Dai等,2022)和元学习(Mitchell等,2021;De Cao等,2021)方法相比,ROME实现了良好的泛化性和特定性,而以前的方法则牺牲了其中之一。 |
5 Conclusion结论
| We have clarified information flow during knowledge recall in autoregressive transformers, and we have exploited this understanding to develop a simple, principled model editor called ROME. Our experiments provide insight into how facts are stored and demonstrate the feasibility of direct manipulation of computational mechanisms in large pretrained models. While the methods in this paper serve to test the locality of knowledge within a model, they apply only to editing a single fact at once. Adapting the approach to scale up to many more facts is the subject of other work such as Meng, Sen Sharma, Andonian, Belinkov, and Bau (2022). Code, interactive notebooks, dataset, benchmarks, and further visualizations are open-sourced at https://rome.baulab.info. | 我们已经阐明了自回归transformer中知识回忆的信息流,并利用这一理解开发了一个简单而有原则的模型编辑器——ROME。我们的实验揭示了事实如何存储,并展示了在大型预训练模型中直接操纵计算机制的可行性。尽管本文中的方法用于测试模型内部知识的局部性,但它们仅适用于一次编辑单个事实。将该方法扩展到更多事实的规模是其他工作的主题,例如Meng、Sen Sharma、Andonian、Belinkov和Bau(2022)。 代码、交互式笔记本、数据集、基准测试和更多可视化内容在https://rome.baulab.info上开源。 |
6 Ethical Considerations道德考虑
| By explaining large autoregressive transformer language models’ internal organization and developing a fast method for modifying stored knowledge, our work potentially improves the transparency of these systems and reduces the energy consumed to correct their errors. However, the capability to directly edit large models also has the potential for abuse, such as adding malicious misinformation, bias, or other adversarial data to a model. Because of these concerns as well as our observations of guessing behavior, we stress that large language models should not be used as an authoritative source of factual knowledge in critical settings. | 通过解释大型自回归transformer语言模型的内部结构并开发快速修改存储知识的方法,我们的工作有可能提高这些系统的透明度,减少修正其错误所消耗的能量。然而,直接编辑大型模型的能力也存在滥用的潜在可能性,例如向模型中添加恶意的错误信息、偏见或其他对抗性数据。鉴于这些担忧以及我们对猜测行为的观察,我们强调大型语言模型不应该被用作关键环境中事实知识的权威来源。 |
二、《Locating and Editing Factual Associations in GPT》博客文章—翻译与解读
1、语言模型内的事实存储在哪里?:模型权重、语境

| Where are the Facts Inside a Language Model? Knowing differs from saying: uttering words by rote is different from knowing a fact, because knowledge of a fact generalizes across contexts. In this project, we show that factual knowledge within GPT also corresponds to a localized computation that can be directly edited. For example, we can make a small change to a small set of the weights of GPT-J to teach it the counterfactual "Eiffel Tower is located in the city of Rome." Rather than merely regurgitating the new sentence, it will generalize that specific counterfactual knowledge and apply it in very different linguistic contexts. | 知道不同于陈述:机械地重复词句不同于掌握事实,因为事实的知识可以在不同语境中推广。在这个项目中,我们展示了 GPT 中的事实知识也对应着一种局部化的计算,可以直接进行编辑。例如,我们可以微调 GPT-J 的一小部分权重,教它学习虚构的"埃菲尔铁塔位于罗马城"。它不仅仅是简单地复述新句子,而是会将特定的虚构知识推广并应用于非常不同的语境中。 |
2、为什么要定位事实?:可解释性+修正错误知识
| Why Locate Facts? We are interested how and where a model stores its factual associations, for two reasons: >> To understand huge opaque neural networks. The internal computations of large language models are obscure. Clarifying the processing of facts is one step in understanding massive transformer networks. >> Fixing mistakes. Models are often incorrect, biased, or private, and we would like to develop methods that will enable debugging and fixing of specific factual errors. | 我们有两个原因对模型存储事实关联的方式感兴趣: >> 理解庞大的不透明神经网络。大型语言模型的内部计算是晦涩难懂的。澄清事实的处理是理解大规模Transformer网络的一步。 >>修正错误。模型通常是不正确的、 带有偏见的或私密的,我们希望开发方法来调试和修复特定的事实错误。 |
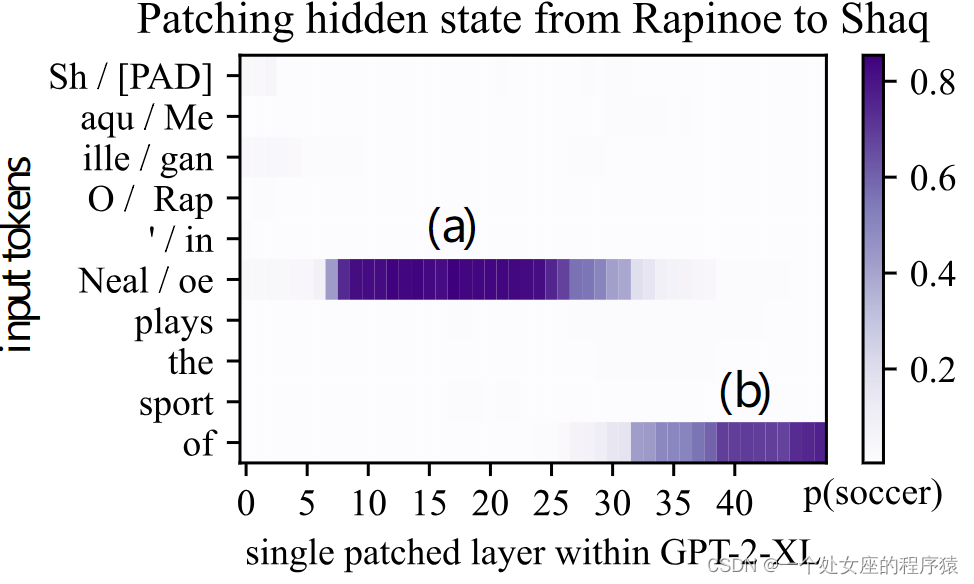
| The facts we study take the form of knowledge tuples t = (s, r, o), where s and o are subject and object entities, respectively, and r is the relation connecting the two. For example, (s = Megan Rapinoe, r = plays sport professionally, o = soccer) indicates that Rapinoe plays soccer for a living. Each variable represents an entity or relation that can be found in a knowledge graph, and that can be written as a natural language string. To query GPT for knowledge of a fact, we express (s, r) as a text prompt (by expanding a template from the CounterFact data set), and check whether the generated continuation matches o. | 我们研究的事实采用了知识元组 t = (s, r, o) 的形式,其中 s 和 o 分别是主体和客体实体,r 是连接两者的关系。例如,(s = Megan Rapinoe, r = plays sport professionally, o = soccer) 表示 Rapinoe 以职业运动员的身份踢足球。 每个变量代表一个在知识图中可以找到的实体或关系,可以用自然语言字符串来表示。 要查询 GPT 是否具有某项事实的知识,我们将 (s, r) 表达为文本提示(通过从CounterFact数据集扩展模板),并检查生成的延续是否与o 匹配。 |
3、我们发现了什么?:事实关联可以沿着三个维度局部化、通过对单个 MLP 模块进行小的秩一改变可以改变单个事实关联


| What Did We Find? In GPT-style transformer models, we discovered two things: | 在 GPT 风格的Transformer模型中,我们发现了两件事情: |
| 1. Factual associations can be localized along three dimensions, to (1) MLP module parameters (2) at a range of middle layers and (3) specifically during processing of the last token of the subject. A causal trace of a factual statement in GPT The causal trace above reveals a small number of states that contain information that can flip the model from one factual prediction to another. Our studies use such causal traces and find evidence that knowledge retrieval occurs in MLP modules at the early site (at (a) in the figure); then attention mechanisms at the late site (at (b) in the figure) bring the information to the end of the computation where the specific word can be predicted. 2. Individual factual associations can be changed by making small rank-one changes in a single MLP module. We can distinguish between changes in knowledge versus superficial changes in language by measuring generalization to other wordings of the same fact. An example of editing a fact in GPT using the ROME method. The example above shows that changing the model's processing of a single statement about the Eiffel Tower, if done by changing selected parameters in the right way, will result in expressing a change in knowledge in a variety of nontrivial contexts. | 1、事实关联可以沿着三个维度局部化,分别是 (1) MLP 模块参数 (2) 在一系列中间层和 (3) 特别是在处理主体的最后一个标记时。 上述GPT中事实陈述的因果跟踪 上述的因果跟踪揭示了一小部分状态,其中包含的信息可以将模型从一个事实预测转变为另一个事实预测。我们的研究使用了这种因果跟踪,并找到了证据表明知识检索发生在 MLP 模块的早期位置(图中的 (a) 处);然后在处理的最后位置,注意机制将信息带到计算的末尾,可以预测出具体的词语。 2、通过对单个 MLP 模块进行小的秩一改变,可以改变单个事实关联。我们可以通过测量对同一事实不同措辞的泛化来区分知识的变化与语言的表面变化。 使用 ROME 方法编辑 GPT 中的事实的示例。 上面的示例显示,通过以正确的方式更改所选参数,可以改变模型对关于埃菲尔铁塔的单个陈述的处理,从而在多种复杂的上下文中表达知识变化。 |
| At (a) in in the figure, a single direct statement of a counterfactual is posed, and it is used to compute a rank-one parameter change in a single MLP module. Despite the simplicity of the change, results shown at (b) show that for a more complex prompt about travel from Berlin, the model treats the Eiffel tower as if it is in Rome; similarly in (c) when asked about nearby sites, the model suggests places in Rome before explicitly mentioning Rome. Changes in predictions in such different contexts is evidence that change generalizes: the model has not merely learned to parrot the exact sequence of words in the counterfactual, but it also applies the new knowledge in sentences that are very different from the original example. | 在图中的 (a) 处,提出了一个单一的事实虚构陈述,并且它用于计算单个 MLP 模块中的秩一参数变化。尽管变化的简单性,图中的 (b) 处显示了对于关于从柏林旅行的更复杂的提示,模型会将埃菲尔铁塔视为在罗马;类似地,在 (c) 处当被问及附近的景点时,模型会在明确提到罗马之前,建议在罗马的地方。在这么不同的语境中进行预测的变化是变化泛化的证据:模型不仅仅学会了机械复述虚构陈述中的确切单词序列,还将新的知识应用于与原始示例非常不同的句子中。 |
4、如何定位事实检索:因果跟踪,通过多次干扰+恢复

| How to Locate Factual Retrieval To identify decisive computations, we introduce a method called Causal Tracing. By isolating the causal effect of individual states within the network while processing a factual statement, we can trace the path followed by information through the network. An animation demonstrating the Causal Tracing method. Causal traces work by running a network multiple times, introducing corruptions to frustrate the computation, and then restoring individual states in order to identify the information that restores the results. Tracing can be used to test any individual state or combinations of states. We use carefully-designed traces to identify a specific small set of MLP module computations that mediate retrieval of factual associations. Then we check this finding by asking: can the MLP module computations be altered to edit a model's belief in a specific fact? | 为了识别决定性的计算,我们引入了一种叫做因果跟踪的方法。通过在处理事实陈述时隔离网络中各个状态的因果效应,我们可以追踪信息通过网络的路径。 演示因果跟踪方法的动画。 因果跟踪通过多次运行网络,引入干扰来阻碍计算,然后恢复个别状态,以识别恢复结果的信息。跟踪可用于测试任何单个状态或状态的组合。我们使用精心设计的跟踪来识别特定一小部分 MLP 模块计算,这些计算在中介检索事实关联时起作用。 然后,我们通过问:是否可以更改 MLP 模块计算以编辑模型对特定事实的信念? |
5、如何编辑事实存储:采用ROME(秩一模型编辑的方法)
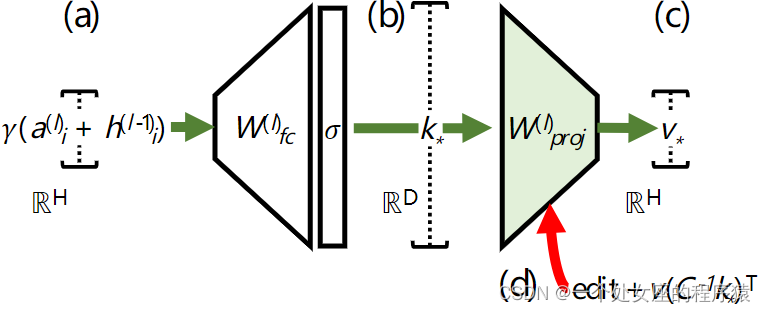
| How to Edit Factual Storage To modify individual facts within a GPT model, we introduce a method called ROME, or Rank-One Model Editing. It treats an MLP module as a simple key-value store: for example, if the key encodes a subject and the value encodes knowledge about the subject, then the MLP can recall the association by retrieving the value corresponding to the key. ROME uses a rank-one modification of the MLP weights to directly write in a new key-value pair. Diagram of an MLP module The figure above illustrates a single MLP module within a transformer. The D-dimensional vector at (b) acts as the key that represents a subject to know about, and the H-dimensional output at (c) acts at the value that encodes learned properties about the subject. ROME inserts new association by making a rank-one change to the matrix (d) that maps from keys to values. Note that ROME assumes a linear view of memory within a neural network rather than an individual-neuron view. This linear perspective sees individual memories as rank-one slices of parameter space. Experiments confirm this view: when we do a rank-one update to an MLP module in the computational center identified by causal tracing, we find that associations of individual facts can be updated in a way that is both specific and generalized. | 要在 GPT 模型中修改单个事实,我们引入了一种叫做 ROME 或秩一模型编辑的方法。它将 MLP 模块视为一个简单的键值存储:例如,如果键编码了一个主体,而值编码了关于该主体的知识,那么 MLP 可以通过检索与键对应的值来回忆关联。ROME 使用 MLP 权重的秩一修改来直接写入新的键值对。 MLP 模块的图示 上图示出了transformer内的单个 MLP 模块。图中的 (b) 处的 D 维向量作为表示要了解的主体的键,而 (c) 处的 H 维输出作为编码有关主体的学习属性的值。ROME 通过对从键到值的映射 (d) 进行秩一变化来插入新的关联。 请注意,ROME 假设神经网络内存的线性视图,而不是单个神经元的视图。这种线性视角将单个记忆视为参数空间的秩一切片。实验证实了这种观点:当我们对因果跟踪确定的计算中的 MLP 模块进行秩一更新时,我们发现可以以特定和广义的方式更新单个事实的关联。 |
6、如何区分知道事实和陈述事实:特定性(不会改变其它事实—每个事实是独立的)和泛化性(对变化有鲁棒性—触类旁通)
| How to Distinguish Knowing a Fact from Saying a Fact Knowing differs from saying. A variety of fine-tuning methods can cause a language model to parrot a specific new sentence, but training a model to adjust its knowledge of a fact is different from merely teaching it to regurgitate a particular sequence of words. We can tell the difference between knowing and saying by measuring two hallmarks of knowledge: specificity and generalization. Specificity means that when your knowledge of a fact changes, it doesn't change other facts. For example, after learning that the Eiffel Tower is in Rome, you shouldn't also think that every other tourist attraction is also in Rome. Generalization means that your knowledge of a fact is robust to changes in wording and context. After learning the Eiffel Tower is in Rome, then you should also know that visiting it will require travel to Rome. | 如何区分知道事实和陈述事实 知道与陈述不同。各种微调方法可以导致语言模型机械地模仿特定的新句子,但训练模型调整其对事实的知识与仅教它机械地复述特定的单词序列是不同的。 我们可以通过衡量知识的两个标志来区分知道和陈述:特定性和泛化性。 特定性意味着当您对事实的知识发生变化时,不会改变其他事实。例如,在了解埃菲尔铁塔在罗马之后,您不应该认为每个其他旅游景点也在罗马。 泛化性意味着您对事实的知识对措辞和上下文的变化具有鲁棒性。在了解埃菲尔铁塔在罗马后,您还应该知道参观它将需要前往罗马。 |
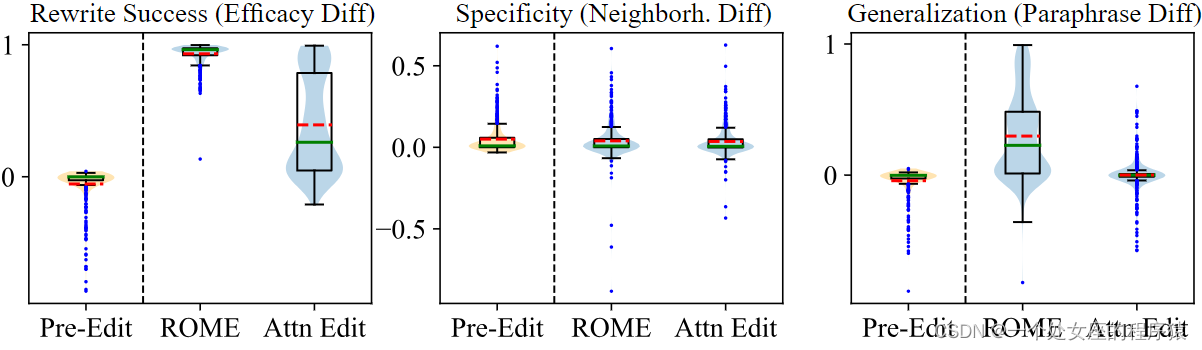
| Our new dataset CounterFact includes thousands of counterfactuals along with text that allows quantitative testing of specificity and generalization when learning a counterfactual. Quantitative results distinguishing knowing from saying. Above are the results of an experiment that uses CounterFact to confirm the distinction between knowing and saying parameters in GPT-2 XL. ROME, which edits the early causal site (a), achieves excellent efficacy (measured by performance on the counterfactual prompt itself), specificity (performance on neighborhood subjects not supposed to change), and generalization (performance on paraphrases). By contrast, if we modify the attention mechanism at the later site (b), the model achieves fair efficacy and specificity but completely fails to generalize. | 我们的新数据集 CounterFact 包括数千个虚构事实,以及允许在学习虚构事实时进行特定性和泛化性的定量测试的文本。 上面是一项使用 CounterFact 进行的实验结果,以确认在 GPT-2 XL 中区分知道和陈述参数的区别。编辑早期因果站点(a)的 ROME 实现了出色的功效(通过对虚构提示本身的性能进行测量),特定性(对不应改变的邻近主体的性能)和泛化性(对释义的性能)。相比之下,如果我们修改稍后站点(b)的注意机制,模型会取得公平的功效和特定性,但完全无法泛化。 |
三、ROME的GitHub实现
GitHub官网:https://github.com/kmeng01/rome
T1、Rank-One Model Editing (ROME)实现ROME算法
ROME代码库提供了在自回归变换器(仅支持GPU)上实现Rank-One模型编辑(ROME)的代码。我们目前支持OpenAI的GPT-2 XL(1.5B)和EleutherAI的GPT-J(6B)。预计EleutherAI将很快发布一个类似20B的GPT模型;我们希望尽快支持它。
(1)、安装
我们建议使用conda来管理Python、CUDA和PyTorch相关的依赖项,使用pip来管理其他所有依赖项。要开始,请简单地安装conda,然后运行:
./scripts/setup_conda.sh关于跨平台兼容性的说明:目前只支持使用PyTorch后端编辑自回归HuggingFace模型的方法。我们正在开发一组通用的方法(可以在TensorFlow上使用,但不需要HuggingFace),很快就会发布。
(2)、因果追踪
notebooks/causal_trace.ipynb演示了因果追踪,可以修改它以将追踪应用于任何语句的处理过程。
(3)、Rank-One模型编辑(ROME)
notebooks/rome.ipynb演示了ROME。API很简单;只需要简单地指定以下形式的重写请求:
request = {
"prompt": "{} plays the sport of",
"subject": "LeBron James",
"target_new": {
"str": "football"
}
}笔记本中包含了一些类似的例子。
(4)、评估
请参阅baselines/以获取可用基准的描述。
4.1)、运行完整评估套件
| 执行脚本 | 可以使用experiments/evaluate.py来评估baselines/中的任何方法。要开始(例如,在GPT-2 XL上使用ROME),运行: python3 -m experiments.evaluate --alg_name=ROME --model_name=gpt2-xl --hparams_fname=gpt2-xl.json |
| 查看结果 | 每次运行的结果存储在results/<method_name>/run_<run_id>中,格式如下: results/ |__ ROME/ |__ run_<run_id>/ |__ params.json |__ case_0.json |__ case_1.json |__ ... |__ case_10000.json |
| 总结 | 要总结结果,您可以使用experiments/summarize.py: python3 -m experiments.summarize --dir_name=ROME --runs=run_<run_id> 运行 python3 -m experiments.evaluate -h 或 python3 -m experiments.summarize -h 可以获取有关命令行标志的详细信息。 |
4.2)、集成新的编辑方法
| 基准测试 | 假设您有一种名为X的新方法,并且想要在CounterFact上对其进行基准测试。要将X与我们的运行程序集成: >> 将HyperParams子类化为XHyperParams,并指定所有超参数字段。参考ROMEHyperParameters以获取示例实现。 >> 在hparams/X/gpt2-xl.json中创建一个超参数文件,并指定一些默认值。参考hparams/ROME/gpt2-xl.json以获取示例。 >> 定义一个名为apply_X_to_model的函数,该函数接受多个参数并返回(i)重写后的模型和(ii)已编辑参数的原始权重值(以字典格式{weight_name: original_weight_value}表示)。参考rome/rome_main.py以获取示例。 >> 在experiments/evaluate.py中的ALG_DICT中添加X,插入一行代码:"X": (XHyperParams, apply_X_to_model)。 |
| 执行脚本 | 最后,运行主要脚本: python3 -m experiments.evaluate --alg_name=X --model_name=gpt2-xl --hparams_fname=gpt2-xl.json python3 -m experiments.summarize --dir_name=X --runs=run_<run_id> |
T2、FastEdit实现ROME算法
LLMs:FastEdit(一款可在10秒内编辑和更新大型语言模型事实知识的高效工具)的简介、安装、使用方法之详细攻略
https://yunyaniu.blog.csdn.net/article/details/131693020
这篇关于LLMs之ROME:《Locating and Editing Factual Associations in GPT》—翻译与解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








