本文主要是介绍leetcodeT912-快排优化-三路划分,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
leetcodeT912-快排优化-三路划分
- 1.前言
- 2.为什么需要三路划分的优化?
- 3.三路划分的思想及举例画图
- 4.三路划分的代码实现
- 5.三数取中修改
1.前言

因为快排的名声太大
并且快排在某些场景下比较慢,所以leetcode"修理"了一下快排
特意设计了一些专门针对快排的测试用例
所以用快排过不了这一题
2.为什么需要三路划分的优化?
我们遇到了第一个为难快排的测试用例全是重复值2
我们发现快排在遇到全是重复值的数据时,
这里以左右指针法为例
每次右指针从右向左找小时都要跑到左指针位置处
然后进行交换,递归
每次都只能把那个重复数据2放到当前递归区间的起始位置,就像是冒泡排序一样每次只能冒一个数到对应位置,但是冒泡排序好歹还能有一个优化(没有发生数据交换时即为有序,排序结束),可是这时快排连优化都没有
退化到了O(n^2)的时间复杂度
3.三路划分的思想及举例画图
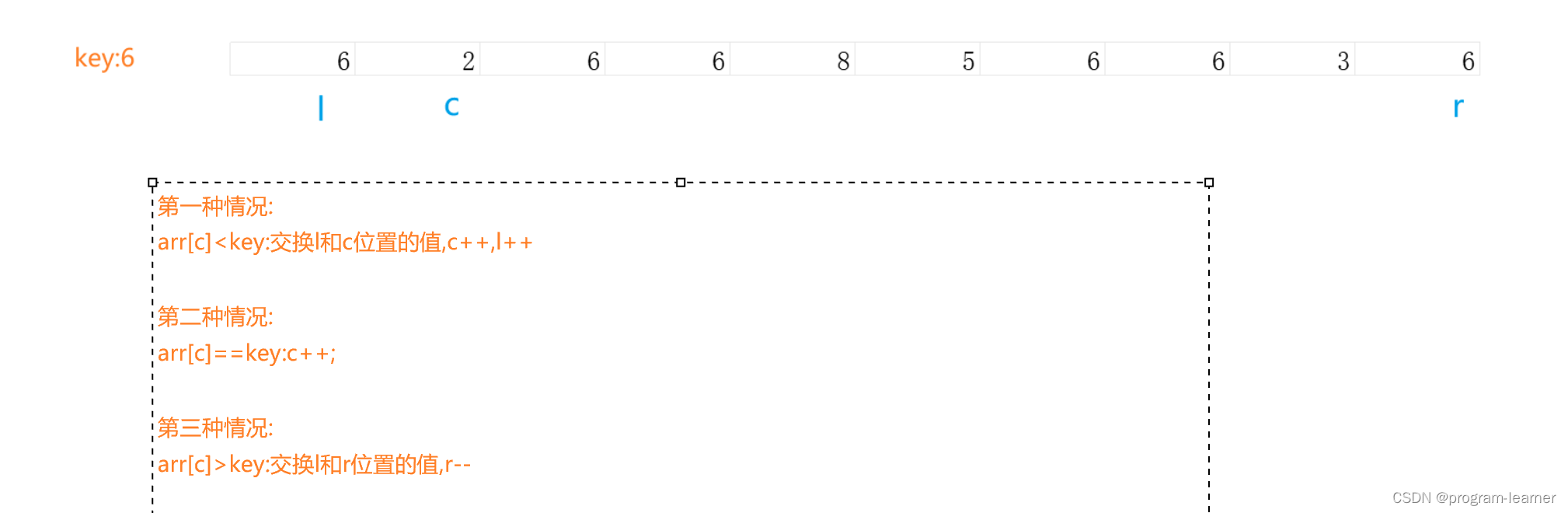
这是整个过程,大家也可以自己对照三种情况画一下

一趟三路划分
前:

后:

我们发现:
一趟三路划分后整个数组被分为三个部分:
假设区间左端点:begin,右端点:end
[begin,l-1]:这一段上区间的值小于key
[l,r] :这一段上区间的值等于key
[r+1,end]:这一段上区间的值大于key
等于key的那一段区间不需要递归了,因为它们已经位于它们该在的地方了
接下来只需要递归[begin,l-1],[r+1,end]即可
4.三路划分的代码实现
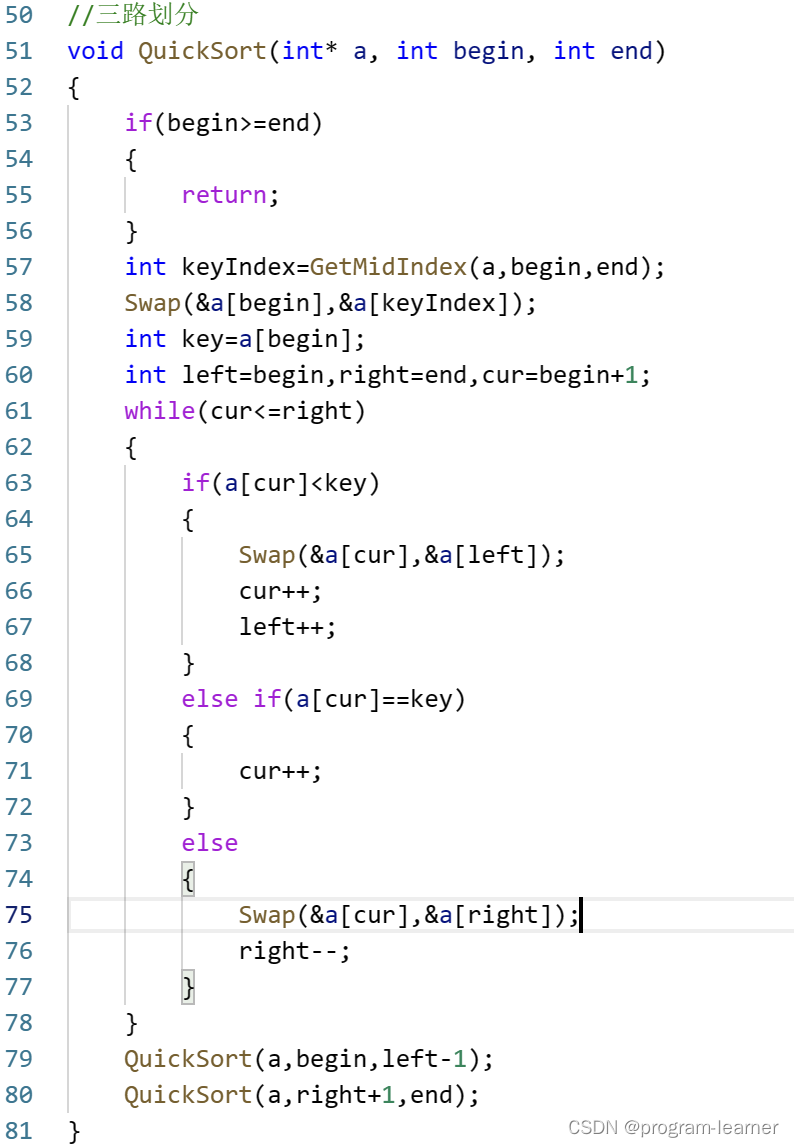
//三路划分
void QuickSort(int* a, int begin, int end)
{if(begin>=end){return;}int keyIndex=GetMidIndex(a,begin,end);Swap(&a[begin],&a[keyIndex]);int key=a[begin];int left=begin,right=end,cur=begin+1;while(cur<=right){if(a[cur]<key){Swap(&a[cur],&a[left]);cur++;left++;}else if(a[cur]==key){cur++;}else{Swap(&a[cur],&a[right]);right--;}}QuickSort(a,begin,left-1);QuickSort(a,right+1,end);
}
所以我们可以发现,三路划分之后,数组中重复越多,我们快排就越快
因为重复值直接就跳过了
对于那个测试用例来说
第一趟排序之后left还是等于begin,right还是等于end
所以再往下递归就会触发begin>=end这个条件,就会直接返回
所以达到了O(n)的时间复杂度
所以对于这个测试用例来说已经比较快了
5.三数取中修改
但是:
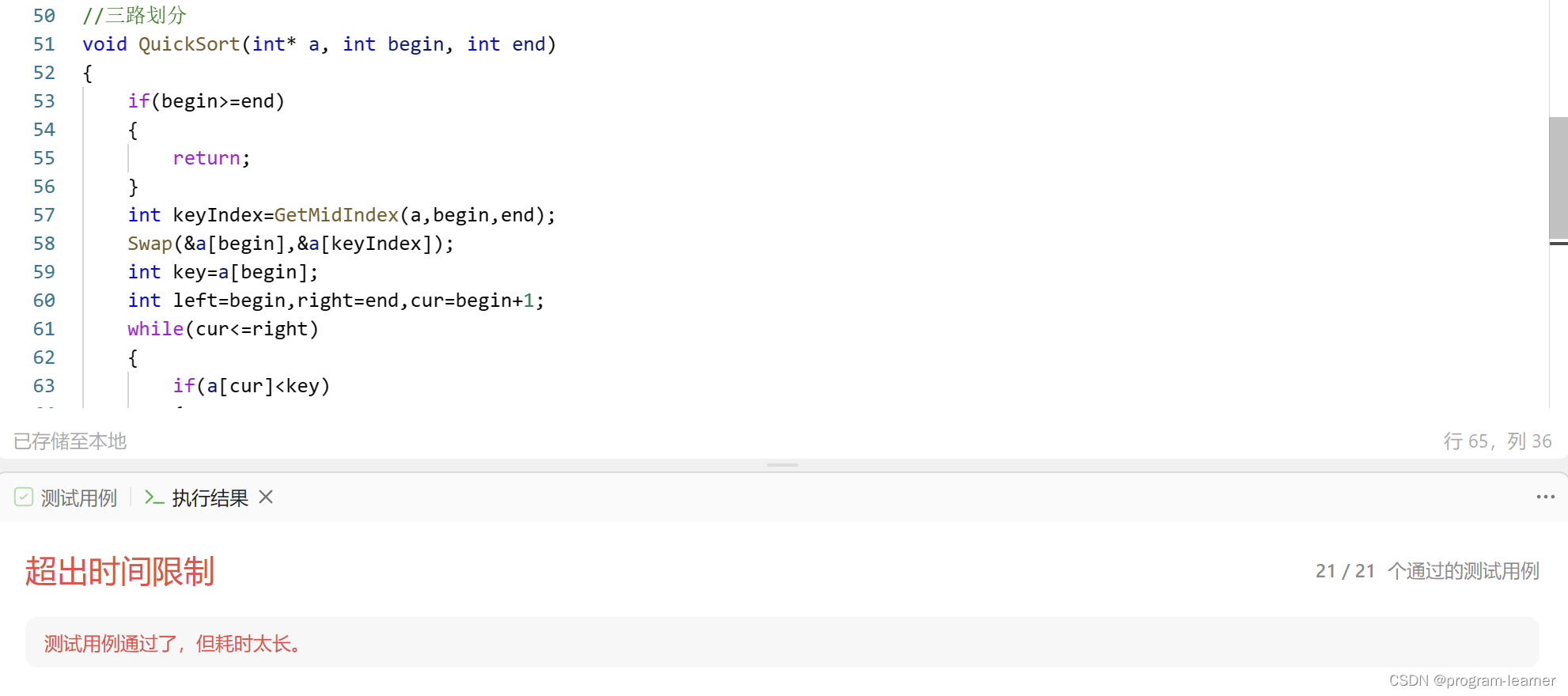
尽管我们通过了所有的测试用例,但是因为耗时太长leetcode直接针对快排
那么怎么办,怎么过呢?
我们去掉三数取中优化,看一下是哪个测试用例对我们的针对
这里我们打印了一下数组开头,中间,结尾的那三个数
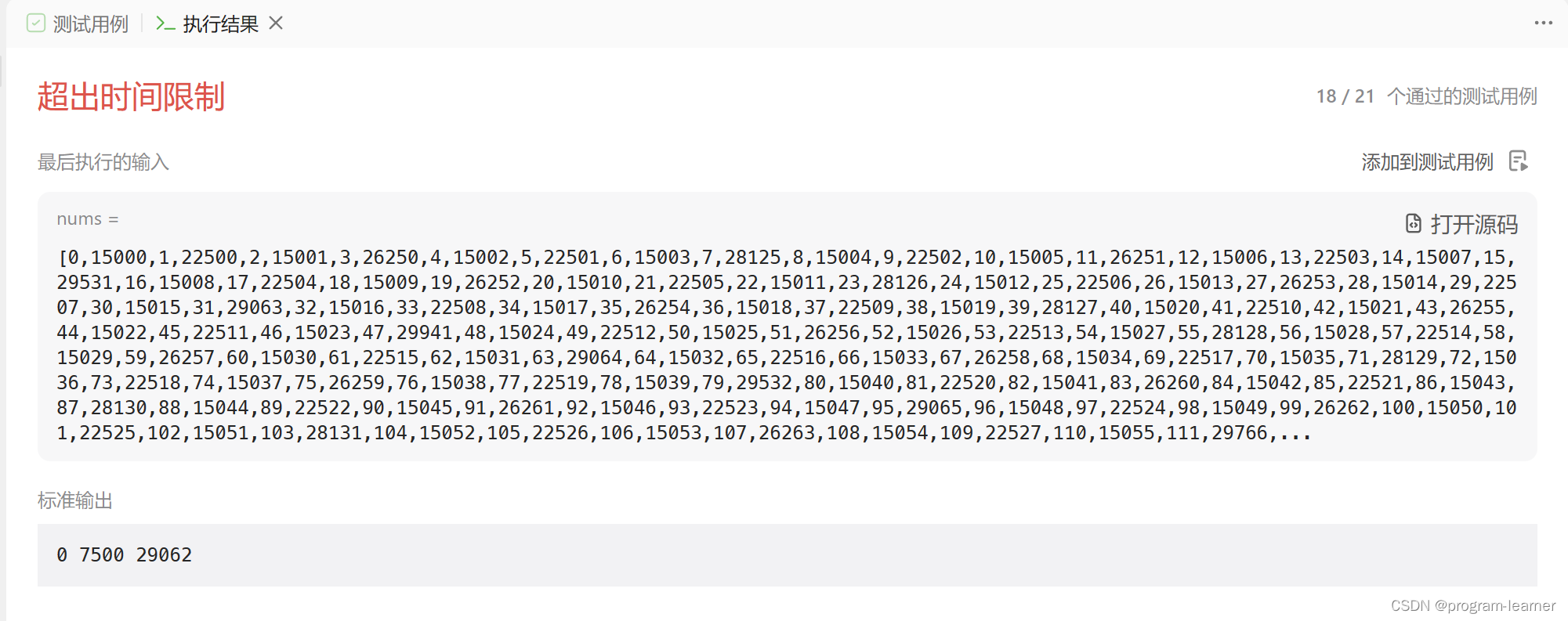
这个题目最大值是50000,
这个测试用例最大值是上万,而我们三数取中取出来的是7500,相对来说偏小了
所以我们要对三数取中的mid搞一个随机数
只需要在三数取中的代码中给mid一个随机值即可

这里设置随机数种子,避免出现rand函数产生的重复值不变的情况

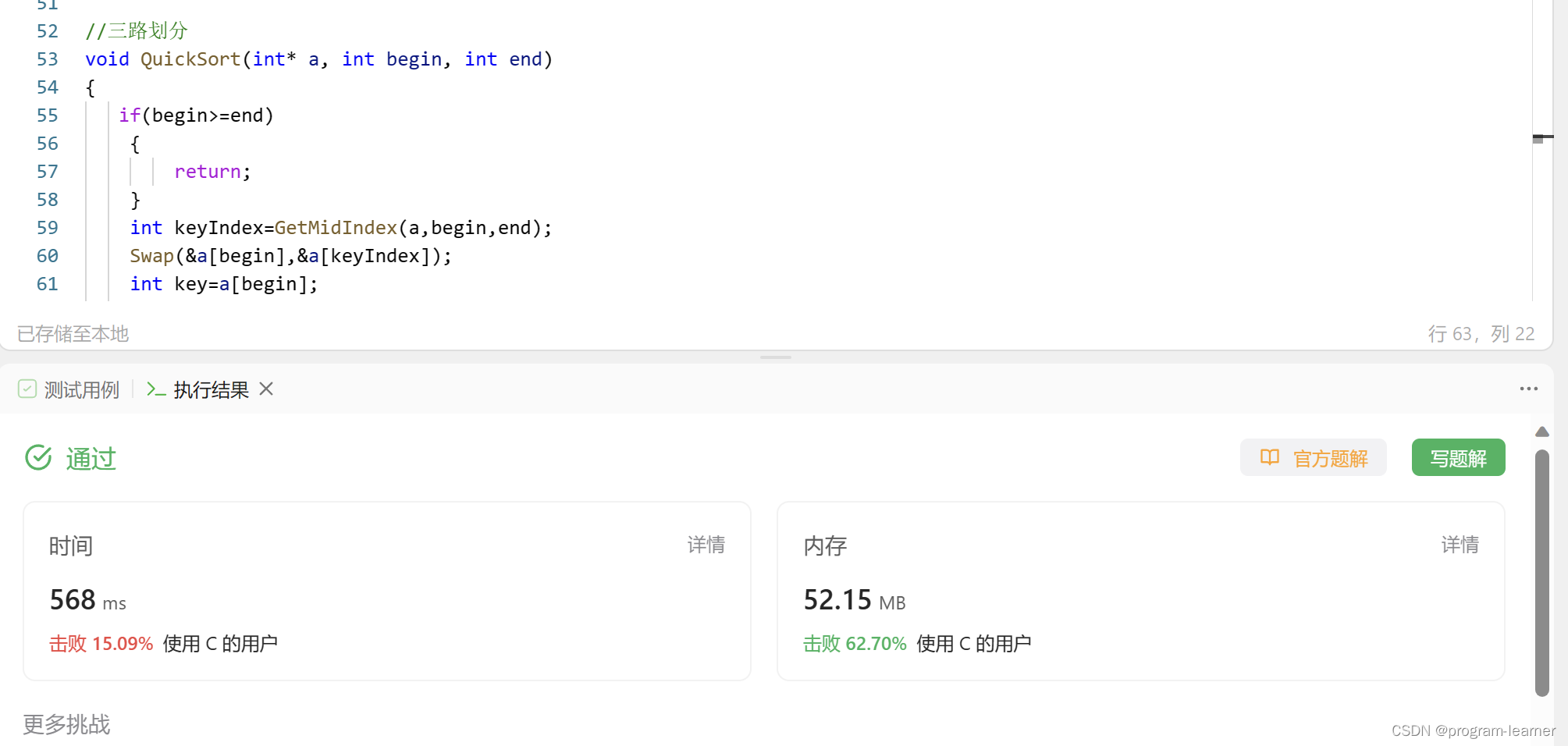
尽管我们过是过了,但是Leetcode这一题的测试用例太针对快排了
所以快排被欺负的很惨
以上就是leetcodeT912针对快排的三路划分优化的讲解,希望能对大家有所帮助!
这篇关于leetcodeT912-快排优化-三路划分的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


