本文主要是介绍Linux获取norflash信息,linux ——Uboot模式下读取NORflash芯片数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
命令:
md指令
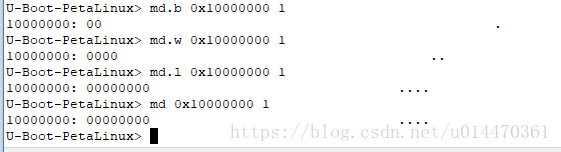
uboot下输入指令md,会提示md的用法,memory display,即内存显示。
md [.b, .w, .l] address [# of objects]
- memory display
b:8位
w:16位
l:32位(默认值)
例:
mw指令
uboot下输入指令mw,会提示md的用法,memory write,即向内存中写入数据。
U-Boot-PetaLinux> mw
mw - memory write (fill)
Usage:
mw [.b, .w, .l] address value [count]
b:8位
w:16位
l:32位(默认值),
address是要写入内存的地址,
value是要写入的值,
count是从address开始要写入多少个数,这些都是16进制数。
操作流程:
Uboot模式下读取NORflash芯片数据
注意:b8000000 为Norflash基地址,需要根据电路板自行得出。
mw.w b8000aaa aa //往地址AAAH写入AAH(解锁)
mw.w b8000554 55 //往地址554H写入55H(解锁)
mw.w b8000aaa 90 //往地址AAAH写入90H(命令)
md.w b8000000 1 // 读0地址得到厂家ID(C2H)
md.w b8000002 1 // 读2地址得到设备ID
mw.w b8000000 90 //退出读ID状态:给任意地址写F0H就可以了
U-BOOT上操作cfi 探测(读取芯片信息)
mw.w b80000aa 98 //往AAH地址写入98H
md.w b8000020 40 //读地址20H内存数据
这篇关于Linux获取norflash信息,linux ——Uboot模式下读取NORflash芯片数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







