本文主要是介绍TensorFlow入门教程(24)图像超分辨率模型SRGAN源码解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
#
#作者:韦访
#博客:https://blog.csdn.net/rookie_wei
#微信:1007895847
#添加微信的备注一下是CSDN的
#欢迎大家一起学习
#
1、概述
上两讲中,我们了解了怎么将图像超分辨率模型SRGAN移植到安卓APP中,但是并没怎么涉及到SRGAN模型本身的知识,这一讲就来补补。源码怎么下载和使用,请看第22讲:
https://blog.csdn.net/rookie_wei/article/details/110356225
环境配置:
操作系统:Win10 64位
显卡:GTX 1080ti
Python:Python3.7
TensorFlow:2.3.0
2、DIV2K数据集
我们这里使用的是DIV2K数据集,源码中的data.py提供了下载和解压数据集的功能,我们先来调用它把数据集下载并解压到本地,再来看看这个数据集是什么回事,代码如下,
from data import DIV2Ktrain_loader = DIV2K(scale=4, # 2, 3, 4 or 8downgrade='bicubic', # 'bicubic', 'unknown', 'mild' or 'difficult' subset='train') # Training dataset are images 001 - 800# Create a tf.data.Dataset
train_ds = train_loader.dataset(batch_size=16, # batch size as described in the EDSR and WDSR papersrandom_transform=True, # random crop, flip, rotate as described in the EDSR paperrepeat_count=None) # repeat iterating over training images indefinitelyvalid_loader = DIV2K(scale=4, # 2, 3, 4 or 8downgrade='bicubic', # 'bicubic', 'unknown', 'mild' or 'difficult' subset='valid') # Validation dataset are images 801 - 900# Create a tf.data.Dataset
valid_ds = valid_loader.dataset(batch_size=1, # use batch size of 1 as DIV2K images have different sizerandom_transform=False, # use DIV2K images in original size repeat_count=1) # 1 epoch 运行结果,


如果一切顺利的话,会在当前项目的根目录下生成一个名为“.div2k”的文件夹,该文件夹下有caches和images两个文件,我们先来看一下images文件夹,
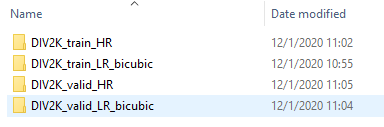
如上图所示,images文件夹下一共有4个子文件夹,通过文件夹名字可以猜到,带“train”的就是我们的训练集,带“valid”的就是我们的验证集。先来对比DIV2K_train_HR和DIV2K_train_LR_bicubic这两个文件夹,DIV2K_train_HR文件夹下直接就是800张图片,而且图片都是高清的,

DIV2K_train_LR_bicubic文件夹下则有一个名为“X4”的子文件夹,子文件夹下也有800张图片,不过并不是高清图,

对比DIV2K_train_HR和DIV2K_train_LR_bicubic这两个文件夹可以发现,他们的图片其实是一样的,只不过DIV2K_train_LR_bicubic文件夹下的图片的分辨率是DIV2K_train_HR文件夹下对应的图片的1/4,而且是经过bicubic算法缩放的。

这样,我们就可以让DIV2K_train_LR_bicubic下的图片经过SRGAN模型还原成本身4倍大小的高清图,而对应的DIV2K_train_HR文件夹下的图片就是我们的“label”。
3、数据增强
上面我们通过DIV2K这个类将数据集下载并解压好了,现在,我们来看DIV2K这个类的代码,看看它对数据集进行怎样的预处理。
首先看我们怎么实例化这个类时传入的参数,
train_loader = DIV2K(scale=4, # 2, 3, 4 or 8downgrade='bicubic', # 'bicubic', 'unknown', 'mild' or 'difficult' subset='train') # Training dataset are images 001 - 800
上面代码中,scale指的是低分辨率图相对于高清图的缩小比例,我们这里用的是4倍。downgrade指的是缩放算法,我们用常见的bicubic算法。suset指定是训练集还是测试集。DIV2K的__init__函数就是初始化一些变量,比较简单就不看了,重点来看它的dataset函数,代码如下,
def dataset(self, batch_size=16, repeat_count=None, random_transform=True):ds = tf.data.Dataset.zip((self.lr_dataset(), self.hr_dataset()))if random_transform:ds = ds.map(lambda lr, hr: random_crop(lr, hr, scale=self.scale), num_parallel_calls=AUTOTUNE)ds = ds.map(random_rotate, num_parallel_calls=AUTOTUNE)ds = ds.map(random_flip, num_parallel_calls=AUTOTUNE)ds = ds.batch(batch_size)ds = ds.repeat(repeat_count)ds = ds.prefetch(buffer_size=AUTOTUNE)return ds
可以看到,这个函数就是用tf.data.Dataset接口对数据进行数据增强和设置batch等一些操作,先来看lr_dataset函数,代码如下,
def lr_dataset(self):if not os.path.exists(self._lr_images_dir()):download_archive(self._lr_images_archive(), self.images_dir, extract=True)ds = self._images_dataset(self._lr_image_files()).cache(self._lr_cache_file())if not os.path.exists(self._lr_cache_index()):self._populate_cache(ds, self._lr_cache_file())return ds
如上代码所示,它先去检查数据集的目录是否存在,如果不存在的话就下载并解压数据集。接着,看_images_dataset函数,代码如下,
@staticmethoddef _images_dataset(image_files):ds = tf.data.Dataset.from_tensor_slices(image_files)ds = ds.map(tf.io.read_file)ds = ds.map(lambda x: tf.image.decode_png(x, channels=3), num_parallel_calls=AUTOTUNE)return ds
这个函数就是使用tf.data.Dataset接口创建Dataset对象的,然后,使用tf.io.read_file和tf.image.decode_png来读取和解析图片数据。image_files就是所有低分辨率图片的文件路径列表,通过_lr_image_files函数获取,代码如下,
def _lr_image_files(self):images_dir = self._lr_images_dir()return [os.path.join(images_dir, self._lr_image_file(image_id)) for image_id in self.image_ids]
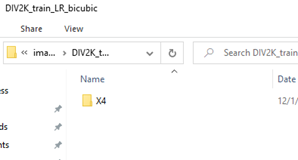
再看一下lr_dataset函数,再得到Dataset对象以后,它又调用了Dataset的cache函数将数据缓存到cache文件中,也就是.div2k/cache文件夹下的文件,如下图示,

这样做估计能提高读取数据集的速度吧。
hr_dataset函数的操作和lr_dataset函数类似。
再回到dataset函数,得到lr和hr的Dataset对象以后,就要对它们进行数据增强操作了,先来看random_crop操作,代码如下,
def random_crop(lr_img, hr_img, hr_crop_size=96, scale=2):lr_crop_size = hr_crop_size // scalelr_img_shape = tf.shape(lr_img)[:2]lr_w = tf.random.uniform(shape=(), maxval=lr_img_shape[1] - lr_crop_size + 1, dtype=tf.int32)lr_h = tf.random.uniform(shape=(), maxval=lr_img_shape[0] - lr_crop_size + 1, dtype=tf.int32)hr_w = lr_w * scalehr_h = lr_h * scalelr_img_cropped = lr_img[lr_h:lr_h + lr_crop_size, lr_w:lr_w + lr_crop_size]hr_img_cropped = hr_img[hr_h:hr_h + hr_crop_size, hr_w:hr_w + hr_crop_size]return lr_img_cropped, hr_img_cropped
这个函数的作用是随机裁剪低分辨率图和高清图“相同位置”的一小块图片。为什么不用整张图做训练?
- 在上一讲中我们知道了,运行SRGAN模型是非常耗内存的,如果用大图来训练机器硬件资源消耗过大。
- 随机截取图片的小片段来训练其实也是扩充了我们的数据集“图片”数量,防止过拟合。本来我们训练集里也才800张图片,现在这样随机截取图片,相当于图片扩充了N倍了。
接着回到dataset函数,随机裁剪操作以后,还有随机旋转和随机翻转的操作,这些都是数据增强中的常规操作了,就不多说了。
4、生成器pre-training
SRGAN是生成对抗神经网络(GAN),所以它由生成器和判别器组成。在进行GAN训练之前,一般可以先单独对生成器进行pre-training,得到一个“还不错”的生成器模型作为初始模型以后,再进行GAN训练,继续优化生成器和判别器。不只是GAN,有很多其他的模型也都会才有这种预训练的方式。先来看pre-training的代码,代码如下,
from model.srgan import generator
from train import SrganGeneratorTrainer
from data import DIV2Ktrain_loader = DIV2K(scale=4, # 2, 3, 4 or 8downgrade='bicubic', # 'bicubic', 'unknown', 'mild' or 'difficult' subset='train') # Training dataset are images 001 - 800# Create a tf.data.Dataset
train_ds = train_loader.dataset(batch_size=16, # batch size as described in the EDSR and WDSR papersrandom_transform=True, # random crop, flip, rotate as described in the EDSR paperrepeat_count=None) # repeat iterating over training images indefinitelyvalid_loader = DIV2K(scale=4, # 2, 3, 4 or 8downgrade='bicubic', # 'bicubic', 'unknown', 'mild' or 'difficult' subset='valid') # Validation dataset are images 801 - 900# Create a tf.data.Dataset
valid_ds = valid_loader.dataset(batch_size=1, # use batch size of 1 as DIV2K images have different sizerandom_transform=False, # use DIV2K images in original size repeat_count=1) # 1 epoch # Create a training context for the generator (SRResNet) alone.
pre_trainer = SrganGeneratorTrainer(model=generator(), checkpoint_dir=f'.ckpt/pre_generator')# Pre-train the generator with 1,000,000 steps (100,000 works fine too).
pre_trainer.train(train_ds, valid_ds.take(10), steps=1000000, evaluate_every=1000)# Save weights of pre-trained generator (needed for fine-tuning with GAN).
pre_trainer.model.save_weights('weights/srgan/pre_generator.h5')
5、生成器网络
上面代码中,generator()就是SRGAN的生成器网络,看代码之前,我们先来看原始论文中怎么设计这个网络的,
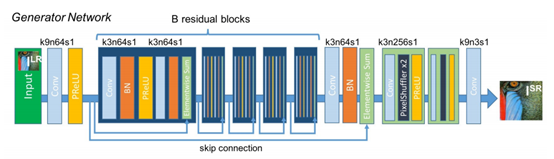
然后再看代码,
def upsample(x_in, num_filters):x = Conv2D(num_filters, kernel_size=3, padding='same')(x_in)x = Lambda(pixel_shuffle(scale=2))(x)return PReLU(shared_axes=[1, 2])(x)def res_block(x_in, num_filters, momentum=0.8):x = Conv2D(num_filters, kernel_size=3, padding='same')(x_in)x = BatchNormalization(momentum=momentum)(x)x = PReLU(shared_axes=[1, 2])(x)x = Conv2D(num_filters, kernel_size=3, padding='same')(x)x = BatchNormalization(momentum=momentum)(x)x = Add()([x_in, x])return xdef sr_resnet(num_filters=64, num_res_blocks=16):x_in = Input(shape=(None, None, 3))x = Lambda(normalize_01)(x_in)x = Conv2D(num_filters, kernel_size=9, padding='same')(x)x = x_1 = PReLU(shared_axes=[1, 2])(x)for _ in range(num_res_blocks):x = res_block(x, num_filters)x = Conv2D(num_filters, kernel_size=3, padding='same')(x)x = BatchNormalization()(x)x = Add()([x_1, x])x = upsample(x, num_filters * 4)x = upsample(x, num_filters * 4)x = Conv2D(3, kernel_size=9, padding='same', activation='tanh')(x)x = Lambda(denormalize_m11)(x)return Model(x_in, x)generator = sr_resnet
模型对输入图片的大小是不做限制的,论文中的模型结构已经很清楚了,照着写代码就可以了。
回到SrganGeneratorTrainer类,该类继承了Trainer类,具体的训练代码是由Trainer类实现的,之所以这样设计,是因为这个代码不只是实现了SRGAN,还实现了EDSR和WDSR模型,这两个模型也都是图像超分辨率的模型。先看SrganGeneratorTrainer类的实现,代码如下,
class SrganGeneratorTrainer(Trainer):def __init__(self,model,checkpoint_dir,learning_rate=1e-4):super().__init__(model, loss=MeanSquaredError(), learning_rate=learning_rate, checkpoint_dir=checkpoint_dir)def train(self, train_dataset, valid_dataset, steps=1000000, evaluate_every=1000, save_best_only=True):super().train(train_dataset, valid_dataset, steps, evaluate_every, save_best_only)
这里主要是设置了一些超参数,重点来看Trainer类的train函数,代码如下,
def train(self, train_dataset, valid_dataset, steps, evaluate_every=1000, save_best_only=False):loss_mean = Mean()ckpt_mgr = self.checkpoint_managerckpt = self.checkpointself.now = time.perf_counter()for lr, hr in train_dataset.take(steps - ckpt.step.numpy()):ckpt.step.assign_add(1)step = ckpt.step.numpy()loss = self.train_step(lr, hr)loss_mean(loss)if step % evaluate_every == 0:loss_value = loss_mean.result()loss_mean.reset_states()# Compute PSNR on validation datasetpsnr_value = self.evaluate(valid_dataset)duration = time.perf_counter() - self.nowprint(f'{step}/{steps}: loss = {loss_value.numpy():.3f}, PSNR = {psnr_value.numpy():3f} ({duration:.2f}s)')if save_best_only and psnr_value <= ckpt.psnr:self.now = time.perf_counter()# skip saving checkpoint, no PSNR improvementcontinueckpt.psnr = psnr_valueckpt_mgr.save()self.now = time.perf_counter()
ckpt_mgr和ckpt是用来在训练过程中保存模型和中断训练后重新加载模型用的,在__init__函数中定义,代码如下,
self.checkpoint = tf.train.Checkpoint(step=tf.Variable(0),psnr=tf.Variable(-1.0),optimizer=Adam(learning_rate),model=model)self.checkpoint_manager = tf.train.CheckpointManager(checkpoint=self.checkpoint,directory=checkpoint_dir,max_to_keep=3)train_step函数是重点,代码如下,
@tf.functiondef train_step(self, lr, hr):with tf.GradientTape() as tape:lr = tf.cast(lr, tf.float32)hr = tf.cast(hr, tf.float32)sr = self.checkpoint.model(lr, training=True)loss_value = self.loss(hr, sr)gradients = tape.gradient(loss_value, self.checkpoint.model.trainable_variables)self.checkpoint.optimizer.apply_gradients(zip(gradients, self.checkpoint.model.trainable_variables))return loss_value
首先将lr和hr的数据类型转成float型,然后,将lr的数据送入模型中,得到模型生成的高清图sr,然后经过loss函数求hr和sr的误差,通过SrganGeneratorTrainer类的__init__函数可以看到,这里的loss函数其实就是均方误差函数MeanSquaredError。得到损失值以后,再求梯度并使用优化器优化模型即可。
train完以后,将预训练的模型保存起来,作为GAN训练的生成器的初始值。
pre_trainer.model.save_weights('weights/srgan/pre_generator.h5')6、判别器网络
上面讲了生成器网络,现在来看GAN中另一个重要的网络----判别器。先来看原论文中的网络结构,如下图所示,

代码如下,
def discriminator_block(x_in, num_filters, strides=1, batchnorm=True, momentum=0.8):x = Conv2D(num_filters, kernel_size=3, strides=strides, padding='same')(x_in)if batchnorm:x = BatchNormalization(momentum=momentum)(x)return LeakyReLU(alpha=0.2)(x)def discriminator(num_filters=64):x_in = Input(shape=(HR_SIZE, HR_SIZE, 3))x = Lambda(normalize_m11)(x_in)x = discriminator_block(x, num_filters, batchnorm=False)x = discriminator_block(x, num_filters, strides=2)x = discriminator_block(x, num_filters * 2)x = discriminator_block(x, num_filters * 2, strides=2)x = discriminator_block(x, num_filters * 4)x = discriminator_block(x, num_filters * 4, strides=2)x = discriminator_block(x, num_filters * 8)x = discriminator_block(x, num_filters * 8, strides=2)x = Flatten()(x)x = Dense(1024)(x)x = LeakyReLU(alpha=0.2)(x)x = Dense(1, activation='sigmoid')(x)return Model(x_in, x)
也是根据网络结构搭建就好了。
7、损失函数
在继续往下看代码之前,先讲我们待会需要用到的几个损失函数。




8、训练GAN
接下来,就是训练GAN 了,先看代码,
from model.srgan import generator, discriminator
from train import SrganTrainer
from data import DIV2Ktrain_loader = DIV2K(scale=4, # 2, 3, 4 or 8downgrade='bicubic', # 'bicubic', 'unknown', 'mild' or 'difficult' subset='train') # Training dataset are images 001 - 800# Create a tf.data.Dataset
train_ds = train_loader.dataset(batch_size=16, # batch size as described in the EDSR and WDSR papersrandom_transform=True, # random crop, flip, rotate as described in the EDSR paperrepeat_count=None) # repeat iterating over training images indefinitelyvalid_loader = DIV2K(scale=4, # 2, 3, 4 or 8downgrade='bicubic', # 'bicubic', 'unknown', 'mild' or 'difficult' subset='valid') # Validation dataset are images 801 - 900# Create a tf.data.Dataset
valid_ds = valid_loader.dataset(batch_size=1, # use batch size of 1 as DIV2K images have different sizerandom_transform=False, # use DIV2K images in original size repeat_count=1) # 1 epoch # Create a new generator and init it with pre-trained weights.
gan_generator = generator()
gan_generator.load_weights('weights/srgan/pre_generator.h5')# Create a training context for the GAN (generator + discriminator).
gan_trainer = SrganTrainer(generator=gan_generator, discriminator=discriminator())# Train the GAN with 200,000 steps.
gan_trainer.train(train_ds, steps=200000)# Save weights of generator and discriminator.
gan_trainer.generator.save_weights('weights/srgan/gan_generator.h5')
gan_trainer.discriminator.save_weights('weights/srgan/gan_discriminator.h5')
首先,生成器先加载之前预训练过的模型,
# Create a new generator and init it with pre-trained weights.
gan_generator = generator()
gan_generator.load_weights('weights/srgan/pre_generator.h5')
然后实例化SrganTrainer类,该类的两个参数分别是加载预训练模型后的生成器和判别器,
# Create a training context for the GAN (generator + discriminator).
gan_trainer = SrganTrainer(generator=gan_generator, discriminator=discriminator())
重点来看SrganTrainer类的train函数,
def train(self, train_dataset, steps=200000):pls_metric = Mean()dls_metric = Mean()step = 0for lr, hr in train_dataset.take(steps):step += 1pl, dl = self.train_step(lr, hr)pls_metric(pl)dls_metric(dl)if step % 50 == 0:print(f'{step}/{steps}, perceptual loss = {pls_metric.result():.4f}, discriminator loss = {dls_metric.result():.4f}')pls_metric.reset_states()dls_metric.reset_states()
重点来看train_step函数,
@tf.functiondef train_step(self, lr, hr):with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:lr = tf.cast(lr, tf.float32)hr = tf.cast(hr, tf.float32)sr = self.generator(lr, training=True)hr_output = self.discriminator(hr, training=True)sr_output = self.discriminator(sr, training=True)con_loss = self._content_loss(hr, sr)gen_loss = self._generator_loss(sr_output)perc_loss = con_loss + 0.001 * gen_lossdisc_loss = self._discriminator_loss(hr_output, sr_output)gradients_of_generator = gen_tape.gradient(perc_loss, self.generator.trainable_variables)gradients_of_discriminator = disc_tape.gradient(disc_loss, self.discriminator.trainable_variables)self.generator_optimizer.apply_gradients(zip(gradients_of_generator, self.generator.trainable_variables))self.discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, self.discriminator.trainable_variables))return perc_loss, disc_loss

@tf.functiondef _content_loss(self, hr, sr):sr = preprocess_input(sr)hr = preprocess_input(hr)sr_features = self.vgg(sr) / 12.75hr_features = self.vgg(hr) / 12.75return self.mean_squared_error(hr_features, sr_features)
这里其实就是先求hr和sr的VGG特征图,然后再求特征图之间的MSE,这里之所以要除以12.75,是因为论文里说的,

继续回到train_step函数,计算内容损失以后,再通过_generator_loss函数计算对抗损失![]() ,代码如下,
,代码如下,
def _generator_loss(self, sr_out):return self.binary_cross_entropy(tf.ones_like(sr_out), sr_out)
这里就是“欺骗”判别结果的代码,sr_out都是重建的图像,我们这里却说它都是原始高清图像,如果判别器没有被“骗”到了,那就算到生成器的损失里。继续看train_step函数,
perc_loss = con_loss + 0.001 * gen_loss就是我们要求的感知损失,
disc_loss = self._discriminator_loss(hr_output, sr_output)则是求判别器的损失,我们来看_discriminator_loss函数,
def _discriminator_loss(self, hr_out, sr_out):hr_loss = self.binary_cross_entropy(tf.ones_like(hr_out), hr_out)sr_loss = self.binary_cross_entropy(tf.zeros_like(sr_out), sr_out)return hr_loss + sr_loss
因为这是求判别器的损失,所以这里就得老实的告诉判别器,到底哪些图是“真图”,哪些图是“赝品”,这样判别器才能更好的工作。接下来的代码就是求生成器和判别器的梯度和优化了。
gradients_of_generator = gen_tape.gradient(perc_loss, self.generator.trainable_variables)gradients_of_discriminator = disc_tape.gradient(disc_loss, self.discriminator.trainable_variables)self.generator_optimizer.apply_gradients(zip(gradients_of_generator, self.generator.trainable_variables))self.discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, self.discriminator.trainable_variables))
这篇关于TensorFlow入门教程(24)图像超分辨率模型SRGAN源码解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





