本文主要是介绍python-文件操作,文件指针,buffering:缓冲区,编码描述符及其读写,以及上下文管理.一站式详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录标题
- 冯诺依曼体系架构
- 文件IO常用操作
- 打开操作
- open的参数
- r模式
- w模式:**没有文件**-进行创建;**有文件**-进行覆盖
- x模式:**有文件**-直接抛异常;**没有文件**-创建,只写打开
- a模式:**有文件**-只写打开,进行追加;**没有文件**-创建
- rb模式:只读二进制
- wb模式-只写二进制
- - r+/w+增加缺失能力
- 文件指针,指向当前字节位置
- seek偏移的是字符还是字节?
- 文本模式下
- 二进制模式下
- buffering:缓存区
- 简介
- 缓冲和缓存的区别?
- 缓冲数据结构:
- 缓存数据结构:
- 缓冲的目的是:
- 缓存的目的是:
- open()方法的buffering参数设置
- 参数编码描述符encoding
- encoding:编码,仅文本模式使用
- 其他参数
- errors
- newline
- read
- 行读取
- readline(size=-1)
- readlines()
- 注意事项
- write写入
- close
- 其他(返回类型都是布尔值)
- 上下文管理
- 引子
- 为了解决上述问题这里就需要使用"上下文管理"格式:
- 使用上下注意事项:
- 练习:指定一个源文件,事项copy到目录
- 练习:有一个文件,对其进行单词统计,不区分大小写,计算单词重复最多的10个单词
冯诺依曼体系架构
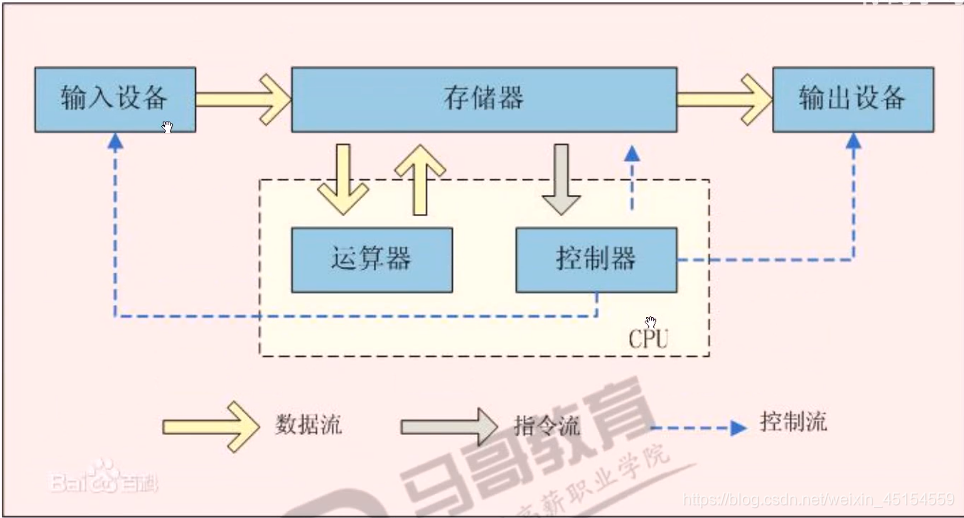
一般说IO操作,指的是文件IO,如果指的是网络IO,都会直接说网络IO
文件IO常用操作
文件操作无非就是读和写
open 打开

read 读取
write 写入
close 关闭
readline 行读取
readlines 多行读取
seek 文件指针操作
tell 指针位置
打开操作
f = open("test") # 返回的是文件对象 file object
print(f.read())
f.close() # 用完就关闭
open的参数
file:
打开或者要创建的文件名.如果不指定,默认是当前路径
mode模式:

r模式
f = open("test","r") # 只读
f.read()
f.write("abc") # 抛出错误
f.close()
w模式:没有文件-进行创建;有文件-进行覆盖
f = open("test","w") # 只写
f.write("abc")
f.close()
x模式:有文件-直接抛异常;没有文件-创建,只写打开
f = open("test2","x")
运行结果

a模式:有文件-只写打开,进行追加;没有文件-创建
f = open("test","a")
f.write("abc")
rb模式:只读二进制
f = open("test","rb")
print(f.read())
f.close()
运行结果

wb模式-只写二进制
f = open("test","wb")
f.write("啊".encode(encoding="gbk")) # 把中文转化bytes用encode()
f.close()
- r+/w+增加缺失能力
f = open("test1","r+")
运行结果

可以观察到,r+增加缺失能力,但是没有改变r的特性,r的特性是要求文件必须存在,才能打开成功.
文件指针,指向当前字节位置
mode = r,指针起始在0
mode = a,指针起始在末尾
f.tell()显示指针当前位置
f.seek(offset[,whence])移动文件指针位置.offest偏移多少字节,whence从哪里开始
seek偏移的是字符还是字节?
seek偏移的是字节
文本模式下
whence 0 缺失值,表示从头开始,正数
whence 1 表示从当前位置,offset只能用0
whence 2 表示从末尾,offset只能用0
二进制模式下
whence 0 缺失值,表示从头开始,offset正数
whence 1 表示从当前位置,offset可正可负
whence 2 表示从末尾,offset可正可负
注意:
向后seek可以越界,越界返回空字符;但是向前seek不能越界,否则抛异常
f = open("test","rb+")
f.write(b"addffg")
f.seek(50) # 向后
f.read() # 返回''空
f.seek(-20,2) # 向前
f.read() # OSError
buffering:缓存区
简介
缓冲区是一个内存空间,一般是使用一个FIFO队列(先进先出),到缓冲区满了或者到阀值了,数据会被flush到磁盘上.
缓冲和缓存的区别?
缓冲数据结构:
是一个列表或者是队列
缓存数据结构:
是一个字典
缓冲的目的是:
一堆数据排个队放哪暂存数据,减缓数据进入磁盘的速度.
缓存的目的是:
暂时性存储数据(掉电即失),使用字典数据结构为了最快速度的找到自己存储的内容,帮助硬件更快的运行
open()方法的buffering参数设置
- -1缺省buffer大小:默认是8192个字节,8192/1024 = 8k
- 0只在二进制模式使用,表示关buffer,文本下不支持
- 1只在文本模式使用,表示行缓冲.意思就是见到换行符就flush
在二进制下表示就1个字节 - 大于1:二进制下,表示指定大小,文本下指定大小还依旧表示为默认值
- flush()将缓冲区数据写入磁盘
- close()关闭前会调用flush()
为方便记忆以上总结为:
文本就默认,二进制可以指定大小.一般情况下默认是个比较好的选择,除非你明确知道你在做什么,否则不调整他
参数编码描述符encoding
encoding:编码,仅文本模式使用
Npne表示使用缺省编码,依赖操作系统

其他参数
errors
不设置,直接默认
newline
一般不设定

系统分隔符os.linesep -->\r\n回车换行
\n换行
\r回车
当写时,None表示所有的"\n换行"都会被替换成为->\r\n回车换行,当遇见\r时候就不进行替换
read
read(size=-1)
size表示读取的多少个字符或字节;负数或者None表示读取到结尾
行读取
readline(size=-1)
一行行读取文件内容.size设置一次能读取行内几个字符或字节
readlines()
读取所有行的列表.
注意事项
行读取内容以后基本不推荐使用,直接使用,以下方式:
f = open("file","r+") # 返回一个可迭代对象
for line in f:print(line) #file文件内容,一行行打印出来f.close()
write写入
write(s),把字符串s写入到文件中并返回字符的个数
writelines(lines),将字符串列表写入文件
close
释放文件对象,flus并关闭文件对象
其他(返回类型都是布尔值)
f.seekable()是否可seek
f.radable()是否可读
f.writable()是否可写
closed是否已经关闭
上下文管理
引子

当出现上述问题时我们怎么解决那??
为了解决上述问题这里就需要使用"上下文管理"格式:
with open(“test”) as f:
f.read()
使用上下注意事项:
1.上下文管理的语句块并不会开启新的作用域
2.with语句块执行完的时候,会自动关闭文件对象
上下文管理内部实现的内部原理源码详解
练习:指定一个源文件,事项copy到目录
def copyFile(src,dst):with open(src) as f1:with open(dst,"w+") as f2:f2.write(f1.read())
copyFile("file","file2")
练习:有一个文件,对其进行单词统计,不区分大小写,计算单词重复最多的10个单词
这篇关于python-文件操作,文件指针,buffering:缓冲区,编码描述符及其读写,以及上下文管理.一站式详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





