本文主要是介绍教你一招另辟蹊径抓取美团火锅数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
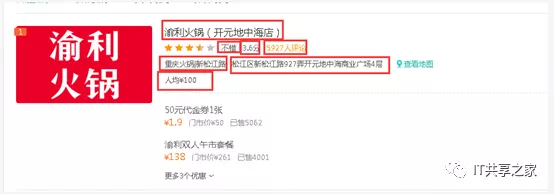
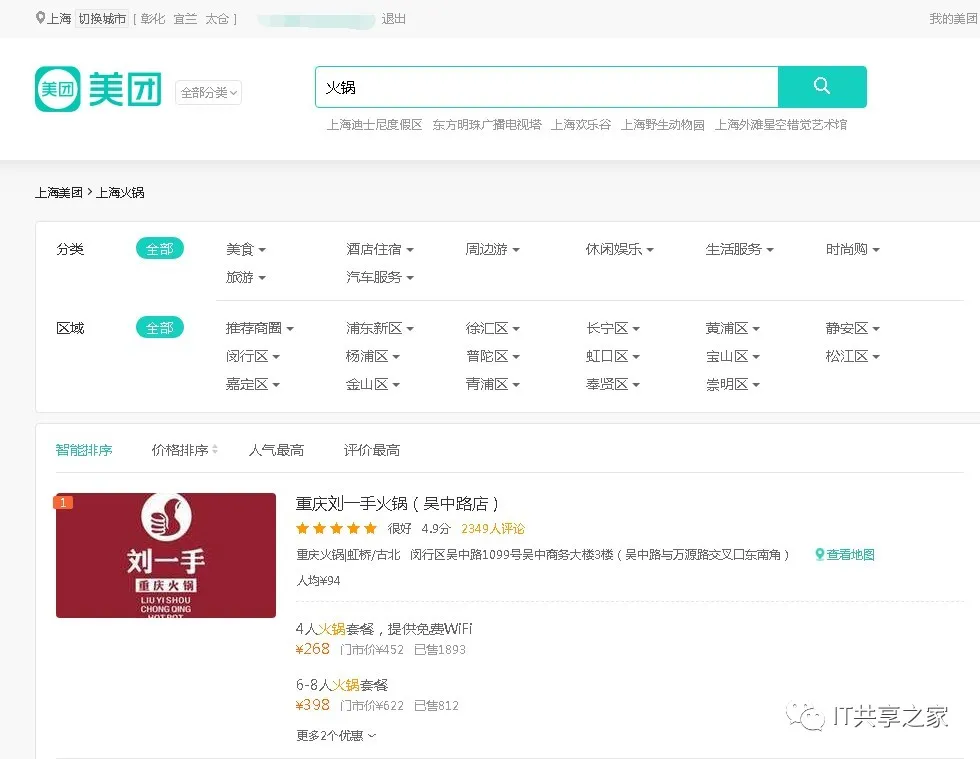
最近有个小伙伴在群里问美团数据怎么获取,而且她只要火锅数据,她在上海,只要求抓上海美团火锅的数据,而且要求也不高,只要100条,想做个简单的分析,相关的字段如下图所示。
乍一看,这个问题还真的是蛮难的,毕竟美团也不是那么好抓,什么验证码,模拟登陆等一大堆拂面而来,吓得小伙伴都倒地了。
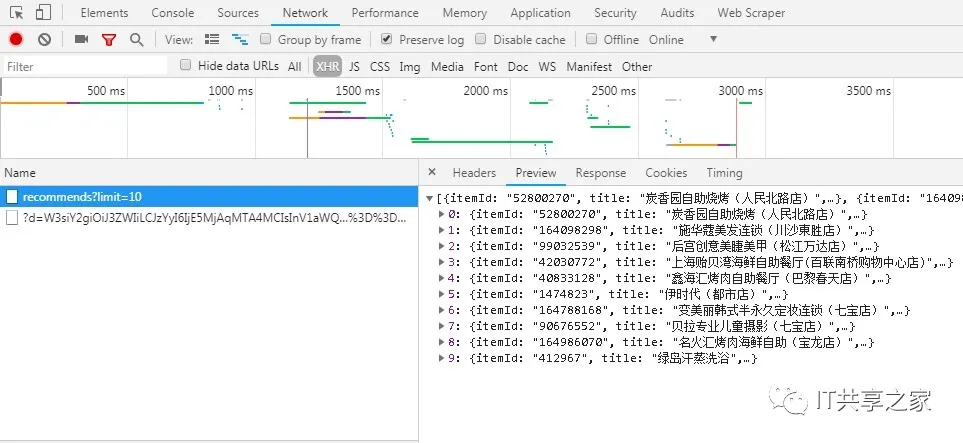
通过F12查看,抓包,分析URL,找规律,等等操作。
不过白慌,今天小编给大家介绍一个小技巧,另辟蹊径去搞定美团的数据,这里需要用到抓包工具Fiddler。讲道理,之前我开始接触网络爬虫的时候也没有听过这个东东,后来就慢慢知道了,而且它真的蛮实用的,建议大家都能学会用它。这个工具专门用于抓包,而且其安装包也非常小,如下图所示。
接下来,我们开始进行抓取信息。
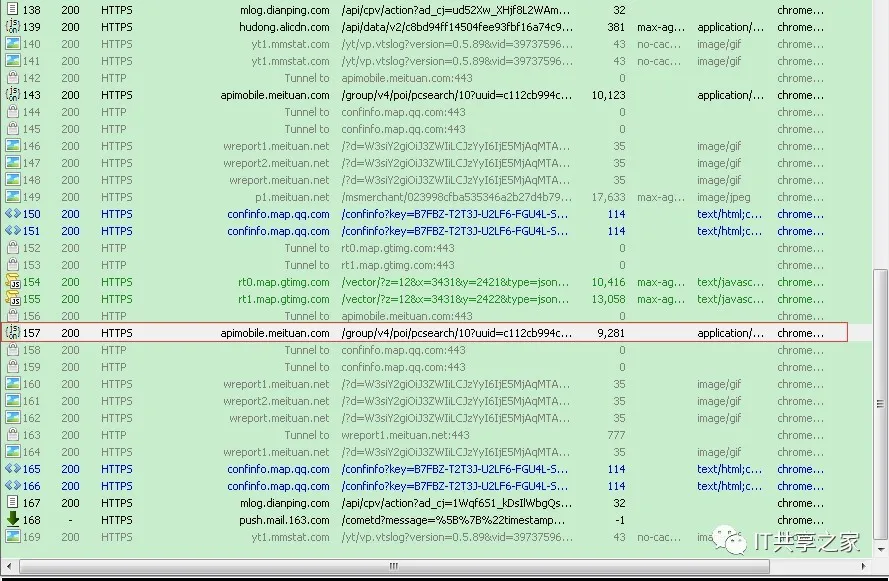
1、在Fiddler的左侧找到meituan网站的链接,如下图所示。链接的左边返回的response(响应)的文件类型,可以看到是JSON文件,尔后双击这一行链接。
2、此时在右侧会显示下图的界面,点击黄色区域内的那串英文“Responsebody is encoded. Click to decode.”意思是response是加密的,点击此处进行解码,对返回的网页进行解码。

3、此时会弹出下图所示的界面,在WebView中可以看到返回的数据,与网页中的内容对应一致。
4、不过美团网限制一页最多显示32条火锅信息,如下图所示。
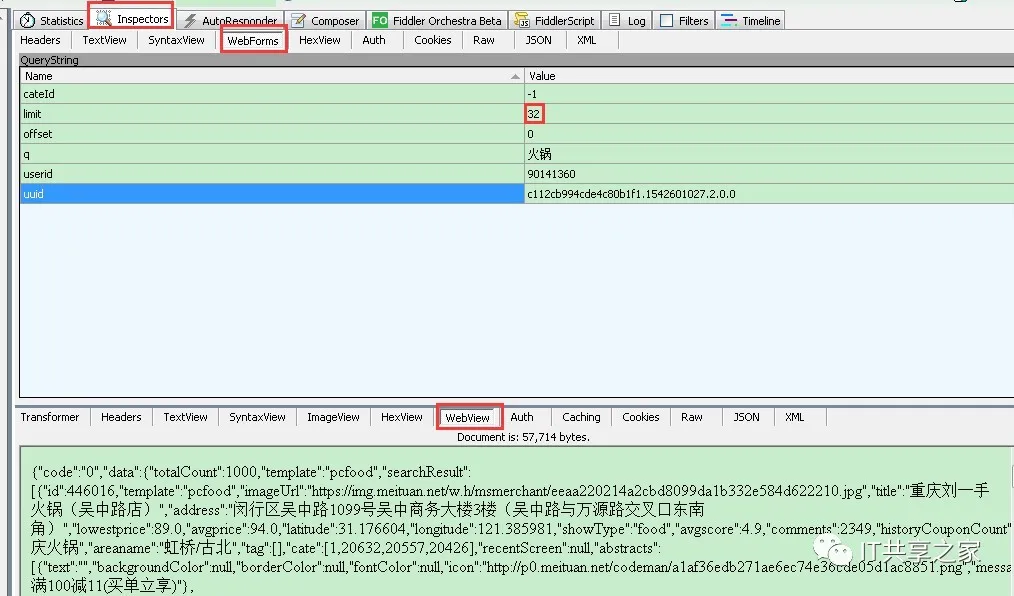
5、如果我想获取100条信息的话,那得前后找4页,才能够满足要求。有没有办法让其一次性多显示一些数据呢?答案是可以的,操作方法如下。
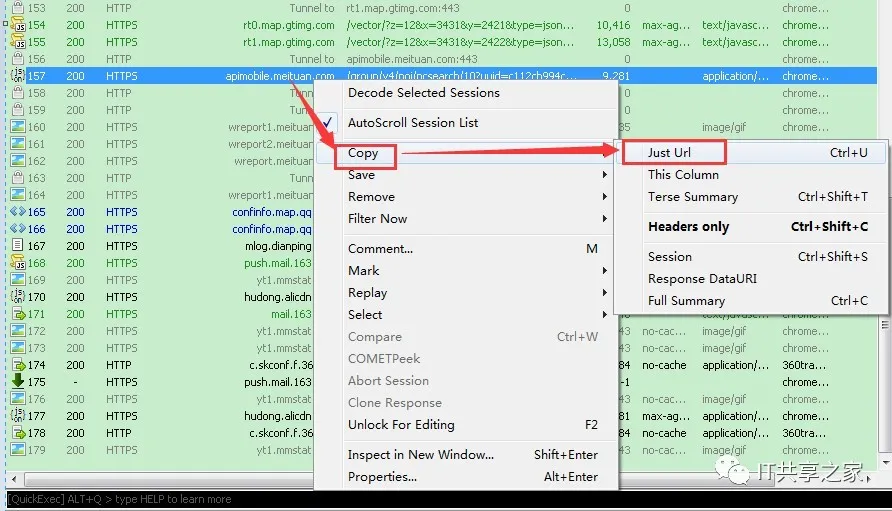
在左侧找到对应的美团网链接,然后点击右键一次选择CopyàJustUrl,如下图所示。
7、将得到的URL放到浏览器中去进行访问,如下图所示。可以看到limit=32,即代表可以获取到32条相关的火锅信息,并且返回的内容和Fiddler抓包工具返回的信息是一致的。
8、此时,我们直接在浏览器中将limit=32这个参数改为limit=100,也就是说将32更改为100,让其一次性返回100条火锅数据,天助我也,竟然可以一次性访问到,如下图所示。就这样,轻轻松松的拿到了一百条数据。
9、接下来,可以将浏览器返回的数据进行Ctrl+A全部选中,放到一个本地文件中去,存为txt格式,在sublime中打开,如下图所示。

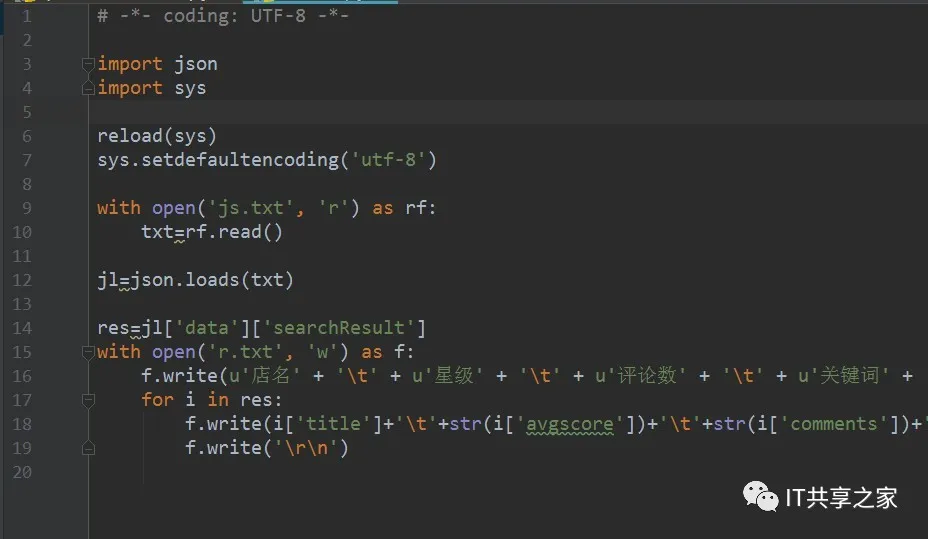
10、其实乍一看觉得很乱,其实它就是一个JSON文件,剩下的工作就是对这个JSON文件做字符串的提取,写个代码,提取我们的目标信息,包括店门、星级、评论数、关键词、地址、人均消费等,如下图所示。
11、运行程序之后,我们会得到一个txt文件,列与列之间以制表符分开,如下图所示。

12、在txt文件中看上去很是费劲,将其导入到Excel文件中去,就清晰多了,如下图所示。接下来就可以很方便的对数据做分析什么的了。

13、至此,抓取美团火锅数据的简易方法就介绍到这里了,希望小伙伴们都可以学会,以后抓取类似的数据就不用找他人帮你写程序啦~~
14、关于本文涉及的部分代码,小编已经上传到github了,后台回复【美团火锅】四个字即可获取。
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】
 想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/
想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/
这篇关于教你一招另辟蹊径抓取美团火锅数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







