本文主要是介绍CNN-LSTM选A股牛股(代码+数据+一键可运行),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在当前金融市场中,投资者对于高效的股票推荐系统需求不断增加。为了满足这一需求,我们开发了一款基于人工智能的牛股推荐器V1.0,其技术路线和方法在本文中将得到详细阐述。
全代码和数据关注公众号《三个篱笆三个班》免费提供!一键可跑,每日选股。
对AI炒股感兴趣的小伙伴可加WX群:caihaihua057200(备注:学校/机构+姓名+专业)
一、数据集构建与预处理
为了构建可靠的牛股推荐器,我们首先需要一个可信的数据集。我们使用akshare爬取了自2015年至今的前复权股票数据,包括每日的开盘价、收盘价、最高价、最低价、成交量、成交额、振幅、涨跌幅、涨跌额以及换手率等特征。这一数据集涵盖了5000+支股票。爬虫代码如下:
### 导包
import akshare as ak
import pandas as pd
import numpy as np
import os
from tqdm import tqdm
### 设置工作路径
mypath=r"D:\akshare"
stock_zh_spot_df = ak.stock_zh_a_spot_em() ## 获取实时数据
stock_zh_spot_data=stock_zh_spot_df[stock_zh_spot_df['名称']!=''] ## 去除名称为空值的数据
codes_names=stock_zh_spot_data[['代码','名称']]
day ='20150101'
length=len(codes_names)
all_data = pd.DataFrame([])
for i in tqdm(range(length), desc="Processing items"):data_df = ak.stock_zh_a_hist(symbol=codes_names['代码'][i], period="daily", start_date=f"{day}",adjust="qfq") ## 日度数据,后复权data_df['stock_id'] = codes_names['代码'][i]all_data = all_data.append(data_df)
all_data.to_csv(os.path.join(mypath+'\\'+f'{day}.csv'),encoding='utf_8_sig') ## 数据导出为csv文件在数据预处理过程中,排除总交易日少于300天的股票,接下来我们将单只股票按照时间窗口大小为90天进行滑动裁剪,形成(90,10)的数据样本,即每个样本包含了90天的历史特征形成一个矩阵。整个预处理过程共生成了约600多万个矩阵,即(600W+,90,10)。这些矩阵将作为训练特征。而对应于每个矩阵的标签(label)则是基于该90天之后的趋势得到的。我们设计了一个指标,即未来5天后最低价均价相对于明天开盘价的涨幅,如果未来五天内开盘价均值相对于明天的开盘价增长了25%以上,将其定义为正样本,否则为负样本。代码如下:
df = pd.read_csv('/data/chh/NLP/20150101.csv')
start_time = time.time()
grouped = df.groupby('stock_id')
samples = []
label = []
# 遍历每个产品ID的分组
for _, group in tqdm(grouped):product_samples = group.valuesnum_samples = len(product_samples)if num_samples < 300:continuefor i in range(num_samples - 95):LLL = product_samples[i:i + 96, 2:6].astype(np.float32)LLLL = product_samples[i:i + 96, 11:12].astype(np.float32)if np.any(np.isnan(LLL)) or np.any(LLL <= 0) or np.any(np.isnan(LLLL)) or np.any(LLLL < 0.1):# print("存在负值、零或空值")passelse:sample = product_samples[i:i + 90, 2:-1]l = product_samples[i + 90:i + 91, 2:3]ll = np.mean(product_samples[i + 91:i + 96, 5:6])lll = (ll - l) / lif lll > 0.25 :label.append(1)else:label.append(0)samples.append(sample)
train_data = np.array(samples)
train_data = train_data.astype(np.float32)
train_label = np.array(label)
print(train_data.shape)二、模型构建
在牛股推荐器V1.0中,我们采用了一种强大的混合模型,它由CNN-BiLSTM和2DCNN组成,用于对股票数据进行建模和预测。这个混合模型结合了卷积神经网络(CNN)和双向长短期记忆网络(BiLSTM),能够更好地捕捉时间序列信息和长期依赖关系,从而显著提高了预测性能。
在模型构建过程中,我们还引入了注意力机制和残差模块来处理近期振幅特征和换手率特征。这一举措进一步增强了模型对于这些特征的关注程度和信息利用效率。我们设计这些模块的原因在于股票数据存在时间序列现象。因此,我们选择了CNN-BiLSTM来处理时间序列数据。另外,特征也可视为一个(90,10)的特征图谱,为了提取图谱中局部特征和全局特征,我们采用了2DCNN。最后,我们将所有特征融合,并利用MLP降维到2维,从而将问题转化为分类任务。这样的设计旨在综合利用多种特征,以更好地进行股票预测。
三、训练与优化
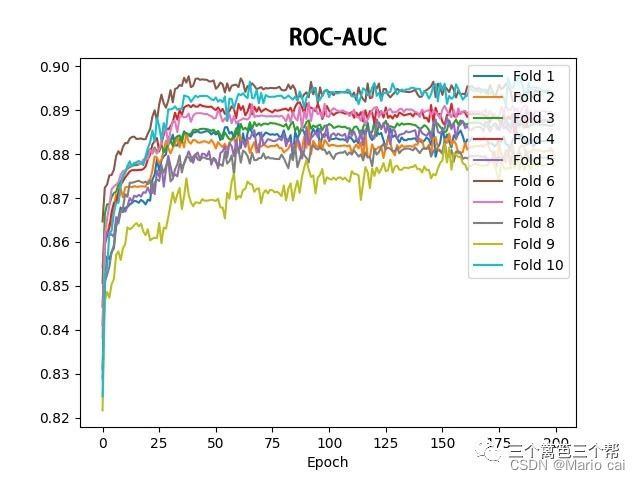
为了得到高效的牛股推荐器V1.0,我们使用了交叉熵损失函数进行模型训练。优化器方面,采用了ADAM优化器和余弦退火学习率的策略,初始学习率设置为0.001,并采用较大的batch_size=40000,以加快训练过程。为了确保模型的泛化性能,我们进行了十折交叉验证。通过十个在验证集loss最低的模型,并将最终结果取十个最优模型的均值,得到了最终的推荐结果。十折交叉验证测试结果(ROC-AUC≈0.895)证明模型具备强大的分类能力。如图:
四、应用
我们的基于AI的牛股推荐器V1.0将成为一个每日更新的实用工具。每天,我们将使用该模型爬取当天的股票数据,并通过模型的预测结果进行股票推荐。用户可以通过我们的平台免费测试和获取推荐结果。
使用我们的牛股推荐器非常简单,用户只需访问我们的公众号【三个篱笆三个班】,即可获取每日推荐结果。推荐结果将是信心指数。
值得一提的是,我们的推荐器经过了充分的训练和优化,尽可能提供准确、稳定的推荐结果。然而,投资股市存在风险,股票市场的走势难以完全预测,因此我们建议用户在做出投资决策前,还是应该谨慎考虑并做好自己的独立研究。
我们衷心希望,基于AI的牛股推荐器V1.0能够为广大投资者提供有价值的信息,帮助大家做出更明智的投资决策。同时,我们将持续改进和优化推荐器的性能,以提供更好的服务和用户体验。
欢迎大家来体验我们的牛股推荐器,并在使用过程中提供宝贵的反馈意见。我们将不断努力,为用户提供更优质的服务。祝大家投资顺利,收获丰富!
这篇关于CNN-LSTM选A股牛股(代码+数据+一键可运行)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





