本文主要是介绍深度学习论文阅读笔记 | MemNetIAN情感分析论文EMNLP 2016,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
深度学习论文阅读笔记 | MemNet&IAN情感分析论文EMNLP 2016

嗨,我是error。
这又是我的一个新系列,主要记录我阅读过的一些论文的笔记,与大家一起分享讨论,不定期更新,若有错误欢迎随时指出。
泛读
首先说一下整一篇论文的结构,这篇论文作者从MemNet汲取灵感,应用在多情感分类问题上面,结合注意力模型和定位取得了不错的成绩,达到了当时的SOTA。
论文的核心我也已经在思维导图中标记出来了,主要是在注意力模型和定位上面。
Abstract
We introduce a deep memory network for aspect level sentiment classification. Un- like feature-based SVM and sequential neu- ral models such as LSTM, this approach ex- plicitly captures the importance of each con- text word when inferring the sentiment polar- ity of an aspect. Such importance degree and text representation are calculated with multi- ple computational layers, each of which is a neural attention model over an external mem- ory. Experiments on laptop and restaurant datasets demonstrate that our approach per- forms comparable to state-of-art feature based SVM system, and substantially better than LSTM and attention-based LSTM architec- tures. On both datasets we show that mul- tiple computational layers could improve the performance. Moreover, our approach is also fast. The deep memory network with 9 lay- ers is 15 times faster than LSTM with a CPU implementation.
摘要在对比了经典的SVM和LSTM模型后提到了自己这个模型的优点:
1.准确率高,目前的SOTA
2.运行速度快,即使九层依旧比LSTM快15倍
3.模型更稳定,在分析极性情感时更robust
Introduction
这一个part举了一个例子:
“great food but the service was dreadful!”
这是一个很典型的例子,首先是涉及到两个aspect,其次是两个aspect的评分极性完全相反。十分考验模型的分析准确度。
Despite these advantages, conventional neural
models like long short-term memory (LSTM) (Tang et al., 2015a) capture context information in an im- plicit way, and are incapable of explicitly exhibit- ing important context clues of an aspect.
紧接着作者分析了传统LSTM的缺点,不能够很明确的定位到决定这个aspect的情感词。
Each layer is a content- and location- based attention model, which first learns the importance/weight of each context word and then utilizes this information to calculate continu- ous text representation.
然后作者点出了自己模型的一个架构,即共享参数,打通分析信息的屏障。
As every component is differentiable, the entire model could be efficiently trained end-to- end with gradient descent, where the loss function is the cross-entropy error of sentiment classification
还有一些简要的介绍。
精读
首先看下整个模型的结构示意图
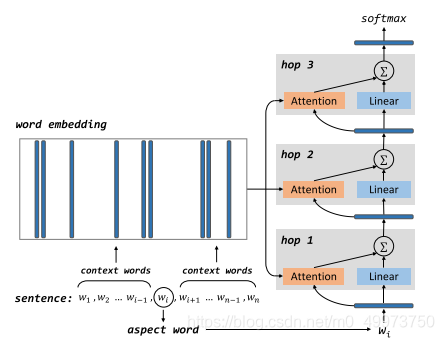
整个模型是借鉴了End-to-end MemNet的结构,
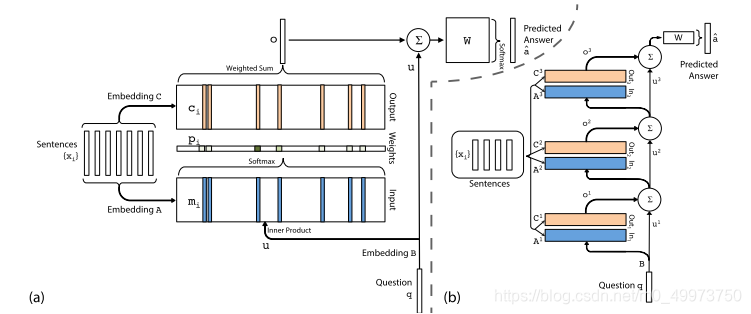
首先将aspect词提取出来后将剩下的句子和aspect都转化为vector,注意这里的embedding参数是共享学习的,没有区分。
It is helpful to note that the parameters of attention
and linear layers are shared in different hops. There- fore, the model with one layer and the model with nine layers have the same number of parameters.
如果aspect词量不同如何解决,作者也给出了方案,就是取平均,为了方便,下面的内容都以单个aspect词为例
If aspect is a single word like “food” or “service”, aspect representation is the embedding of aspect word. For the case where aspect is multi word expression like “battery life”, aspect represen- tation is an average of its constituting word vectors (Sun et al., 2015).
3.3 Content Attention

接下来的重点为Content Attention,通过一个0-1的权重a来调节注意力,而a又是通过一个softmax(g)求得,g则是通过一个对线性层非线性tanh激活所得到的。


这里作者总结了这个模型的两个优点,即
One advantage is that this model could adaptively assign an importance score to each piece of memory mi according to its semantic relatedness with the aspect. Another advantage is that this at- tention model is differentiable, so that it could be easily trained together with other components in an end-to-end fashion.
1.可根据aspect自动调整在每个memory的注意力
2.受益于此模型结果,此模型可以快速融合与其他模块在一起训练。
3.4 Location Attention
本模型另一个亮点为定位注意力模型,一般来说离这个词越近,注意力就应该越大,此模型也符合这样的认知。作者同时给出了四个注意力策略供选择。
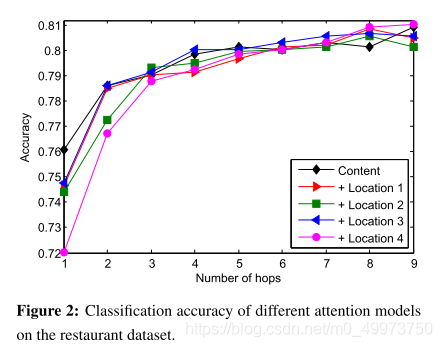
4.4 Effects of Location Attention
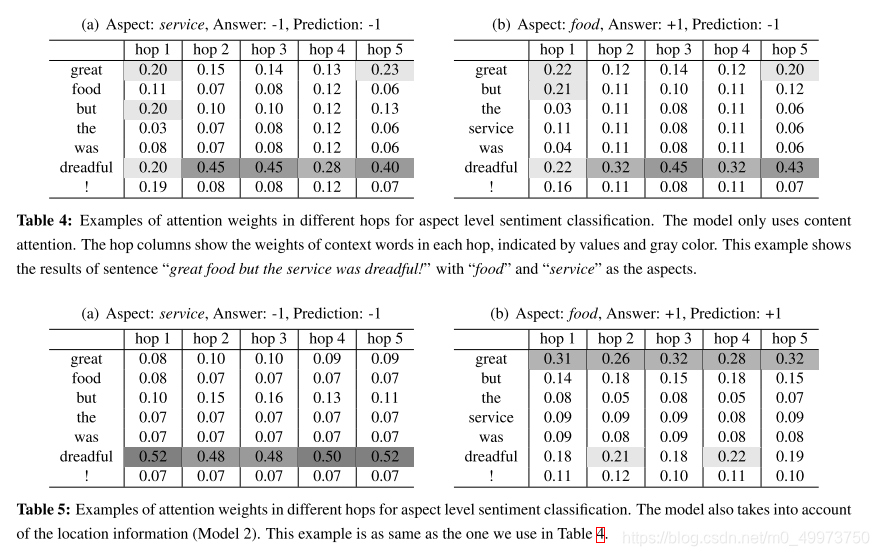
可见定位注意力模型对准确定位对应的情感词有很大帮助
但在多个hop上跑的时候发现只有在5之后才略显优势
小总结
本篇论文从记忆网络的架构得到灵感将它应用到多情感分类问题上面,最终取得了当时的SOTA。此模型最显著的优势我觉得有两个,一个是面对多aspect的情感分析上很robust,这得益于location attention的功劳。其次是速度,是的,还记得开头作者提到的吗?即使是9层hop都要比LSTM快15倍,这个速度的提升是十分可怕的。究其原因是作者在hop上面的巧妙结构上,没有采用LSTM一层套一层的结构而是相对独立的一个个hop,即保证了效果也大大提高了速度。
如果你也想下载原文来看看,为了防止链接安全性,关注微信公众号【error13】并回复IAN即可免费获得链接。


这篇关于深度学习论文阅读笔记 | MemNetIAN情感分析论文EMNLP 2016的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





