本文主要是介绍中国雪深长时间序列数据集(1979-2020),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
中国雪深长时间序列数据集(1979-2020)提供1979年1月1日到2020年12月31日逐日的中国范围的积雪厚度分布数据,其空间分辨率为25km,是“中国雪深长时间序列数据集(1978-2012)”的升级版本。前言 – 人工智能教程
用于反演该雪深数据集的原始数据来自美国国家雪冰数据中心(NSIDC)处理的SMMR(1979-1987年),SSM/I(1987-2007年)和SSMI/S(2008-2020)逐日被动微波亮温数据(EASE-Grid)。通过对不同传感器的亮温进行交叉定标提高亮温数据在时间上的一致性。然后利用车涛博士在Chang算法基础上针对中国地区进行修正的算法进行雪深反演。
该数据集每天1个文件,文件命名方式为:年+天,如1990001表示1990年第1天,1990207表示1990年第207天。
中国境内的积雪分布情况受到多种因素的影响,如地形、气候、季节等。一般来说,积雪主要集中在高山山脉和高纬度地区,特别是青藏高原、阿尔金山、大兴安岭等地区。以下是中国积雪分布情况的一些特点:
1. 西北地区和青藏高原积雪最多。青藏高原的平均积雪深度可达1米以上,而新疆以及陕西、甘肃等省份的高山山区,积雪深度也较大。
2. 华北、东北地区的积雪较多。这些地区的冬季寒冷,降雪量也比较大,因此积雪深度也相对较大。
3. 长江中下游地区以及南方省份积雪较少。由于气候相对温暖,降雪量也较少,因此积雪深度相对较浅。
总体来说,中国的积雪分布情况十分复杂多样,差异较大。
数据集ID:
TPDC/CHINA_25KM_SNOW_DEPTH_DAILY
时间范围: 1979年-2020年
范围: 全国
来源: 国家青藏高原科学数据中心
复制代码段:
var images = pie.ImageCollection("TPDC/CHINA_25KM_SNOW_DEPTH_DAILY")
| 名称 | 类型 | 分辨率(km) | 单位 | 无效值 | 描述信息 |
|---|---|---|---|---|---|
| B1 | float32 | 25 | cm | -1 | 积雪厚度 |
| date | string | 影像日期 |
代码:
/**
* @File : CHINA_25KM_SNOW_DEPTH_DAILY
* @Desc : 加载中国雪深长时间序列数据集
*///加载中国边界
var roi = pie.FeatureCollection("RESDC/WORLD_COUNTRY_BOUNDARY").filter(pie.Filter.eq("name", "CHINA")).first().geometry();
//加载2018年1月1日中国雪深数据
var img = pie.ImageCollection('TPDC/CHINA_25KM_SNOW_DEPTH_DAILY').filterDate("2017-12-31", "2018-01-01").first().select("B1").clip(roi);
print(img);
//设定预览参数
visParams = {min: 0, max: 32.5,palette: ['32d3ef','30c8e2','269db1','307ef3','235cb1','0602ff','0502e6','0502ce','0502b8','0502a3','040281','040274']};
//加载显示影像
Map.centerObject(img, 2);
Map.addLayer(img, visParams, "2015-01-01雪深");
// 图例
var data = {title: "雪深(cm)",colors: ['#32d3ef','#30c8e2','#269db1','#307ef3','#235cb1','#0602ff','#0502e6','#0502ce','#0502b8','#0502a3','#040281','#040274'],labels: ["0", "5", "10", "15", "20", "25", "30", "35"],step: 30};
var style = {left: "60%", top: "70%", height: "70px", width: "350px"};
var legend = ui.Legend(data, style);
Map.addUI(legend);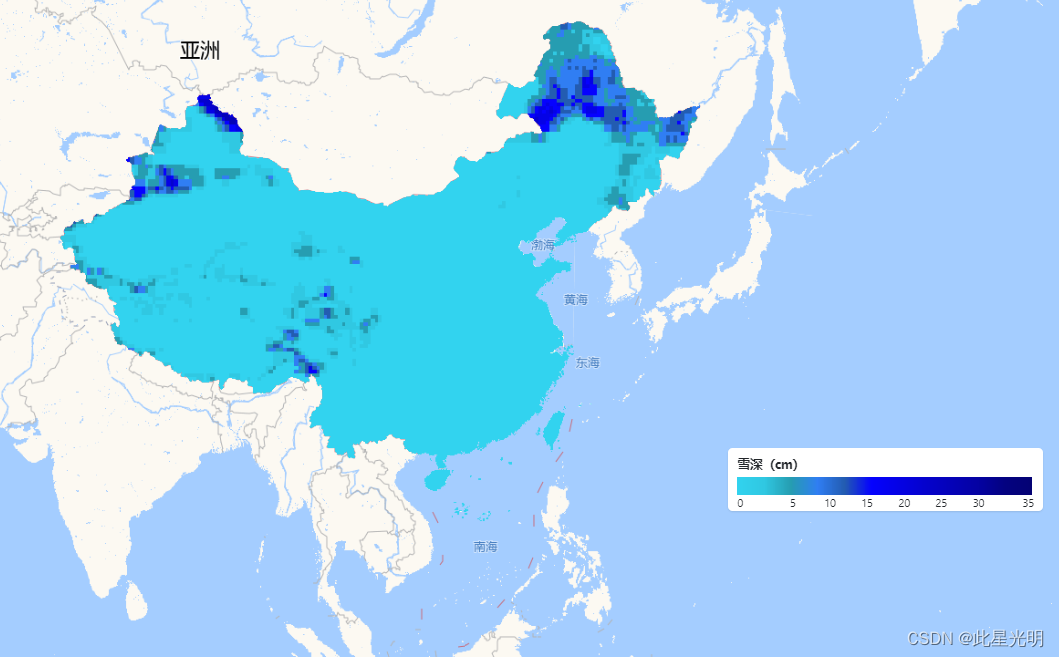
数据引用:
车涛, 戴礼云. 中国雪深长时间序列数据集(1979-2020). 国家青藏高原科学数据中心, 2015. DOI: 10.11888/Geogra.tpdc.270194. CSTR: 18406.11.Geogra.tpdc.270194.
文章引用:
1. Che, T., Li, X., Jin, R., Armstrong, R., &Zhang, T.J. (2008). Snow depth derived from passive microwave remote-sensing data in China. Annals of Glaciology, 49, 145-154.
2. Dai, L.Y., Che, T., &Ding, Y.J. (2015). Inter-calibrating SMMR, SSM/I and SSMI/S data to improve the consistency of snow-depth products in China. Remote Sensing, 7(6), 7212-7230.
3. Dai, L.Y., Che, T., Ding, Y.J., &Hao, X.H. (2017). Evaluation of snow cover and snow depth on the Qinghai–Tibetan Plateau derived from passive microwave remote sensing. The Cryosphere, 11(4), 1933-1948.
这篇关于中国雪深长时间序列数据集(1979-2020)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






