最近需要把PDF解析为文字,查了查python的模块,发现PDFminer3k能满足需求。我使用的是 windows平台下的python3.6,python2的则下载pdfminer。
首先下载:直接 pip install pdfminer3k。
在网上找了教程代码跑了下自己用word转的pdf测试文件,可以解析成文字。
教程网址:http://blog.csdn.net/PianoOrRock/article/details/70666286?reload
然后运行自己真正需要的PDF时,报错:
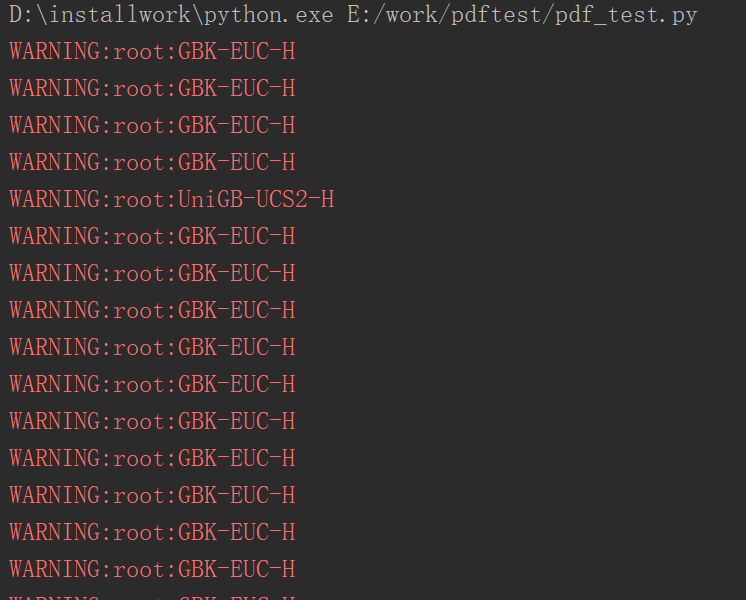
刚开始我天真的以为是pdf加密了,后来查了下发现pdfminer3k自带能解密一些简单的加密方法,且遇到加密报错不是这样的。
然后重新仔细研究报错,觉得应该是pdf的字体的问题,pdfminer3k不能解析特殊字体,需要下载相应的字体包来解决。
字体包下载网站:https://github.com/euske/pdfminer/pull/71/commits/2103e5875ef04cfaf424b25d2fd0dc9535a90714#diff-11a7e5c9b1cb16f0ae7d0276f643956d
下载好了GBK-EUC-H和UniGB-UCS2-H不要解压直接放在 pdfminer/cmap文件夹下。
运行后继续报错:
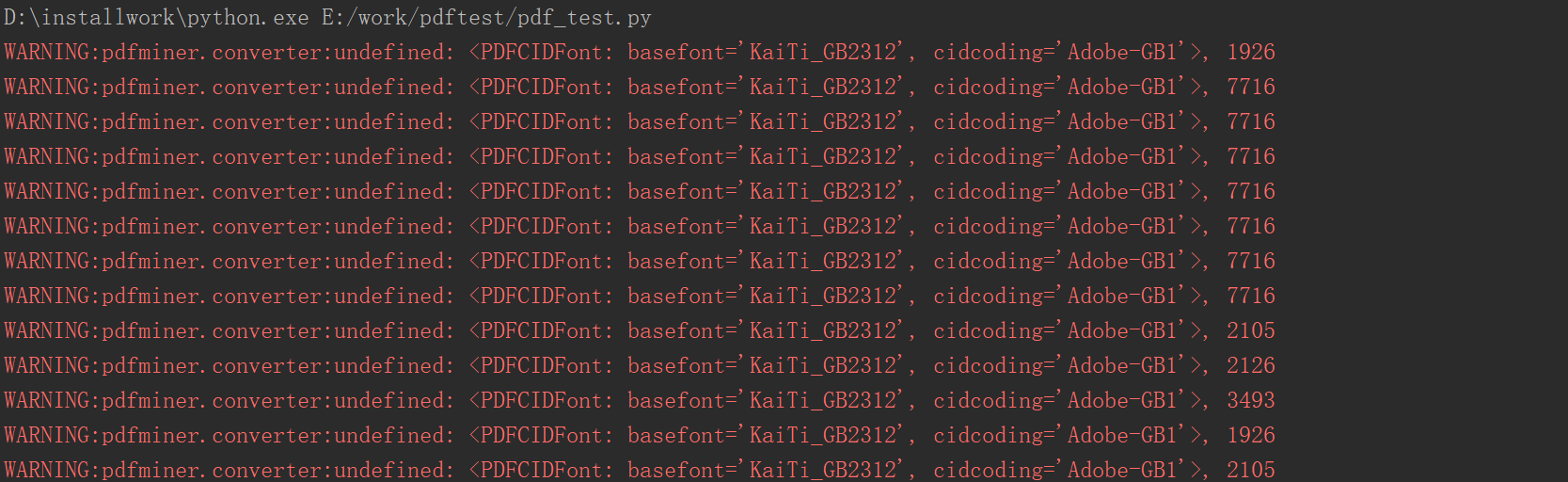
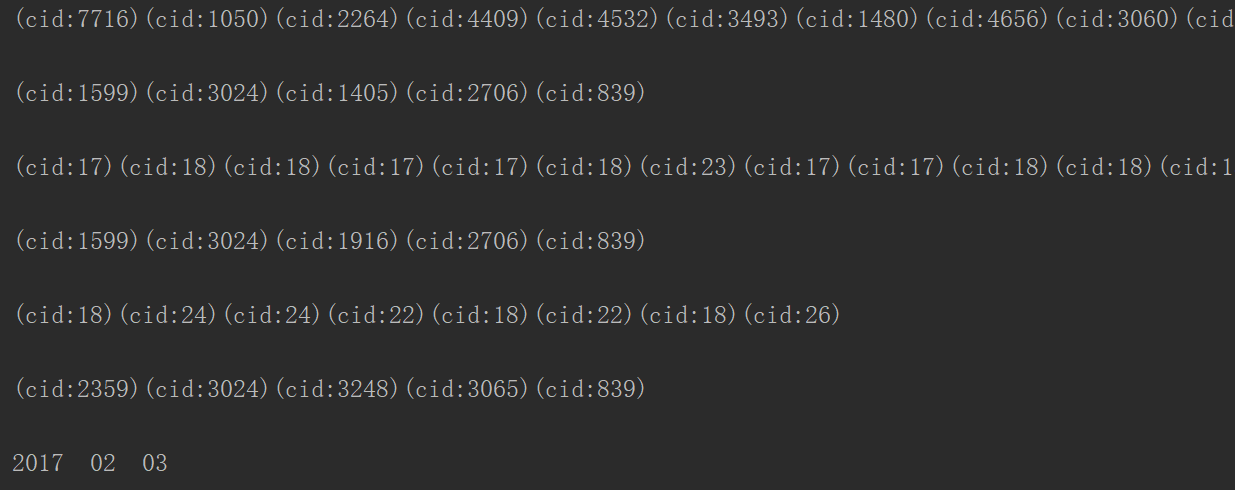
PDFMiner里并没有GBK-EUC-H和UniGB-UCS2这两个编码的解码文件,所以输出了一堆cid,继续去上面的网站找到这种编码解码包,下载后不要解压直接放到上面的文件夹里:
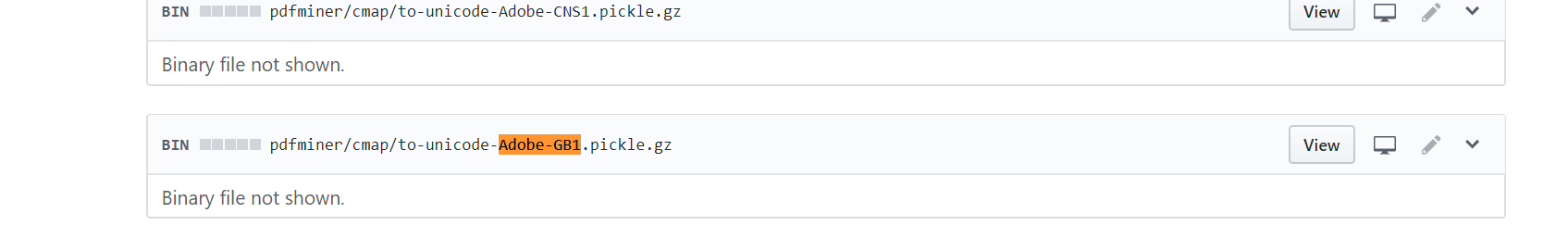
运行,解析成功!






