本文主要是介绍RTC 月度小报 8 月 | RTC 大会限免进行时、Janus 作者“见面会”、Google开源了一个语音引擎...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本月亮点速览
RTC资讯:
Google开源Live Transcribe的语音引擎
Google Duo:增强弱光环境下的视频画面质量
RTC社区:
RTC 实时互联网大会报名开启
Janus 作者与你相约 RTC WebRTC Workshop
RTC Dev Meetup 上海站:WebRTC与Web端可交互PPT
Agora产品动态:
声网 Agora Python SDK 已经上线
声网一站式智能语音识别方案:内容审核,快速接入
RTC社区
RTC 2019 实时互联网大会报名开启
RTC 2019 实时互联网大会将于 10 月 24 日、25 日在北京悠唐皇冠假日酒店举行。RTC 技术不应仅属于小圈子的狂欢,而应该被更多的开发者了解、使用与探讨。所以作为每年全球最大规模的 RTC 技术布道会议,RTC 实时互联网大会不仅邀请来自全球一线团队的 RTC 技术专家分享技术实践、前沿探索,以及 RTC 与热门技术的融合趋势,还在每年都设立限时免费门票,让 RTC 技术与知识触手可及,今年也不例外。现在,限免通道现已开启,你还等什么?现在即可扫码报名。

今年除了主会以外,还将有「编解码技术」、「AI 与 RTC」、「下一代 RTC」三大技术专场,「大前端应用开发技术」、「QoE 与高并发网络架构」两场全天的峰会,以及一场「WebRTC Workshop」。今年我们已经邀请到了来自 W3C、搜狗、微软、阿里达摩院、字节跳动、Hulu、优酷、沪江 CCTalk、Bilibili、新东方、数美科技、相芯科技、声网、Meetecho、AVS、北京大学、上海交大等公司、组织机构的一线技术专家。(次序不分先后)
我们在近期已经曝光了一部分与网络架构相关议题,后续还将公布更多与 AI、编解码、实时交互、大前端开发、5G 相关的话题,敬请期待。
Janus 作者约你来 RTC WebRTC Workshop
RTC 大会作为 RTC 技术的布道会议,WebRTC 始终是我们布道推广的开源技术之一。我们历年曾邀请《WebRTC 权威指南》的作者,后来我们也将它翻译成了中文出版。在去年,我们还邀请了 Google WebRTC 的产品经理来分享 WebRTC 1.0 标准。但无奈WebRTC的编译部署、服务器部署策略、回声消除、降噪、网络抗丢包等始终是很多开发者需要翻越的几座山。
所以,今年 RTC 大会第二天,邀请到了Janus的创始人、音视频行业从业 10 余年的资深 WebRTC 技术专家,以及来自声网的音频算法工程师,开展一场 WebRTC Workshop,带着大家一起爬坡、提升。
Workshop 活动信息
活动时间:2019 年10 月 25 日全天
活动地点:北京市朝阳区悠唐皇冠假日酒店
面向人群:初级的 WebRTC 应用开发者、WebRTC 爱好者

RTC Dev Meetup 上海站:WebRTC 与 web 端可交互的 PPT
8月17日下午, GDG x RTC 开发者社区联合线下 Meetup圆满举办。有超过 180 位小伙伴报名参与了这场由 RTC 开发者社区和 GDG 社区联合主办的 Meetup。这次活动上,来自UCloud 前端资深架构师李喜庆做了《WebRTC客户端开发实践》分享,来自声网的高级WebRTC前端工程师陆禹淳带来了《Node.js+WebRTC:WebRTC的服务端应用之路》的分享,Netless PPT渲染引擎负责人张黎分享了《React实现可交互动态PowerPoint》。
我们已经将所有课程资料上传分享至 RTC 开发者社区,没能来到现场的小伙伴们可以自行获取:https://rtcdeveloper.com/t/topic/15659

Agora 产品动态
声网Agora Python SDK 上线
声网Agora 本月起正式支持 Python 语言了。我们已经将声网 Agora Python SDK 上传至 Github,开发者们可以通过它来将实时音视频与深度学习、人脸识别、声纹识别等技术结合起来,玩出更多花样了。为了便于大家理解其中的接口,我们还写了一份 Python demo,用 TensorFlow 做了一次实时地人脸识别,并已将其分享至 Github。
Python SDK: https://github.com/AgoraIO-Community/Agora-Python-SDK
声网一站式智能语音识别:内容审核,快速接入
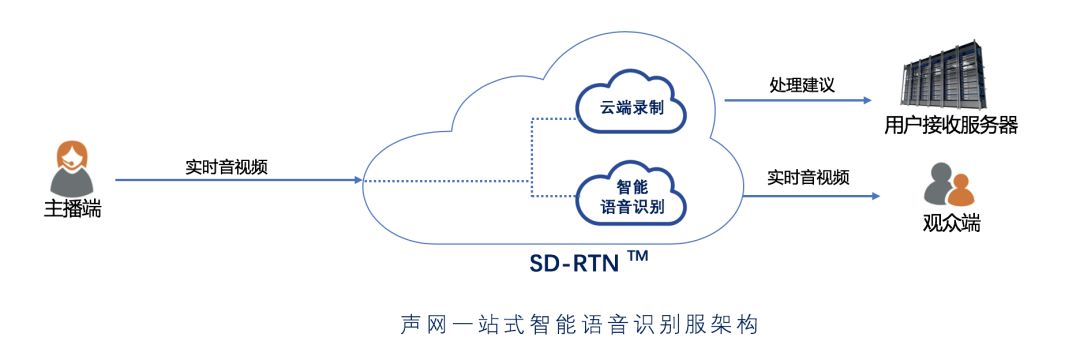
声网现已提供业界独有的一站式智能语音识别方案。如上图架构所示,开发者只需要在应用中集成声网 Agora SDK,即可让音频在 Agora SD-RTN™ 网络中实时传输的过程中完成语音内容识别与审核。我们在原有的实时语音互动直播的基础上,整合了业界 Top 3 语音识别服务。同时,基于声网的 AI 音频降噪引擎,来提高音频质量,优化语音识别效果。开发者可通过调用 RESTful API 来启用该功能,具体详见往期文章。
RTC资讯
Google开源Live Transcribe的语音引擎

还记得 Google 在今年 I/O 大会上演示的“实时转录文字”功能么?就在本月中旬,Google 将其背后的语音引擎开源了。Live Transcribe 基于深度学习算法实时将语音转换为文字字幕,不过它依赖于Cloud Speech API。而 Google 在官方博客中也表示,实时转录的质量也面对着不同地区的网络连接状态、网络丢包、延迟的挑战。简要来讲,其开源的语音引擎支持的特性包括:无限流媒体;支持70多种语言;网络环境差时,文字不会丢失(只会延迟显示);可以轻松启用和配置Opus,AMR-WB和FLAC编码等。具体,可见Github:
https://github.com/google/live-transcribe-speech-engine
Google Duo:增强弱光环境下的视频画面质量
Google Duo 近期又更新了,新增了一个“弱光”按钮。在视频通话中,如果对方处于灯光昏暗的室内,你只需要点击这个按钮,你所看到的画面光线就会明亮起来,系统会检测和重点关注聊天对象的面部信息,而不是整个视频捕捉区域。

谷歌Duo的高级产品经理谷歌Niklas Blum表示,这个按钮实际上不会改变“被照亮的人”那一端的任何设置。Duo中启用这一项新功能后,当手机检测到昏暗的灯光时就会对画面进行调整,从而让画面中的人更加明显。

这篇关于RTC 月度小报 8 月 | RTC 大会限免进行时、Janus 作者“见面会”、Google开源了一个语音引擎...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




