本文主要是介绍数据集读取与划分,ImageFolder(),自定义数据集,TensorDataset,StratifiedShuffleSplit,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
导包
数据集
下载数据集
数据集特点分析
torchvision.datasets.ImageFolder()
数据集整理
思路
根据图片名读标签
建立标签子文件夹
数据集划分
调用数据集处理函数
读取数据集
torchvision.datasets.ImageFolder()源码及解读
源码
解读
torchvision.datasets.ImageFolder()的特点
手写ImageFolder()
自定义数据集
数据集处理
将标签转换成为int类型
自定义数据集函数
读取数据集
数据集划分函数
train_test_split函数
用法
读取数据集
存在的问题
StratifiedShuffleSplit函数
用法
读取数据集
为什么要进行reset_index()操作
探析
random_split()
用法
划分
读取数据集
探析
其他dataset
TensorDataset
源码
建立数据集
使用dataloader
一个问题:对单个tensor进行包装
导包
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import pandas as pd
import os
import collections
import shutil
import math
from torch.utils.data import DataLoader, Dataset
from PIL import Imagedata_dir = 'data\dog-breed-identification' # 数据集所在文件夹
label_csv = 'labels.csv' # 标签文件夹名数据集
原教程网站:13.13. 实战 Kaggle 比赛:图像分类 (CIFAR-10) — 动手学深度学习 2.0.0-beta1 documentation13.14. 实战Kaggle比赛:狗的品种识别(ImageNet Dogs) — 动手学深度学习 2.0.0-beta1 documentation13.13. 实战 Kaggle 比赛:图像分类 (CIFAR-10) — 动手学深度学习 2.0.0-beta1 documentation
参考:动手学深度学习Kaggle:图像分类 (CIFAR-10和Dog Breed Identification)_iwill323的博客-CSDN博客
下载数据集
数据集网址是CIFAR-10 - Object Recognition in Images | KaggleDog Breed Identification | KaggleCIFAR-10 - Object Recognition in Images | Kaggle
下载数据集,在../data中解压下载的文件后,你将在以下路径中找到整个数据集:
- ../data/dog-breed-identification/labels.csv
- ../data/dog-breed-identification/sample_submission.csv
- ../data/dog-breed-identification/train
- ../data/dog-breed-identification/test
文件夹train/和test/分别包含训练和测试狗图像,labels.csv包含训练图像的标签,其中train文件夹含有样本图片的如下图,图像文件的名称是杂乱的
数据集特点分析
比赛数据集分为训练集和测试集,分别包含RGB(彩色)通道的10222张、10357张JPEG图像。 在训练数据集中,有120种犬类,如拉布拉多、贵宾、腊肠、萨摩耶、哈士奇、吉娃娃和约克夏等。
- 用pandas读取
trainLabels.csv文件
df = pd.read_csv(os.path.join(data_dir, label_csv))
df.head()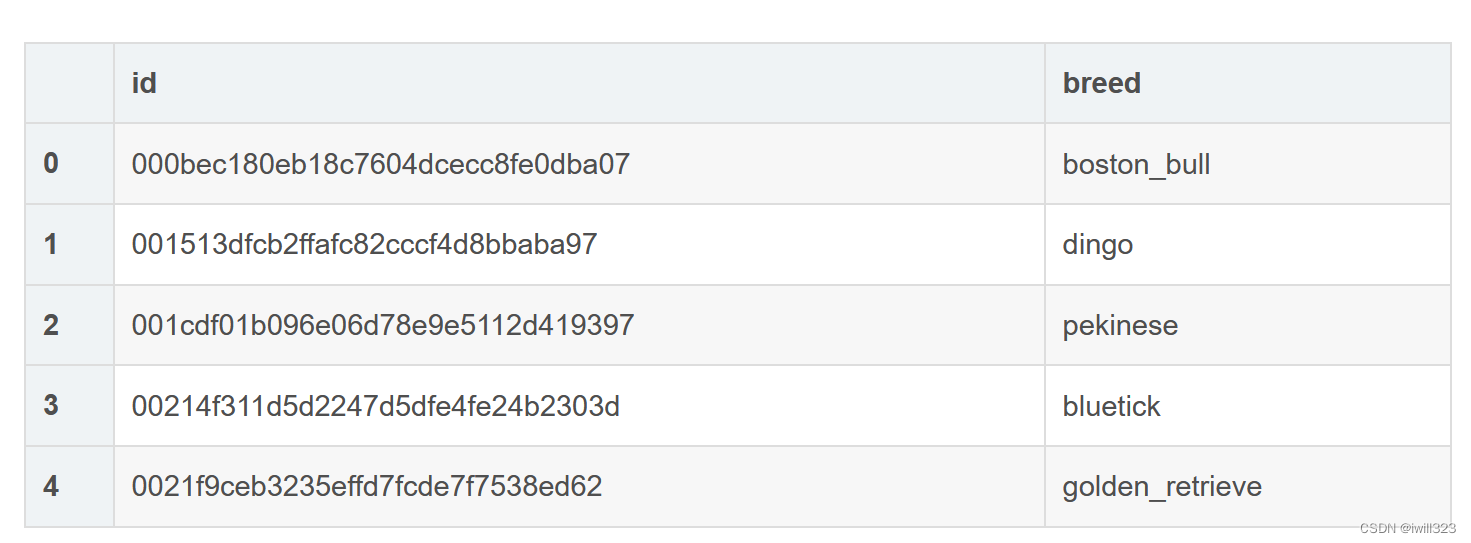
- 标签个数
breeds = df.breed.unique()
len(breeds)120
- 训练集中每个种类的样本有多少
count_train = collections.Counter(df['breed'])
count_train.most_common() [('scottish_deerhound', 126),('maltese_dog', 117),('afghan_hound', 116),……('komondor', 67),('brabancon_griffon', 67),('eskimo_dog', 66),('briard', 66)]
torchvision.datasets.ImageFolder()
数据集整理
思路
torchvision.datasets.ImageFolder()要求根目录下建立分类标签子文件夹,每个子文件夹下归档对应标签的图片,因此需要给每个标签建立文件夹,并且遍历样本,将每个样本复制到对应的文件夹中。本例在归档图片的时候,顺便把数据集划分了
根据图片名读标签
为了在根目录下按类别建立子文件夹,需要在读取每个样本图片名的时候,获得对应的类别标签label。然而,pandas一般根据表的index或者行数来选择数据,我没找到根据某一列的值索引其他列的数据的方法。教程根据一列的数据索引另一列的数据,下面的read_csv_labels()函数起到这样的作用,read_csv_labels函数返回的是一个字典格式的变量,该变量根据name可以索引label。
def read_csv_labels(fname):"""读取fname来给标签字典返回一个文件名"""with open(fname, 'r') as f:# 跳过文件头行(列名)lines = f.readlines()[1:]tokens = [l.rstrip().split(',') for l in lines]return dict(((name, label) for name, label in tokens))建立标签子文件夹
copyfile函数将图片从原位置filename复制到对应文件夹之下,只需要将target_dir指定为标签文件夹名字就行。
def copyfile(filename, target_dir):"""将文件复制到目标目录"""os.makedirs(target_dir, exist_ok=True) # 文件夹不存在则创建shutil.copy(filename, target_dir)数据集划分
数据集只含有train和test数据集,而我们在训练的时候,一般还包含验证集,所以要划分出验证集处理。使用Google Colab这样的平台时,我们经常会将训练集、测试集、验证集压缩并上传,所以有时候要将它们划分、保存在不同的文件夹。
- 定义
reorg_train_valid函数来将验证集从原始的训练集中拆分出来。 此函数中的参数valid_ratio是验证集中的样本数与原始训练集中的样本数之比。 更具体地说,令n等于样本最少的类别中的图像数量,而r是比率。 验证集将为每个类别拆分出max(⌊nr⌋,1)张图像。以valid_ratio=0.1为例,由于原始的训练集有50000张图像,因此train_valid_test/train路径中将有45000张图像用于训练,而剩下5000张图像将作为路径train_valid_test/valid中的验证集。 - 定义reorg_test函数将测试集数据复制到新文件夹,注意test文件夹下面也要有一个子文件夹(unknown)作为分类文件夹,否则torchvision.datasets.ImageFolder()会报错。因为ImageFolder()的find_classes()函数要从根文件夹下读取文件夹的名称,生成类别列表,没有这个列表就会导致错误
def reorg_train_valid(data_dir, labels, valid_ratio):"""将验证集从原始的训练集中拆分出来"""# 训练数据集中样本最少的类别中的样本数n = collections.Counter(labels.values()).most_common()[-1][1]# 验证集中每个类别的样本数n_valid_per_label = max(1, math.floor(n * valid_ratio))label_count = {}for train_file in os.listdir(os.path.join(data_dir, 'train')):label = labels[train_file.split('.')[0]] # 根据文件名索引labelfname = os.path.join(data_dir, 'train', train_file)copyfile(fname, os.path.join(data_dir, 'train_valid_test','train_valid', label))if label not in label_count or label_count[label] < n_valid_per_label:copyfile(fname, os.path.join(data_dir, 'train_valid_test','valid', label))label_count[label] = label_count.get(label, 0) + 1else:copyfile(fname, os.path.join(data_dir, 'train_valid_test','train', label))return n_valid_per_labeldef reorg_test(data_dir):"""在预测期间整理测试集,以方便读取"""for test_file in os.listdir(os.path.join(data_dir, 'test')):copyfile(os.path.join(data_dir, 'test', test_file),os.path.join(data_dir, 'train_valid_test', 'test','unknown'))调用数据集处理函数
labels.values()的格式是<class 'builtin_function_or_method'>,可以用于collections.Counter()方法
def reorg_cifar10_data(data_dir, label_csv, valid_ratio):labels = read_csv_labels(os.path.join(data_dir, label_csv))reorg_train_valid(data_dir, labels, valid_ratio)reorg_test(data_dir)batch_size = 128
valid_ratio = 0.1
reorg_cifar10_data(data_dir, label_csv, valid_ratio)代码执行的效果是,创建了四个文件夹,分别是test,train(9502个样本),valid(720个样本)和train_valid,其中train_valid是train和valid的合集。建立train_valid文件夹是因为,使用验证集筛选出最佳超参数之后,再使用train_valid训练一遍,得到最终模型
每一个文件夹下按照类别创建了120个分类文件夹,这是torchvision.datasets.ImageFolder()函数的要求。
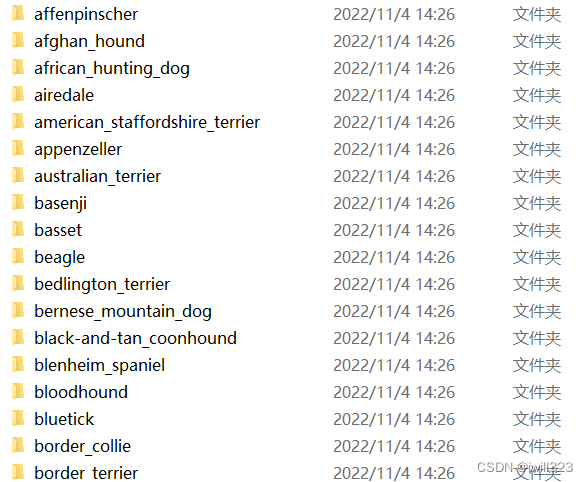
读取数据集
读取由原始图像组成的数据集,每个样本都包括一张图片和一个标签。注意,当验证集在超参数调整过程中用于模型评估时,不应引入图像增广的随机性,所以valid数据集使用的transform是transform_test
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train_valid_test', folder),transform=train_transform) for folder in ['train', 'train_valid']]valid_ds, test_ds = [torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train_valid_test', folder),transform=test_transform) for folder in ['valid', 'test']]train_iter, train_valid_iter = [torch.utils.data.DataLoader(dataset, batch_size, shuffle=True, drop_last=True)for dataset in (train_ds, train_valid_ds)]valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size, shuffle=False,drop_last=True)test_iter = torch.utils.data.DataLoader(test_ds, batch_size, shuffle=False,drop_last=False)其中用到的图像增广:
img_size = 224 # 也可以是其他值
train_transform = transforms.Compose([ transforms.RandomResizedCrop(img_size, ratio=(3.0/4.0, 4.0/3.0)),transforms.RandomHorizontalFlip(),transforms.RandomRotation(30),transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])test_transform = transforms.Compose([transforms.Resize(img_size),transforms.CenterCrop(img_size),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
torchvision.datasets.ImageFolder()源码及解读
源码
ImageFolder是一个叫做DatasetFolder类的子类
IMG_EXTENSIONS = (".jpg", ".jpeg", ".png", ".ppm", ".bmp", ".pgm", ".tif", ".tiff", ".webp")def pil_loader(path: str) -> Image.Image: # 根据地址读取图像 with open(path, "rb") as f:img = Image.open(f)return img.convert("RGB")class ImageFolder(DatasetFolder): def __init__(self,root: str,transform: Optional[Callable] = None,target_transform: Optional[Callable] = None,loader: Callable[[str], Any] = default_loader,is_valid_file: Optional[Callable[[str], bool]] = None,):super().__init__(root,loader,IMG_EXTENSIONS if is_valid_file is None else None,transform=transform,target_transform=target_transform,is_valid_file=is_valid_file,)self.imgs = self.samples
loder是上面定义函数pil_loader()的引用,该函数的作用是根据传入的图像地址进行图像读取;IMG_EXTENSIONS定义了读取图像文件的扩展名类型。其余在调用父类__init__方法时传入的参数在最外面就已经传入,包括root表示路径、transform表示要对图像进行的变换。(看第一段代码传入的参数)
接下来看DatasetFolder类的定义(源码):
class DatasetFolder(VisionDataset):def __init__(self,root: str,loader: Callable[[str], Any],extensions: Optional[Tuple[str, ...]] = None,transform: Optional[Callable] = None,target_transform: Optional[Callable] = None,is_valid_file: Optional[Callable[[str], bool]] = None,) -> None:super().__init__(root, transform=transform, target_transform=target_transform)classes, class_to_idx = self.find_classes(self.root)samples = self.make_dataset(self.root, class_to_idx, extensions, is_valid_file)self.loader = loaderself.extensions = extensionsself.classes = classesself.class_to_idx = class_to_idxself.samples = samplesself.targets = [s[1] for s in samples]@staticmethoddef make_dataset(directory: str,class_to_idx: Dict[str, int],extensions: Optional[Tuple[str, ...]] = None,is_valid_file: Optional[Callable[[str], bool]] = None,) -> List[Tuple[str, int]]: if class_to_idx is None:raise ValueError("The class_to_idx parameter cannot be None.")return make_dataset(directory, class_to_idx, extensions=extensions, is_valid_file=is_valid_file)def find_classes(self, directory: str) -> Tuple[List[str], Dict[str, int]]:return find_classes(directory)def __getitem__(self, index: int) -> Tuple[Any, Any]:path, target = self.samples[index]sample = self.loader(path)if self.transform is not None:sample = self.transform(sample)if self.target_transform is not None:target = self.target_transform(target)return sample, targetdef __len__(self) -> int:return len(self.samples)下面是用到的辅助函数的源码
- has_file_allowed_extension函数的功能是根据文件名判断该文件是否具有所需图像类型扩展名的后缀
- find_classes函数的功能是根据输入的存放图像的文件夹地址,得到文件夹下面有几种图像,为每种图像分配一个数字
make_dataset函数会根据地址、图像种类字典以及扩展名列表得到一个列表:(path_to_sample, class)
def has_file_allowed_extension(filename: str, extensions: Union[str, Tuple[str, ...]]) -> bool:return filename.lower().endswith(extensions if isinstance(extensions, str) else tuple(extensions))# Checks if a file is an allowed image extension
def is_image_file(filename: str) -> bool:return has_file_allowed_extension(filename, IMG_EXTENSIONS)def find_classes(directory: str) -> Tuple[List[str], Dict[str, int]]: classes = sorted(entry.name for entry in os.scandir(directory) if entry.is_dir())if not classes:raise FileNotFoundError(f"Couldn't find any class folder in {directory}.")class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}return classes, class_to_idxdef make_dataset(directory: str,class_to_idx: Optional[Dict[str, int]] = None,extensions: Optional[Union[str, Tuple[str, ...]]] = None,is_valid_file: Optional[Callable[[str], bool]] = None,
) -> List[Tuple[str, int]]: directory = os.path.expanduser(directory)if class_to_idx is None:_, class_to_idx = find_classes(directory)elif not class_to_idx:raise ValueError("'class_to_index' must have at least one entry to collect any samples.")both_none = extensions is None and is_valid_file is Noneboth_something = extensions is not None and is_valid_file is not Noneif both_none or both_something:raise ValueError("Both extensions and is_valid_file cannot be None or not None at the same time")if extensions is not None:def is_valid_file(x: str) -> bool:return has_file_allowed_extension(x, extensions) # type: ignore[arg-type]is_valid_file = cast(Callable[[str], bool], is_valid_file)instances = []available_classes = set()for target_class in sorted(class_to_idx.keys()):# 第1个for读取类别名称,进入了每个类文件夹中class_index = class_to_idx[target_class]target_dir = os.path.join(directory, target_class)if not os.path.isdir(target_dir):continuefor root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):# 第2个for深度遍历每个类文件夹及其子文件夹,fnames是这些文件夹内的文件for fname in sorted(fnames):# 第3个for读取每个文件的文件名path = os.path.join(root, fname)if is_valid_file(path):item = path, class_indexinstances.append(item)if target_class not in available_classes:available_classes.add(target_class)empty_classes = set(class_to_idx.keys()) - available_classesif empty_classes:msg = f"Found no valid file for the classes {', '.join(sorted(empty_classes))}. "if extensions is not None:msg += f"Supported extensions are: {extensions if isinstance(extensions, str) else ', '.join(extensions)}"raise FileNotFoundError(msg)return instances
解读
源码有些复杂,下面是简化版本:
def find_classes(dir):classes = [d for d in os.listdir(dir) if os.path.isdir(os.path.join(dir, d))]classes.sort()class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}return classes, class_to_idxdef make_dataset(directory, class_to_idx, extensions) : directory = os.path.expanduser(directory)instances = []available_classes = set()for target_class in sorted(class_to_idx.keys()):# 第1个for读取类别名称,进入了每个类文件夹中class_index = class_to_idx[target_class]target_dir = os.path.join(directory, target_class)if not os.path.isdir(target_dir):continuefor root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):# 第2个for深度遍历每个类文件夹及其子文件夹,fnames是这些文件夹内的文件for fname in sorted(fnames):# 第3个for读取每个文件的文件名path = os.path.join(root, fname)if has_file_allowed_extension(path, IMG_EXTENSIONS):item = path, class_indexinstances.append(item)if target_class not in available_classes:available_classes.add(target_class)# 如果有的类型没找到对应的文件,就报错empty_classes = set(class_to_idx.keys()) - available_classesif empty_classes:msg = f"Found no valid file for the classes {', '.join(sorted(empty_classes))}. "if extensions is not None:msg += f"Supported extensions are: {extensions if isinstance(extensions, str) else ', '.join(extensions)}"raise FileNotFoundError(msg)return instancesIMG_EXTENSIONS = (".jpg", ".jpeg", ".png", ".ppm", ".bmp", ".pgm", ".tif", ".tiff", ".webp")def has_file_allowed_extension(filename, extensions):return filename.lower().endswith(extensions if isinstance(extensions, str) else tuple(extensions))用到了os.walk()函数,可以参考os.walk()的详细理解(秒懂)_不堪沉沦的博客-CSDN博客_os.walk()
>>classes, class_to_idx = find_classes(os.path.join(data_dir, 'train_valid_test', 'train'))
>>classes
(['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'],
>>class_to_idx
{'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9})
>>samples = make_dataset(os.path.join(data_dir, 'train_valid_test', 'train'), class_to_idx, IMG_EXTENSIONS)
>>samples[:4]
[('.\\data\\cifar-10\\train_valid_test\\train\\airplane\\14469.png', 0),
('.\\data\\cifar-10\\train_valid_test\\train\\airplane\\14480.png', 0),
('.\\data\\cifar-10\\train_valid_test\\train\\airplane\\14483.png', 0),
('.\\data\\cifar-10\\train_valid_test\\train\\airplane\\14487.png', 0)]
从输出结果可以看出:
- classes是由存放每类图像的文件夹名字组成的列表;
- class_to_idx是由每种图像的类名和为其分配的数字组成的键值对所组成的字典;
- samples是由个数与所有类图像总个数相等的元组组成的列表,元组里面的内容就对应了每张图像的地址以及它的分类编号。
有了这些信息,就能够通过__getitem__方法中的前两句代码:
path, target = self.samples[index]
sample = self.loader(path)获取到图像和其对应分类了。并且,从代码中可以看出,ImageFolder读取每个文件夹的文件时,都要先排序一下。这就解释了读取测试集时,样本的顺序是什么样的了 。
torchvision.datasets.ImageFolder()的特点
- 每一个元素是一个元祖
>>len(train_ds)
45000
>>type(train_ds[0]) # train_ds的每一个元素是一个元祖
<class 'tuple'>
- torchvision.datasets.ImageFolder()方法自动将字符类型的label转变为int类型:
>>train_ds[0][0].shape # 元祖第一个元素是图片向量
torch.Size([3, 32, 32])
>>train_ds[0][1] # 元祖第二个元素是int类型的标签
0
- 经过torchvision.datasets.ImageFolder()处理,数据集自动产生了类别这一属性:
>>train_ds.classes
['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
- ImageFolder()读取样本的顺序是按照str顺序排序的
手写ImageFolder()
下面手写一个dataset,和ImageFolder()起到同样的作用
class AdvDataset(Dataset):def __init__(self, data_dir, transform):self.images = []self.labels = []self.names = []'''data_dir├── class_dir│ ├── class1.png│ ├── ...│ ├── class20.png'''for i, class_dir in enumerate(sorted(glob.glob(f'{data_dir}/*'))):images = sorted(glob.glob(f'{class_dir}/*'))self.images += imagesself.labels += ([i] * len(images)) # 第i个读到的类文件夹,类别就是iself.names += [os.path.relpath(imgs, data_dir) for imgs in images] # 返回imgs相对于data_dir的相对路径self.transform = transformdef __getitem__(self, idx):image = self.transform(Image.open(self.images[idx]))label = self.labels[idx]return image, labeldef __getname__(self):return self.namesdef __len__(self):return len(self.images)adv_set = AdvDataset(root, transform=transform)
adv_names = adv_set.__getname__()
adv_loader = DataLoader(adv_set, batch_size=batch_size, shuffle=False)print(f'number of images = {adv_set.__len__()}')自定义数据集
某种意义上就是把ImageFolder()手写了一遍
数据集处理
读取训练图像的标签文件:
df = pd.read_csv(os.path.join(data_dir, label_csv))
df.head()| id | breed | |
|---|---|---|
| 0 | 000bec180eb18c7604dcecc8fe0dba07 | boston_bull |
| 1 | 001513dfcb2ffafc82cccf4d8bbaba97 | dingo |
| 2 | 001cdf01b096e06d78e9e5112d419397 | pekinese |
| 3 | 00214f311d5d2247d5dfe4fe24b2303d | bluetick |
| 4 | 0021f9ceb3235effd7fcde7f7538ed62 | golden_retrieve |
标签breed是str类型,需要转成int类型
将标签转换成为int类型
得到种类列表breeds,根据breeds创建“类别-序号”的字典,然后由breed列得到数字标签列label_idx。
breeds = df.breed.unique() # 长度是120,即类别数
breeds.sort()
breed2idx = dict((breed, i) for i, breed in enumerate(breeds))
df['label_idx'] = [breed2idx[b] for b in df.breed]在排序之前,breeds:
array(['boston_bull', 'dingo', 'pekinese', 'bluetick', 'golden_retriever',……])
列表中元素的顺序是他们在df.breed中出现的顺序,这样boston_bull对应编号0,dingo对应编号1,以此类推。一般希望种类按照正常顺序排,所以可以做一下排序,得到的df:
id breed label_idx 0 000bec180eb18c7604dcecc8fe0dba07 boston_bull 19 1 001513dfcb2ffafc82cccf4d8bbaba97 dingo 37 2 001cdf01b096e06d78e9e5112d419397 pekinese 85 ... ... ... ... 10219 ffe2ca6c940cddfee68fa3cc6c63213f airedale 3 10220 ffe5f6d8e2bff356e9482a80a6e29aac miniature_pinscher 75 10221 fff43b07992508bc822f33d8ffd902ae chesapeake_bay_retriever 28
自定义数据集函数
df中保存了样本名和对应的标签,使用df可以从训练集文件夹(需要路径img_path)中读取图片并处理,返回图片和对应的标签
class DogDataset(Dataset):def __init__(self, df, img_path, transform=None):self.df = dfself.img_path = img_pathself.transform = transformdef __len__(self):return self.df.shape[0]def __getitem__(self, idx):path = os.path.join(self.img_path, self.df.id[idx]) + '.jpg' img = Image.open(path)if self.transform:img = self.transform(img)label = self.df.label_idx[idx]return img, label 对于测试集,没有df可用,需要用os.listdir()获得图片名列表,然后从该列表中根据idx获取图片名。注意要对图片名列表进行排序,这样才能在保存预测结果的时候,将(排序后的)图片名和模型输出的预测结果对应上
class DogDatasetTest(Dataset):def __init__(self, img_path, transform=None): self.img_path = img_pathself.img_list = os.listdir(img_path)self.img_list.sort()self.transform = transformdef __len__(self):return len(self.img_list)def __getitem__(self, idx):path = os.path.join(self.img_path, self.img_list[idx])img = Image.open(path)if self.transform: img = self.transform(img)return img读取数据集
train_val_df = df
train_val_dataset = DogDataset(train_val_df, os.path.join(data_dir, 'train'), train_transform)
test_dataset = DogDatasetTest(os.path.join(data_dir, 'test'), test_transform)batch_size = 32
train_val_iter = DataLoader(train_val_dataset, batch_size, shuffle=True, drop_last = True)
test_iter = DataLoader(test_dataset, batch_size, shuffle=False, drop_last = False)数据集划分函数
train_test_split函数
用法
train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train data和test data
X_train, X_test, y_train, y_test = train_test_split(train_data,train_target,test_size=None,train_size=None,random_state=None,shuffle=True,stratify=None, )
train_data:所要划分的样本特征集
train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量
random_state:是随机数的种子。其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。如果想要要每次运行都不一样,方法是不设置参数random_state,每次切分的比例虽然相同,但是切分的结果不同。
from sklearn.model_selection import train_test_split
train_id, val_id, train_breed, val_breed= train_test_split(df.id.values, df.breed.values, test_size=0.1)>>len(val_id)
1023
>>len(train_id)
9199
>>val_id
['890efbec7147c2887c460be0af763381' 'c7441fba1f18864b59b1d474936def91''63dd3e15f7fe4b3b3e9a69530e8d36b3' ... 'e24af0affe6c7a51b3e8ed9c30b090b7''3d78ff549552e90b9a01eefb12548283' 'cc7ae3da3bebcc4acb10128078cdf29a']
注意该函数得到的结果是表中的id这一列,而不是index
读取数据集
train_df = pd.DataFrame({'id':train_id})
train_df['label_idx'] = [breed2idx[breed] for breed in train_breed]
val_df = pd.DataFrame({'id':val_id})
val_df['label_idx'] = [breed2idx[breed] for breed in val_breed]
train_dataset = DogDataset(train_df, os.path.join(data_dir, 'train'), train_transform)
val_dataset = DogDataset(val_df, os.path.join(data_dir, 'train'), test_transform) 存在的问题
计算一下每个种类在验证集和训练集中的比例
train_id, val_id, train_breed, val_breed= train_test_split(df.id.values, df.breed.values, test_size=0.1, random_state=42)
count_train = collections.Counter(df['breed'])
df_val = pd.DataFrame({'breed':val_breed})
count_val = collections.Counter(df_val['breed'])
ratio = []
for i in count_train:ratio.append(count_train[i]/ count_val[i])print(min(ratio), max(ratio))4.944444444444445 47.0
可以发现,数据集的划分没有考虑每个种类在训练集中相对多少。
参考:train_test_split()函数_鹏大大大的博客-CSDN博客_train_test_split
StratifiedShuffleSplit函数
对数据集进行分析可以发现,样本最多的种类几乎是样本最少的种类的两倍。如果使用torchvision.datasets.ImageFolder()例子的处理方法,从训练集中抽取的每个种类的样本数量都一样,结果就是验证集和训练集的样本分布不一致。有时候希望,训练集中,样本数量多的种类多抽走一些,样本数量少的种类少抽走一些。这种情况下可以使用StratifiedShuffleSplit函数,将验证集从训练集中划出,得到的结果是df的子集train_df 和val_df。
StratifiedShuffleSplit和train_test_split都来自sklearn.model_selection模块,都用于数据集的划分(将训练集划分为训练集和验证集),区别在于一个是分层抽样,一个是随机抽样。可以参考
StratifiedShuffleSplit()函数的详细理解_wang_xuecheng的博客-CSDN博客_stratifiedshufflesplit,这里给出直观的结果
用法
StratifiedShuffleSplit(n_splits=10,*,test_size=None,train_size=None,random_state=None, )
n_splits代表将数据集分成多少训练集-验证集对, test_size代表验证集比例。下面的代码将数据集df进行一次划分,验证集占10%。
from sklearn.model_selection import StratifiedShuffleSplit
stratified_split = StratifiedShuffleSplit(n_splits=1, test_size=0.1, random_state=0)
splits = stratified_split.split(df.id, df.breed)
train_split_id, val_split_id = next(iter(splits)) >>train_split_id.shape
(9199,)
>>val_split_id.shape
(1023,)
>>train_split_id
[9556 2055 5652 ... 7133 366 4846]
读取数据集
train_df = df.iloc[train_split_id].reset_index()
val_df = df.iloc[val_split_id].reset_index()train_dataset = DogDataset(train_df, os.path.join(data_dir, 'train'), train_transform)
val_dataset = DogDataset(val_df, os.path.join(data_dir, 'train'), test_transform) batch_size = 32
train_iter = DataLoader(train_dataset, batch_size, shuffle=False, drop_last = True)
val_iter = DataLoader(val_dataset, batch_size, shuffle=False, drop_last = True)为什么要进行reset_index()操作
注意划分完数据集后,均进行了reset_index()操作。对于train_df ,reset_index()之前:
id breed label_idx 9556 efbabde6fc97bb48c8c8b6b75bfaea59 eskimo_dog 78 2055 332c413119b474653ecca0f358c85e1f giant_schnauzer 29 5652 8e7256b23446acbd33967122787c1eb3 tibetan_mastiff 116
reset_index()之后
index id breed label_idx 0 9556 efbabde6fc97bb48c8c8b6b75bfaea59 eskimo_dog 78 1 2055 332c413119b474653ecca0f358c85e1f giant_schnauzer 29 2 5652 8e7256b23446acbd33967122787c1eb3 tibetan_mastiff 116
如果不重设index,那么DataLoader会报错。使用train_df创建数据集train_dataset之后,运行以下命令
>>for i in range(100):train_dataset[i]
该命令会在train_dataset[12]这个地方报错
查看train_df和val_df的index:
>>train_df.index.sort_values()[0:25]
Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17,18, 19, 20, 21, 22, 24, 25, 27],dtype='int64')
>>val_df.index.sort_values()[0:25]
Int64Index([ 12, 23, 26, 36, 46, 53, 67, 70, 75, 80, 102, 103, 110,121, 122, 125, 133, 137, 145, 154, 165, 169, 177, 181, 209],dtype='int64')
train_df中没有12这个index,DataLoader从train_dataset中取出第12元素的时候出错。进行reset_index()操作后就不会有问题了。
探析
train_split_id是划分出来的训练集在原数据集中的索引。其实只需要df.id,甚至只需要样本长度就行了,为什么StratifiedShuffleSplit函数也使用了breed这一列?
下面看一下每个种类在验证集和训练集中的比例
df_val = df.iloc[val_split_id]
count_val = collections.Counter(df_val['breed'])
count_train = collections.Counter(df['breed'])
ratio = []
for i in count_train:ratio.append(count_val[i] / count_train[i])print(min(ratio), max(ratio))0.09333333333333334 0.10606060606060606
基本上都在0.1左右。这就是StratifiedShuffleSplit使用了breed这一列的原因。
并且,无论random_state的值是什么,上面算出来的比例都是不变的。如果random_state的值设定为一个固定的值,观察df_val的前几项可以发现,它们是不变的;如果random_state的值改变了,那么df_val的前几项也会变成另一个样子。可见,这种划分是一种规律性的划分。
random_split()
用法
torch.utils.data.random_split(dataset, lengths, generator=<torch._C.Generator object>)
随机将一个数据集分割成给定长度的不重叠的新数据集。可选择固定生成器以获得可复现的结果(效果同设置随机种子)。
dataset(Dataset) – 要划分的数据集。lengths(sequence) – 要划分的长度。generator(Generator) – 用于随机排列的生成器。
from torch.utils.data import random_splita = torch.arange(20)
x, y = random_split(a, [8,12])
print(x, y)
print(np.array(x))<torch.utils.data.dataset.Subset object at 0x000002338056D2C8> <torch.utils.data.dataset.Subset object at 0x000002338056D308> [ 4 19 16 14 10 3 5 7]
在使用torch.utils.data.dataset.random_split后,生成同属于Dataset类型的Subset类,
根据pytorch官网torch.utils.data — PyTorch 1.13 documentation,length可以是一个比例:
If a list of fractions that sum up to 1 is given, the lengths will be computed automatically as floor(frac * len(dataset)) for each fraction provided.
After computing the lengths, if there are any remainders, 1 count will be distributed in round-robin fashion to the lengths until there are no remainders left.
还给出了一个例子:
random_split(range(30), [0.3, 0.3, 0.4], generator=torch.Generator().manual_seed(42))
但是运行起来出错
划分
valid_set_size = int(valid_ratio * len(df))
train_set_size = len(df) - valid_set_size
train_set, valid_set = random_split(df.values, [train_set_size, valid_set_size], generator=torch.Generator().manual_seed(99))
train_array = np.array(train_set)
valid_array = np.array(valid_set)
print(train_array.shape, valid_array.shape)(9200, 3) (1022, 3)
看一下valid_array:
array([['29743dcc4d439615133f2024b50aab15', 'lhasa', 70],['516e9ca19a0fd6c7eb5aa8566b249cb8', 'bloodhound', 14],...,['481f8e13336be2292ba30c45d14daf55', 'saluki', 93],['e4f17a9e5ee1ed5385744cd6e8916a4e', 'bernese_mountain_dog', 11]],dtype=object)
读取数据集
random_split返回的数据,经过处理后是numpy.ndarray格式,要想用在自定义的数据集上,需要用pandas处理一下
train_df = pd.DataFrame({'id':train_array[:, 0],'breed':train_array[:, 1], 'label_idx':train_array[:, 2]})
valid_df = pd.DataFrame({'id':valid_array[:, 0],'breed':valid_array[:, 1], 'label_idx':valid_array[:, 2]})train_dataset = DogDataset(train_df, os.path.join(data_dir, 'train'), train_transform)
val_dataset = DogDataset(val_df, os.path.join(data_dir, 'train'), test_transform) batch_size = 32
train_iter = DataLoader(train_dataset, batch_size, shuffle=False, drop_last = True)
val_iter = DataLoader(val_dataset, batch_size, shuffle=False, drop_last = True)探析
看一看划分结果,发现和train_test_split函数有些类似,划分结果受seed的影响,不同的种子导致不同的划分结果,并且没有使不同分类的抽取比例一致
count_train = collections.Counter(df['breed'])
count_valid = collections.Counter(valid_df['breed'])
ratio = []
for i in count_train:ratio.append(count_val[i] / count_train[i])print(min(ratio), max(ratio))0.043478260869565216 0.17582417582417584
其他dataset
TensorDataset
torch.utils.data 中的 TensorDataset 基于一系列张量构建数据集。这些张量的形状可以不尽相同,但第一个维度必须具有相同大小,这是为了保证在使用 DataLoader 时可以正常地返回一个批量的数据。
TensorDataset 中的参数必须是 tensor
源码
class TensorDataset(Dataset[Tuple[Tensor, ...]]):r"""Dataset wrapping tensors.Each sample will be retrieved by indexing tensors along the first dimension.Args:*tensors (Tensor): tensors that have the same size of the first dimension."""tensors: Tuple[Tensor, ...]def __init__(self, *tensors: Tensor) -> None:assert all(tensors[0].size(0) == tensor.size(0)for tensor in tensors), "Size mismatch between tensors"self.tensors = tensorsdef __getitem__(self, index):return tuple(tensor[index] for tensor in self.tensors)def __len__(self):return self.tensors[0].size(0)
*tensors告诉我们实例化TensorDataset时传入的是一系列张量,即:
dataset = TensorDataset(tensor_1, tensor_2, ..., tensor_n)
assert是用来确保传入的这些张量中,每个张量在第一个维度的大小都等于第一个张量在第一个维度的大小,即要求所有张量在第一个维度的大小都相同。- __getitem__ 方法返回的结果等价于
return tensor_1[index], tensor_2[index], ..., tensor_n[index]
从这行代码可以看出,如果 n 个张量在第一个维度的大小不完全相同,则必然会有一个张量出现 IndexError。确保第一个维度大小相同也是为了之后传入 DataLoader 中能够正常地以一个批量的形式加载。
- __len__ 因为所有张量的第一个维度大小都相同,所以直接返回传入的第一个张量在第一个维度的大小即可。
建立数据集
from torch.utils import datafeatures = torch.tensor([
[ 0, 1, 2],
[ 1, 2, 3],
[ 2, 3, 4],
[ 3, 4, 5],
[ 4, 5, 6],
[ 5, 6, 7]], dtype=torch.int32)
label = torch.arange(6)
train_dataset = data.TensorDataset(features, label)
train_dataset[0](tensor([0, 1, 2], dtype=torch.int32), tensor(0))
使用dataloader
train_iter = data.DataLoader(train_dataset, 3, shuffle=False)
for data, label in train_iter:print(data, label)tensor([[0, 1, 2],[1, 2, 3],[2, 3, 4]], dtype=torch.int32) tensor([0, 1, 2]) tensor([[3, 4, 5],[4, 5, 6],[5, 6, 7]], dtype=torch.int32) tensor([3, 4, 5])
一个问题:对单个tensor进行包装
如果是对测试集数据进行包装,那么包装对象只有一个tensor,比如下面的features
train_dataset = TensorDataset(features)
print(train_dataset[0])
train_iter = DataLoader(train_dataset, 3, shuffle=False)
for data in train_iter:print(data)数据集的第一个元素如下,可以发现还是一个元祖,只不过该元组也只有一个元素
(tensor([0, 1, 2], dtype=torch.int32),)
dataloader迭代出的数据如下,可以发现tensor被list包裹住了,这是一个问题,比如预测函数中,取出data后写成data = data.to(device)就不行了,因为data是list。没想到太好的办法,到时候写成data = data[0].to(device)吧
[tensor([[0, 1, 2],[1, 2, 3],[2, 3, 4]], dtype=torch.int32)] [tensor([[3, 4, 5],[4, 5, 6],[5, 6, 7]], dtype=torch.int32)]
参考:一文搞懂PyTorch中的TensorDataset_Lareges的博客-CSDN博客_tensordataset
TensorDataset_anshiquanshu的博客-CSDN博客_tensordataset
这篇关于数据集读取与划分,ImageFolder(),自定义数据集,TensorDataset,StratifiedShuffleSplit的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






