本文主要是介绍存档&改造【06】Apex-Fancy-Tree-Select花式树的使用误删页数据还原(根据时间节点导出导入),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
之前一直想实现厂区-区域-产线之间的级联选取,于是导入插件Apex-Fancy-Tree-Select花式树
存档&改造【03】Apex-Fancy-Tree-Select花式树的导入-CSDN博客
现在则是在Oracle Apex中的应用
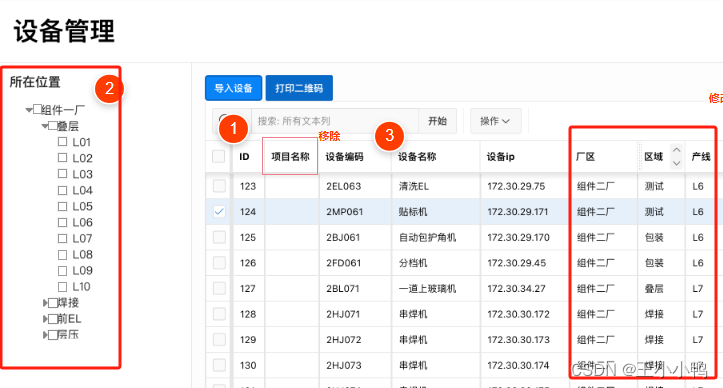
花式书级联列表展示厂区-区域-产线
想要实现的效果
由厂区>区域>产线逐级将项列出(后来发现三层暂时无法实现,改为厂区>区域逐级将项列出)- 勾选指定项目进行筛选勾选上级时默认勾选下级
- 筛选条件应用于右侧
参考APP145,P26
select distinct (o.DEPT_ID) as id, --数据ido.PARENT_ID as PARENT_ID, --父ido.NAME as title, --显示的标题o.DEPT_ID as VALUE, --标题对应的值casewhen o.PARENT_ID is null then0else1end as TYPE, --使用选择功能时需要 - 是配置 json 中 typeSettings 的映射值casewhen mod(o.DEPT_ID, 2) = 0 then 1else0end as SELECTED, --设置加载时选中 0(null): 不选中 1:选中0 as EXPANDED, --是否展开未选中项 0(null): 不展开 1:展开1 as CHECKBOX, --是否启用复选框 0(null): 禁用 1:启用0 as UNSELECTABLE --设置不可选中 0(null): 可以 1: 不可以
from APEX_TEST_DEPT o
start with PARENT_ID is not null
connect by prior DEPT_ID = PARENT_ID
order by DEPT_ID;试着改一个
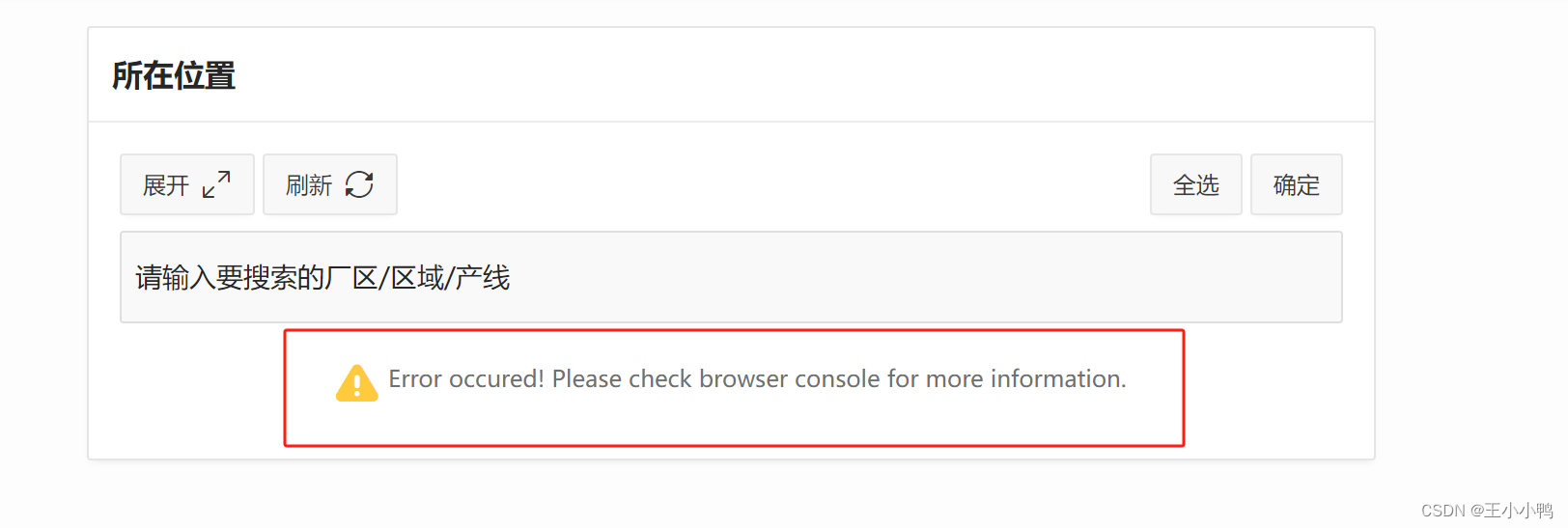
Error occured! Please check browser console for more information.
发生错误!有关详细信息,请查看浏览器控制台。
查看会话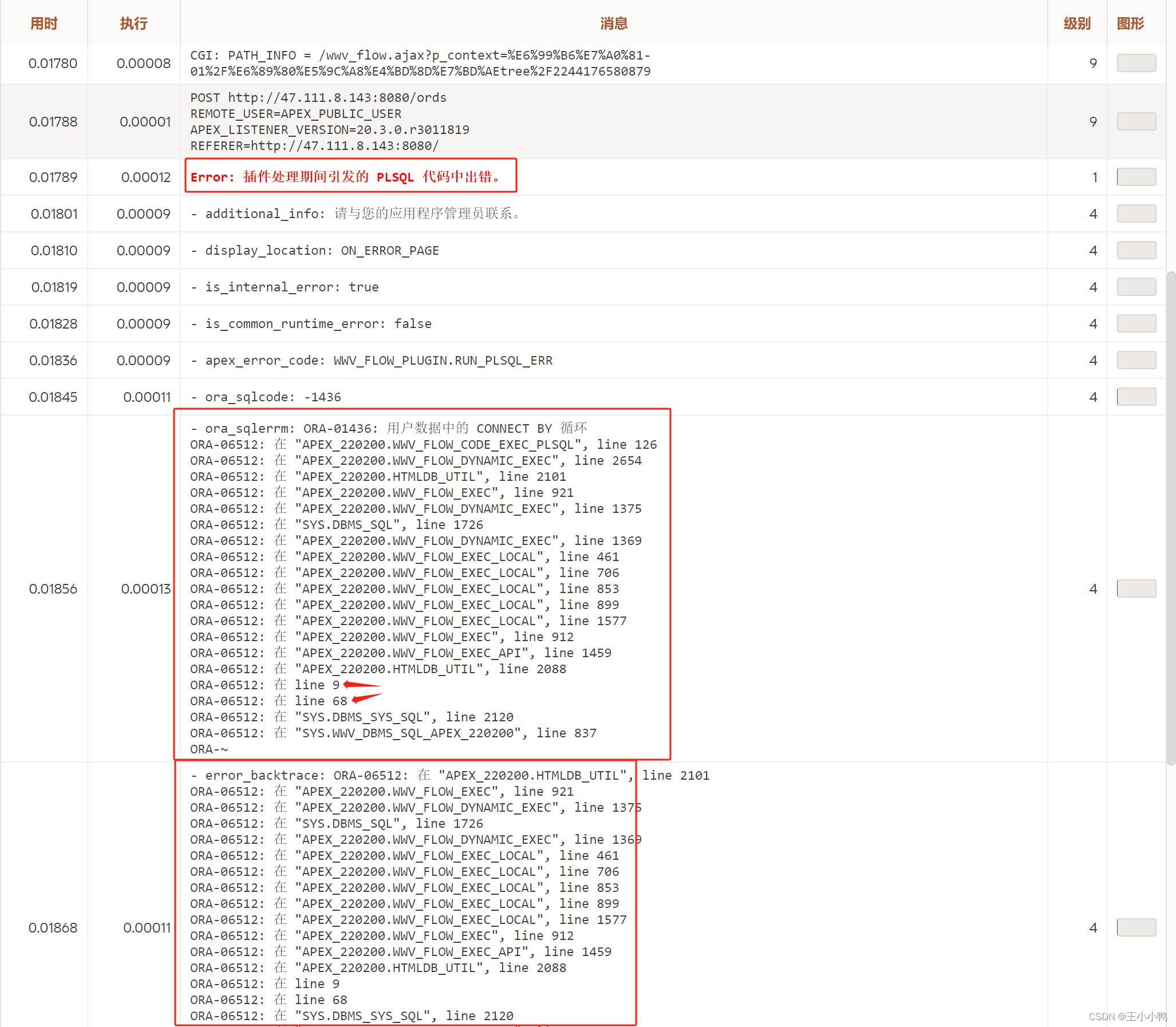
后来在蒋老师提供PL/SQL代码支持下得以展示
select a.id as ID,a.PARENT_ID,a.NAME as TITLE,a.id as VALUE,casewhen a.PARENT_ID is null then0else1end as TYPE,0 SELECTED,NULL as EXPANDED,1 as CHECKBOX,0 as UNSELECTABLE
from (select a.AREA_ID || '_area' id,a.NAME,FAB_ID || '_fab' parent_idfrom FND_AREAS awhere a.TYPE = 2and a.DEL_FLAG = 0and a.TENANT_ID = 2union allselect f.FAB_ID || '_fab' id,f.NAME,null parent_idfrom FND_FAB fwhere f.DEL_FLAG = 0and f.TENANT_ID = 2) a
start with a.PARENT_ID is null
connect by prior a.id = a.PARENT_ID
order by a.NAME;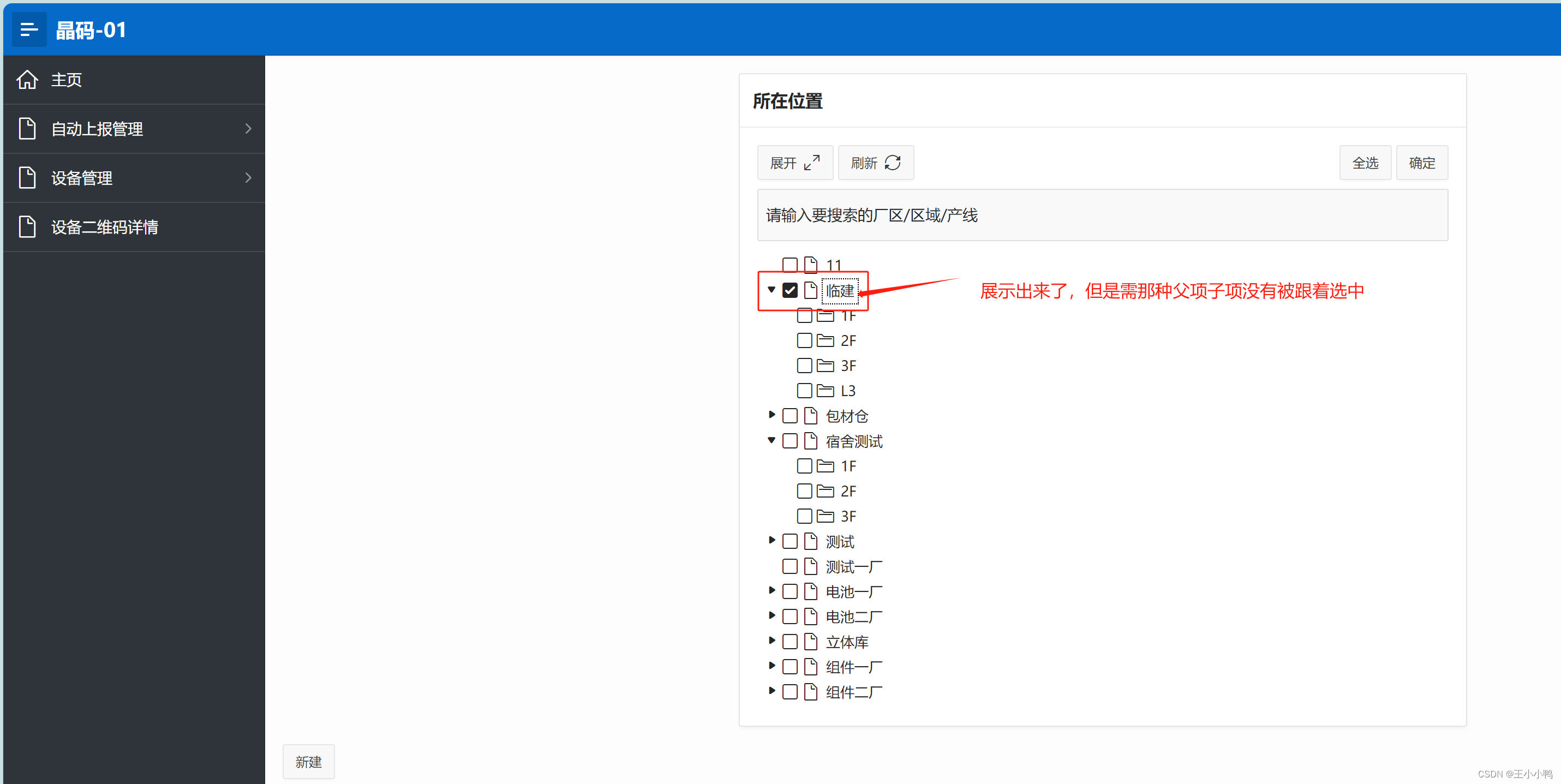
查看会话
DEPRECATED: json_from_sql, use APEX_EXEC and APEX_JSON instead
已弃用:json_from_sql,请改用APEX_EXEC和APEX_json
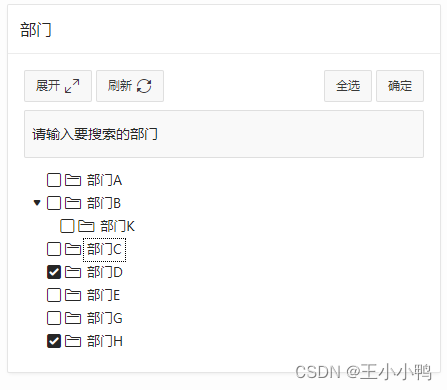
后来找到了,需要在【属性】里配置json,将类型改成3,即选中父项也会选中子项
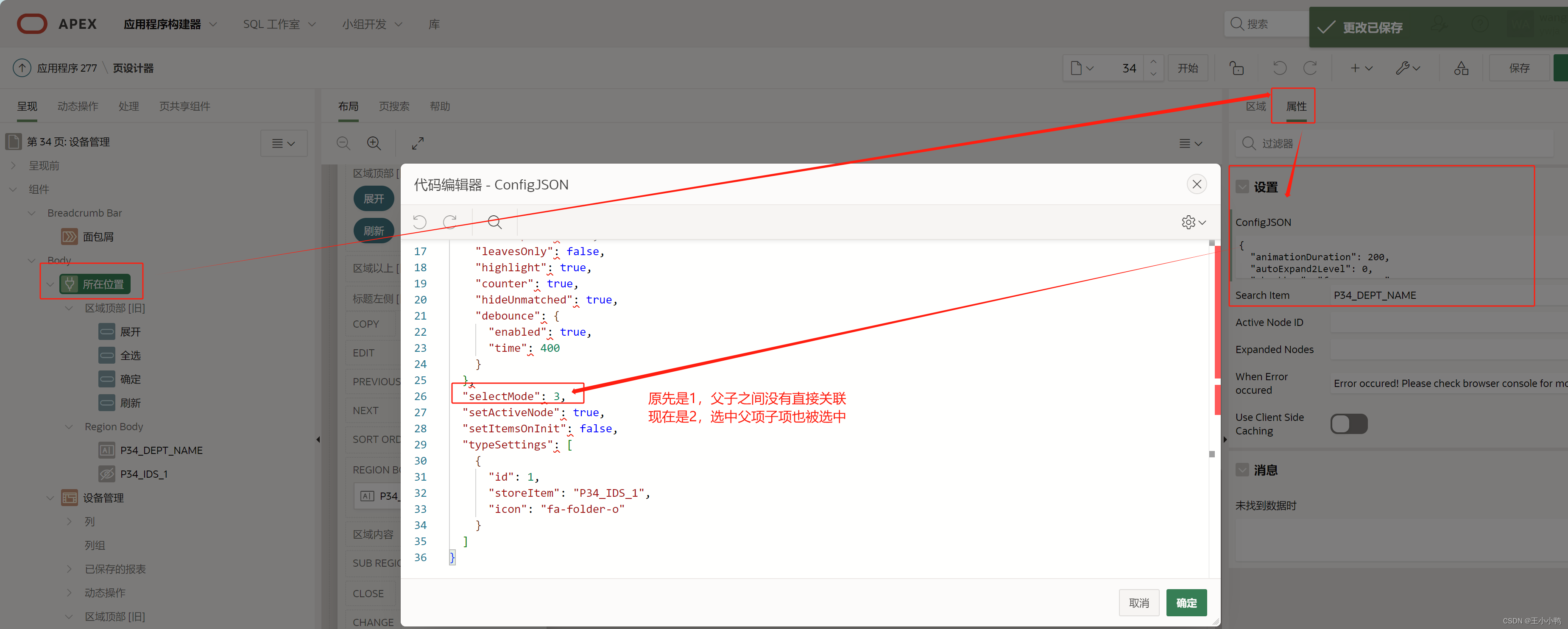
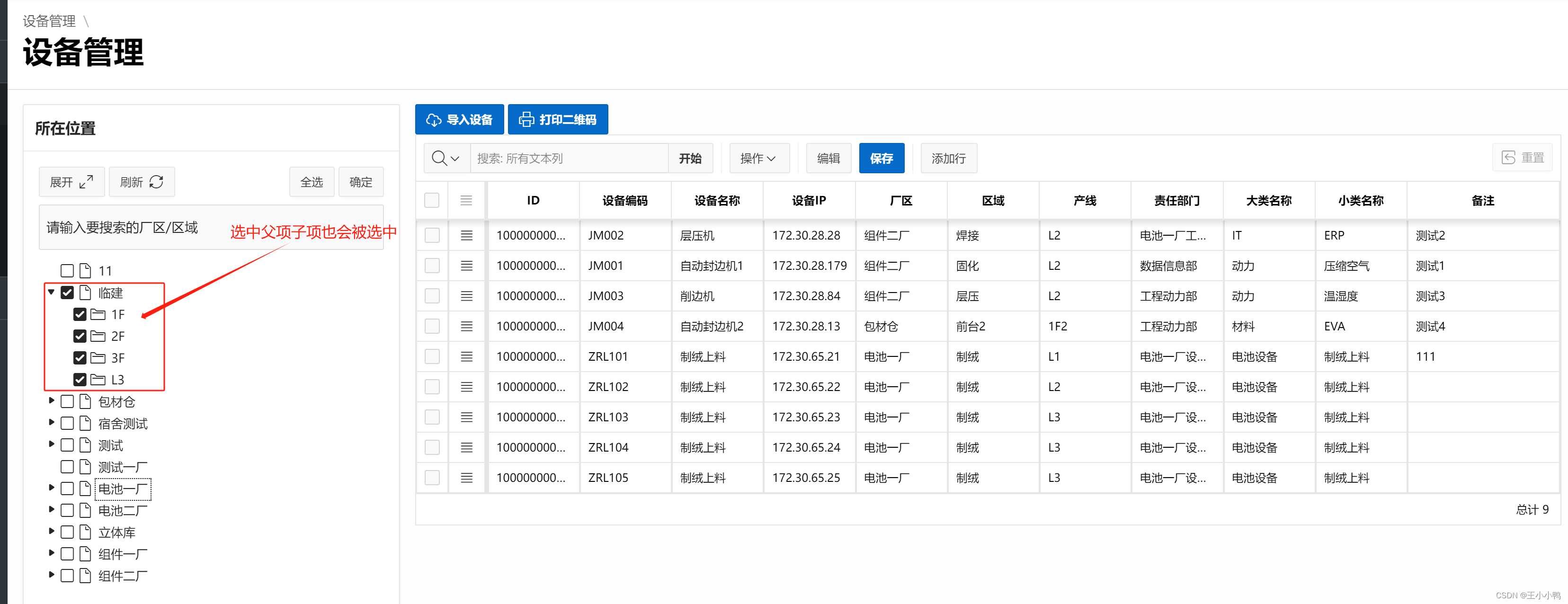
之后就是在页面根据级联列表选中的厂区和区域进行筛选展示,及一进来默认全不选,所有数据都能展示,勾选厂区/区域后进行对应数据展示。
一整个完整过程
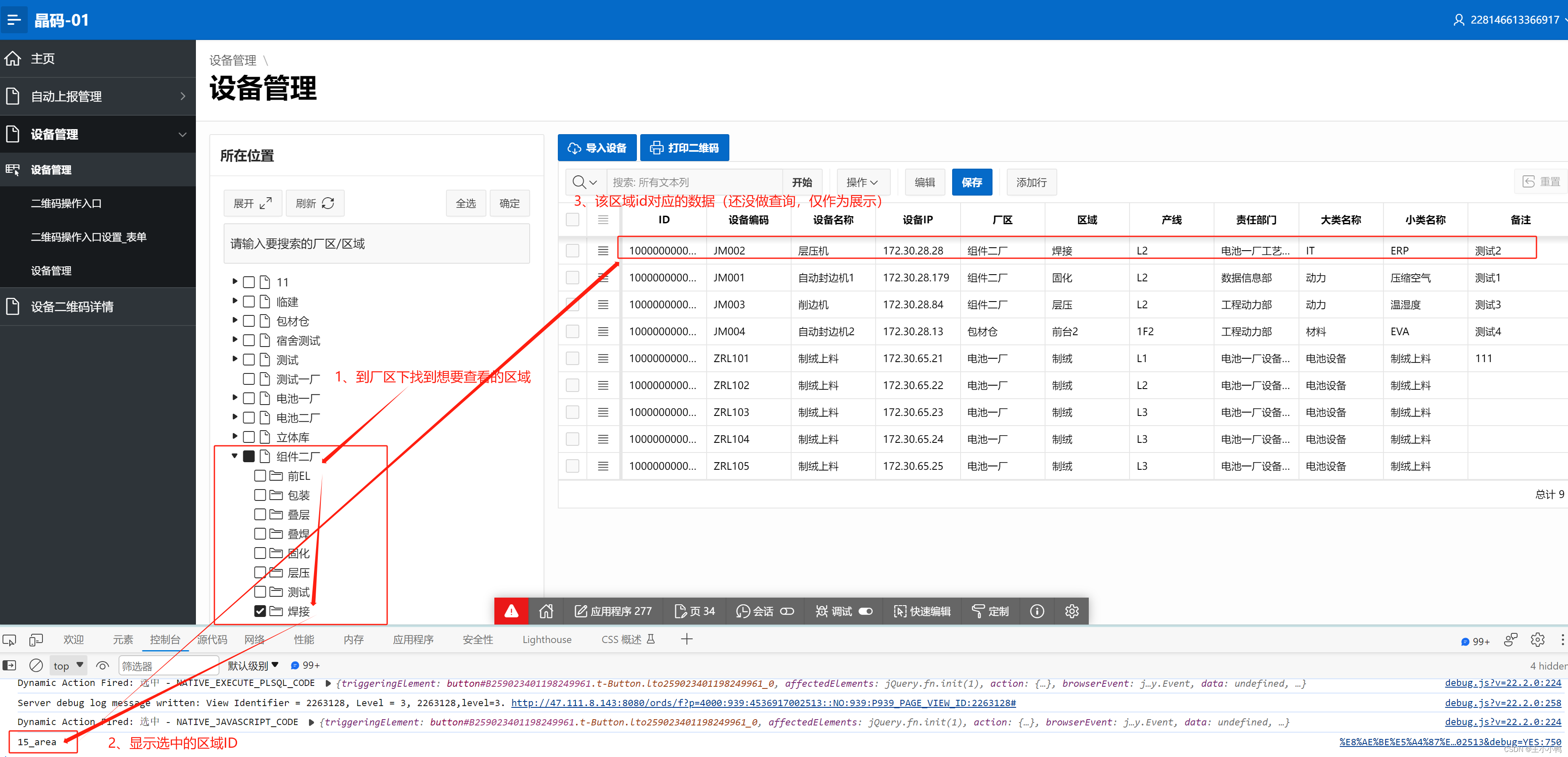
查看筛选代码样例
select *
from CODE_DEVICE
where AREA_ID in (select regexp_replace(data_val, '_area', '')from UTILS_PKG.SPLIT_STR('94_area:102_area:103_area:104_area:321_area:322_area:323_area:324_area:325_area:326_area:327_area:95_area:328_area:93_area:96_area:97_area:98_area:99_area:100_area:101_area',':')
);
到数据库查询改数据核对是否成功
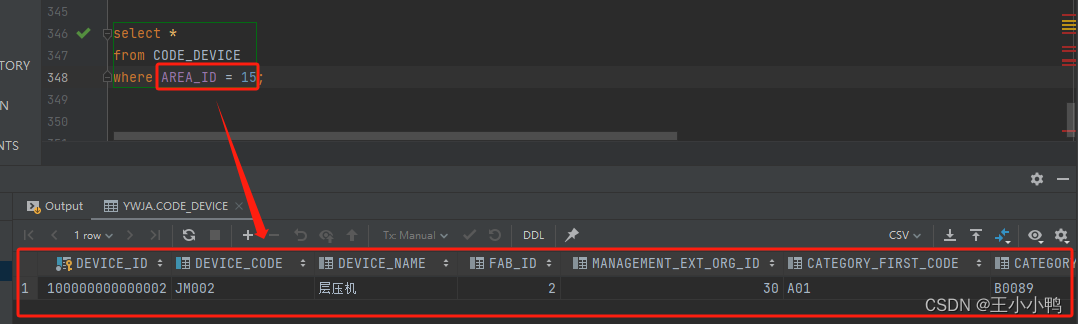
查询成功,方向可行。
后续在实现的时候出现网页上显示id取到了,但是查找一片空白,什么都没有
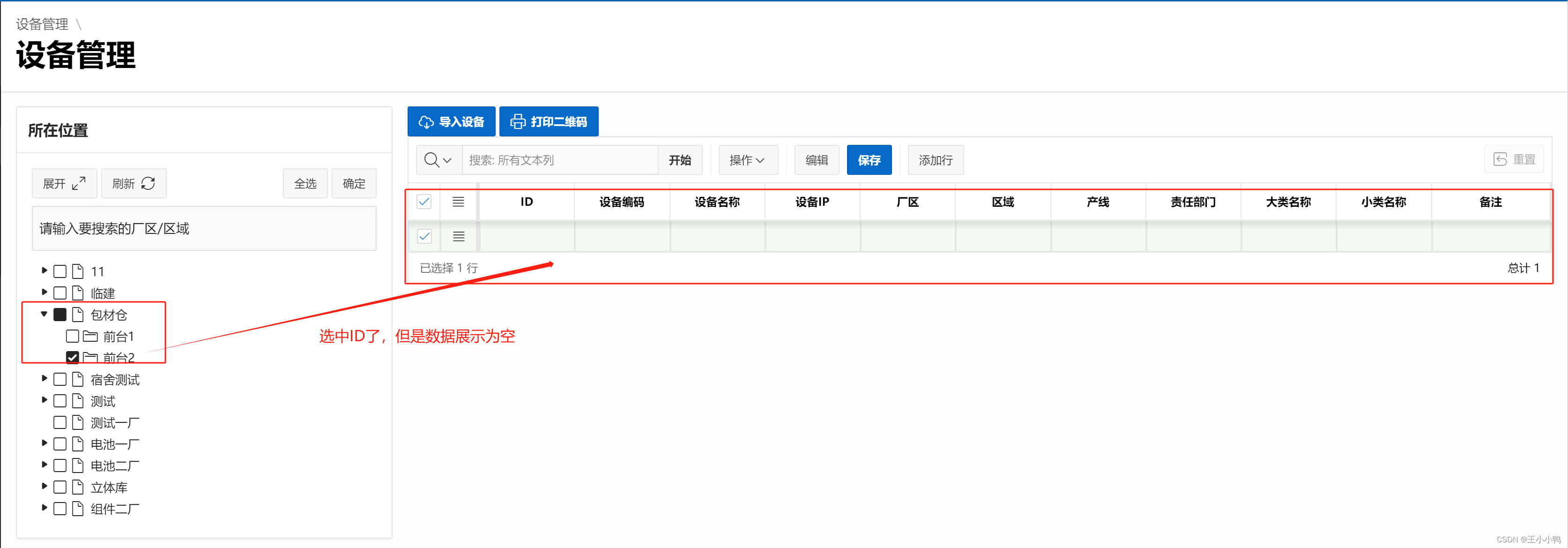
后来蒋老师慧眼如炬找到了问题所在,在点击确认后确实会执行Javascript代码中在网页控制台打印选中的id,但是参考的样例只是个demo没有实际数据,所以id置空,我也跟着置空,可不是取不到吗,我的问题!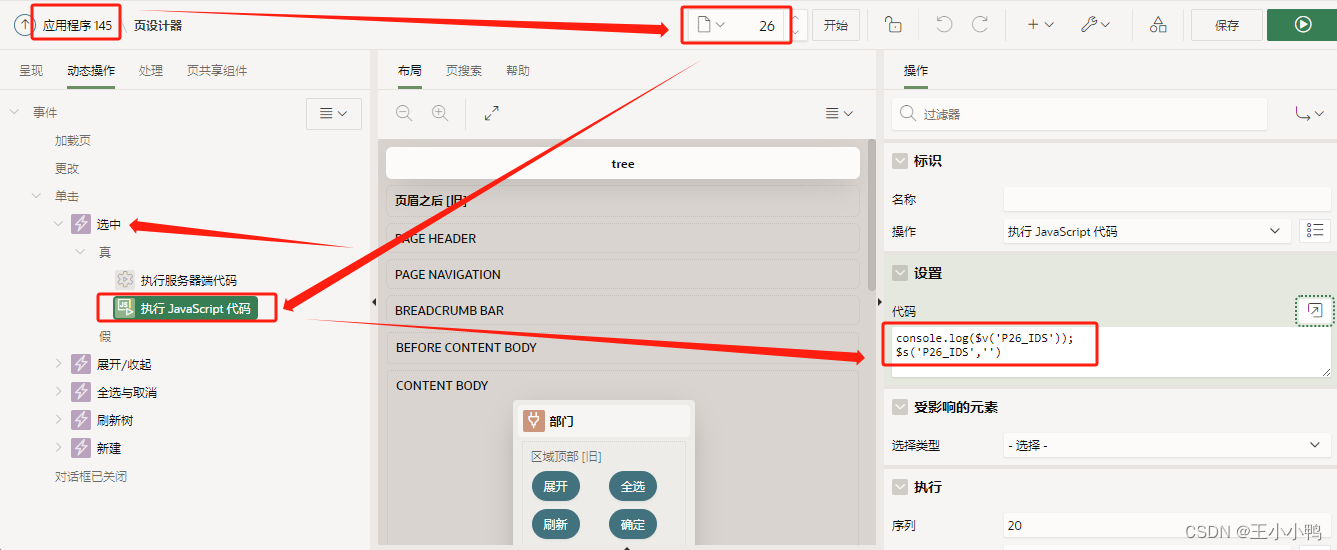
后来将取到的ID传过去就没问题了
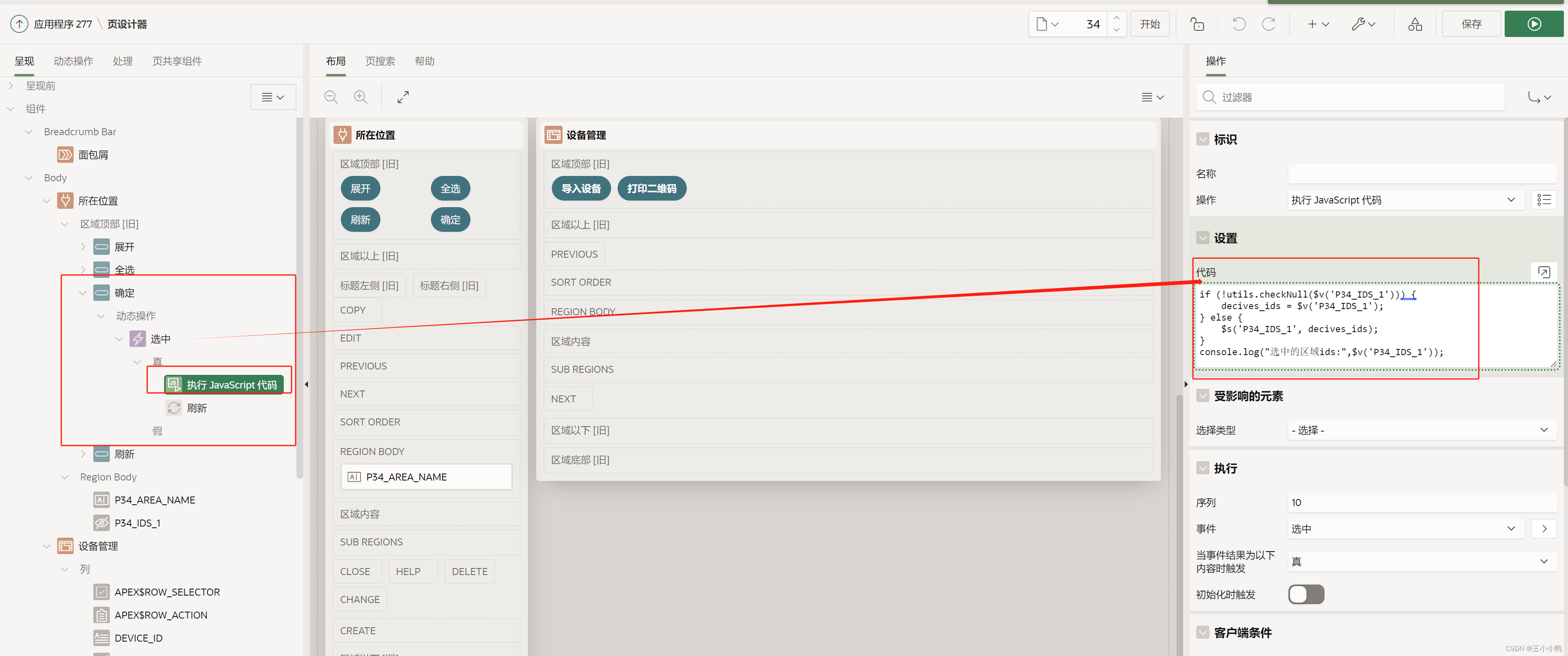
按钮【确定】→【动态操作】→【执行JavaScript代码】↓
if (!utils.checkNull($v('P34_IDS_1'))) {decives_ids = $v('P34_IDS_1');
} else {$s('P34_IDS_1', decives_ids);
}
console.log("选中的区域ids:",$v('P34_IDS_1'));查询结果
页面会展示含有选中厂区/区域ID的数据
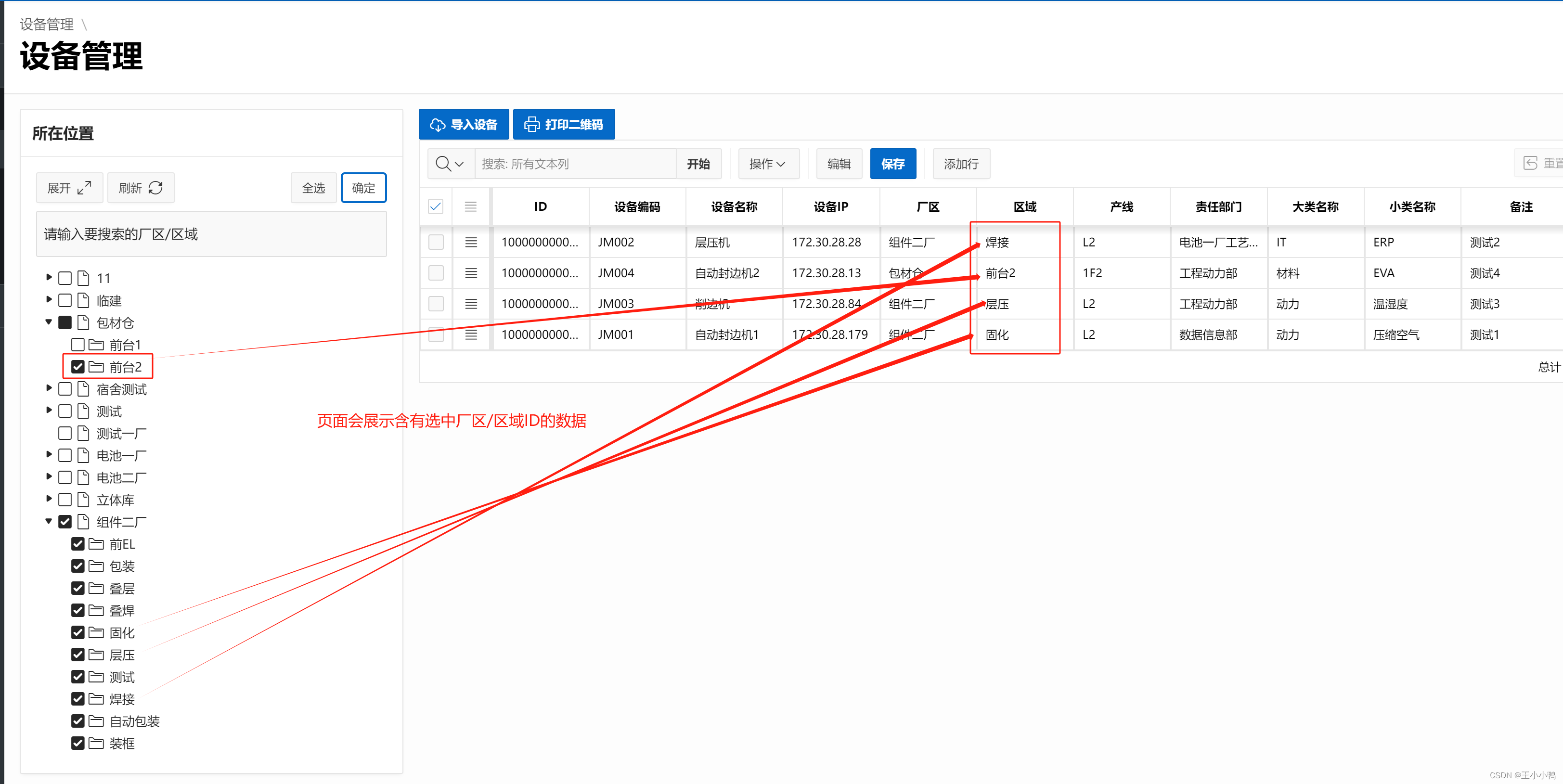
【存在的问题】确定键只能选一次,每次选中展示数据都要刷新重新选,而且页面不刷新还会展示上一次界面
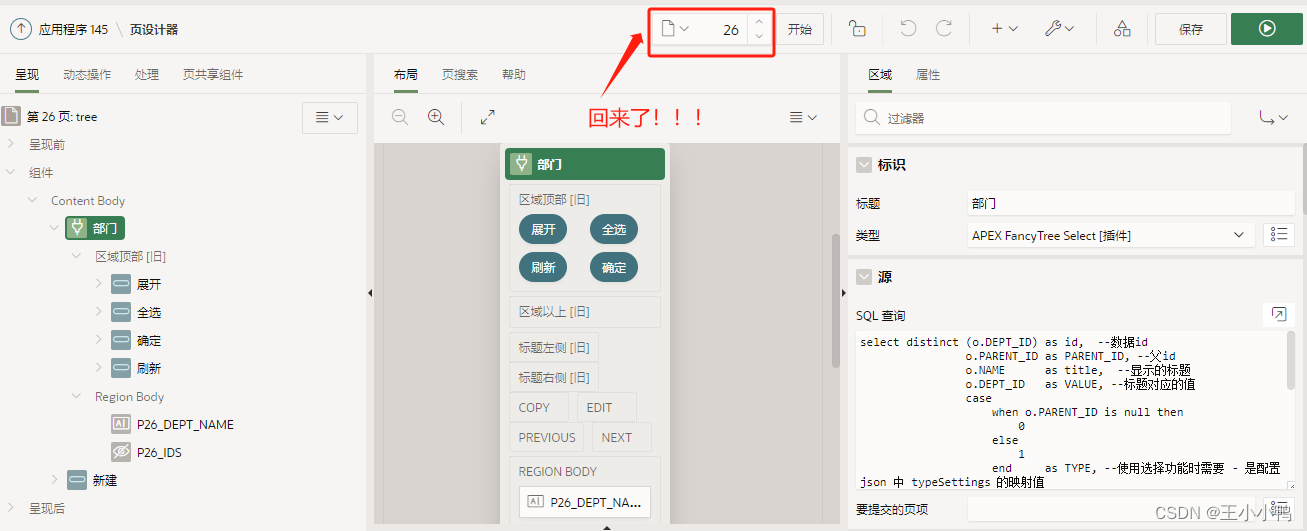
【突发状况】想要删除无用的app277多余页面,但是数据交互一不小心删除了app145,想要还原对应数据,但是历史记录对应景删除的页面无能为力
【解决办法】导出删除时间前的应用程序数据,然后再次导入
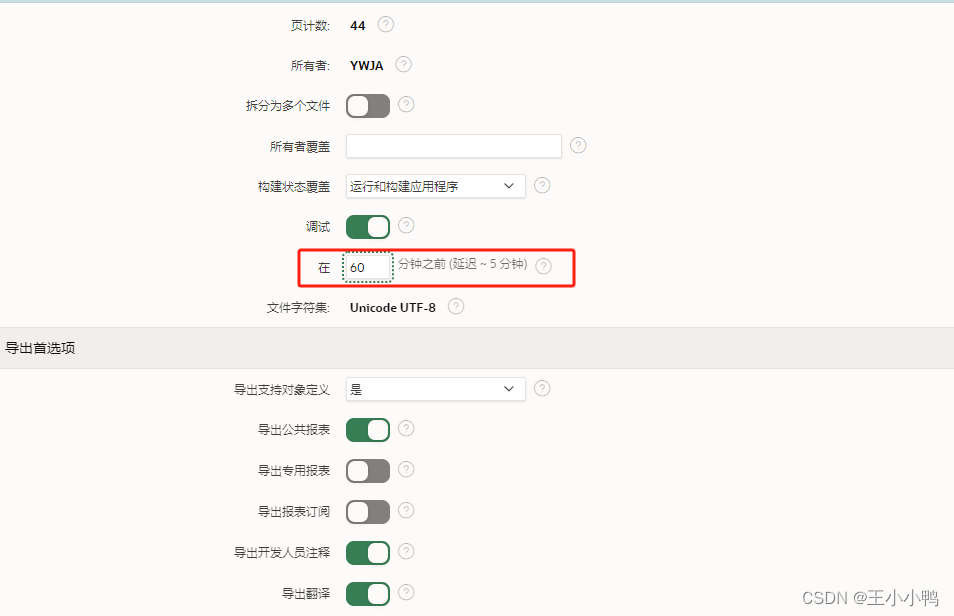
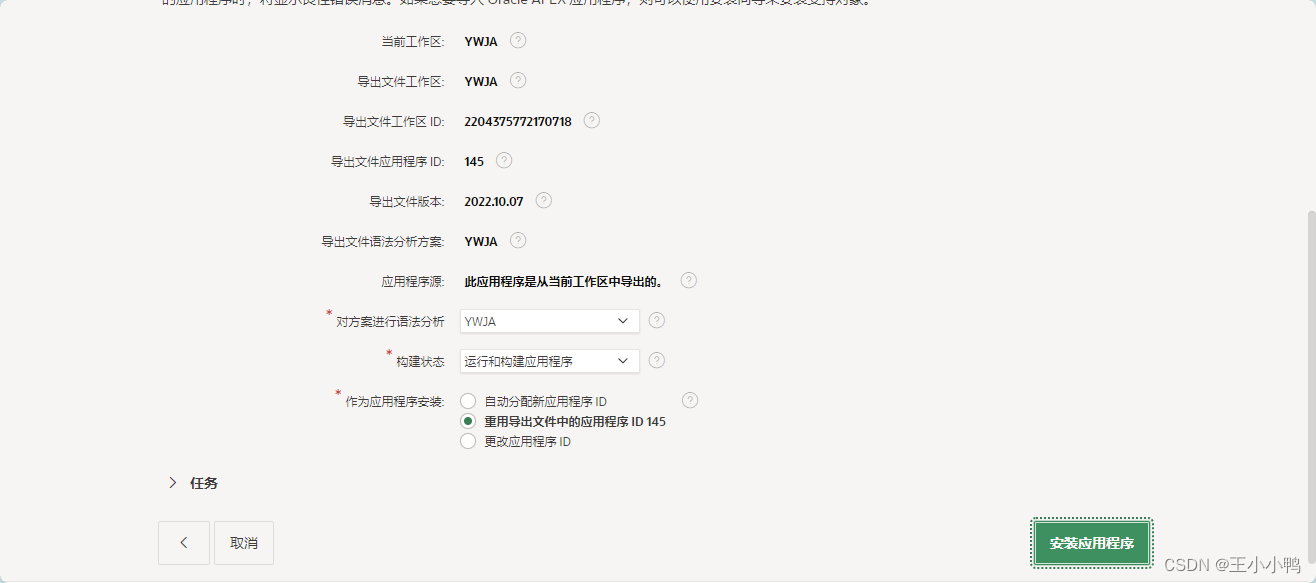
替换被删除的应用程序
被误删的页终于回来了!!!
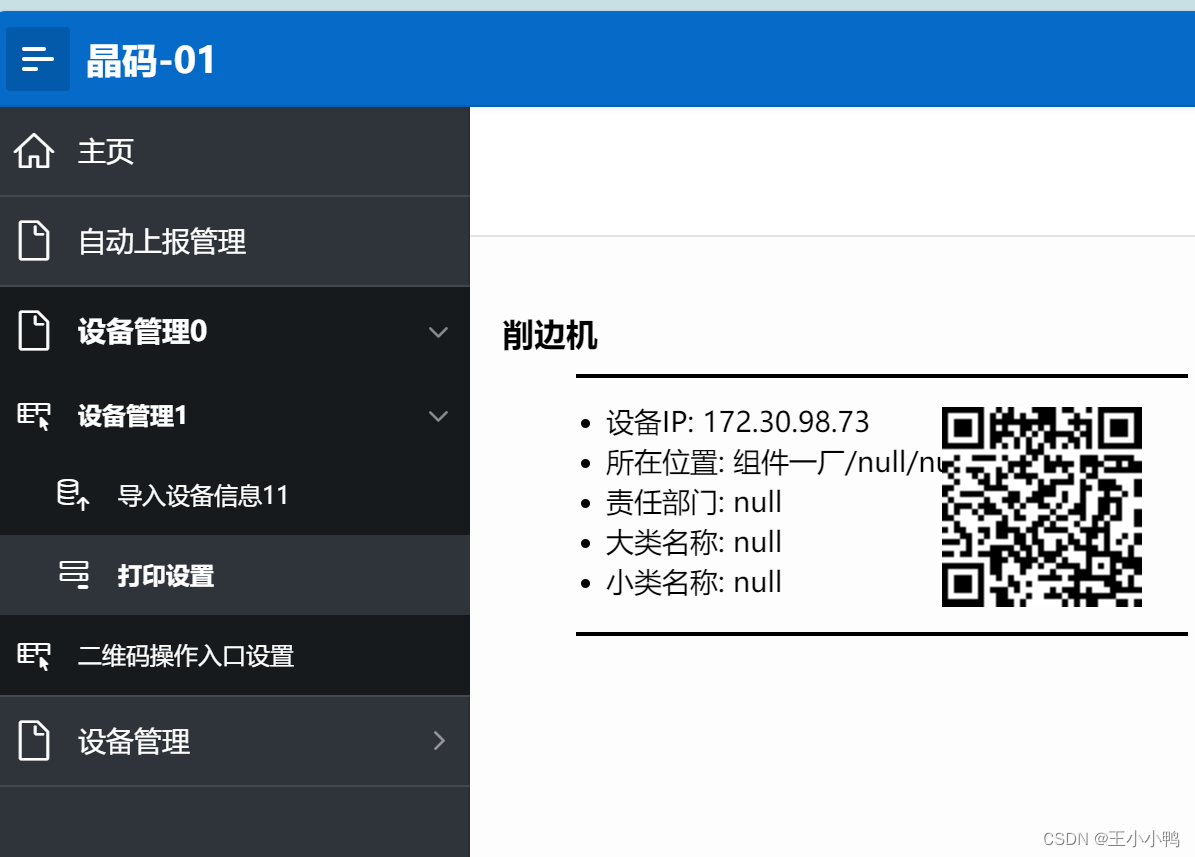
【待解决】在选中数据生成对应二维码
之前因为没给到数据表和结构,所以用的是测试表数据,展现效果差强人意,
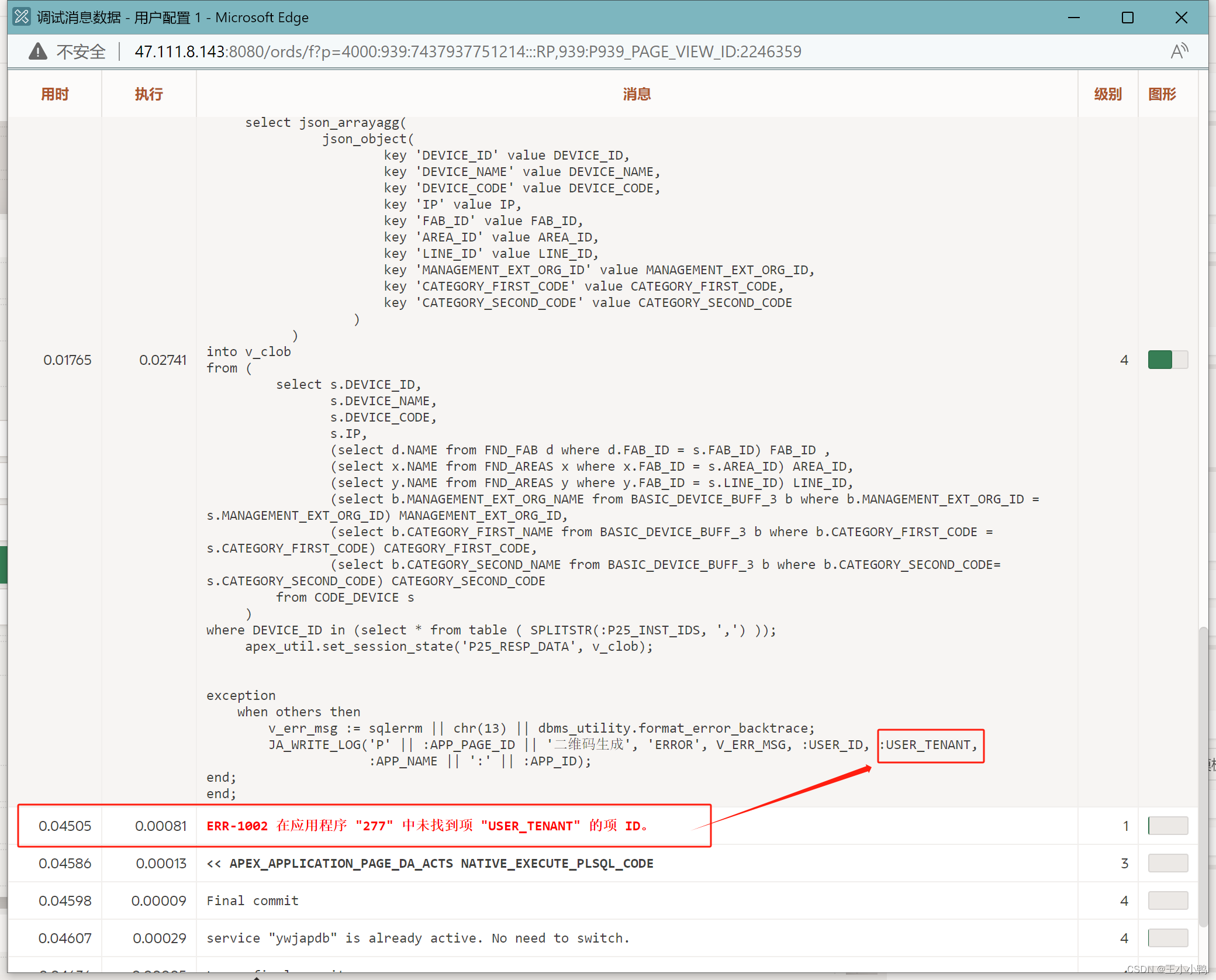
后续使用新的数据表结果页面一片空白,查看会话调试结果,发现报错
ERR-1002 在应用程序 "277" 中未找到项 "USER_TENANT" 的项 ID。 |
嘶——怪哉,之前用老数据还能展示的,只是名称没能转换出来
到底是哪里出了问题呢?
去看登录页查看USER_TENANT,对照晶豹发现该项没有改变
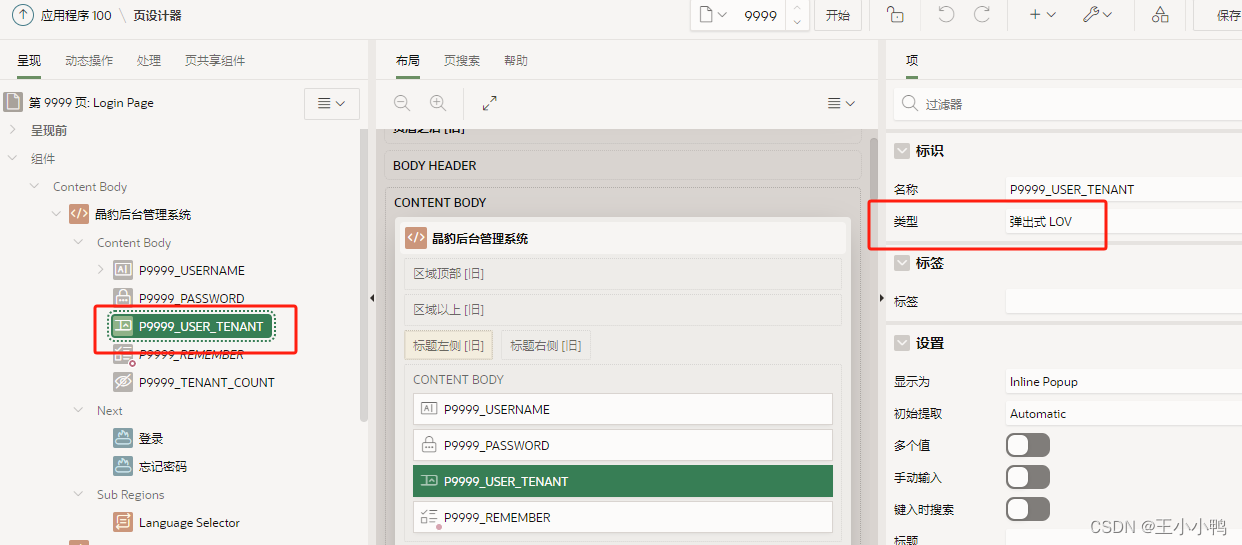
值列表依旧是SQL查询
SELECT DISTINCT (SELECT NAME FROM MPF.SHARE_TENANT_V B WHERE B.TENANT_ID = A.TENANT_ID) NAME, TENANT_ID
FROM MPF_USER_DEPT_MAIN_ASSO_V A
WHERE MOBILE = :P9999_USERNAMEor JOB_NUMBER = :P9999_USERNAME
ORDER BY TENANT_ID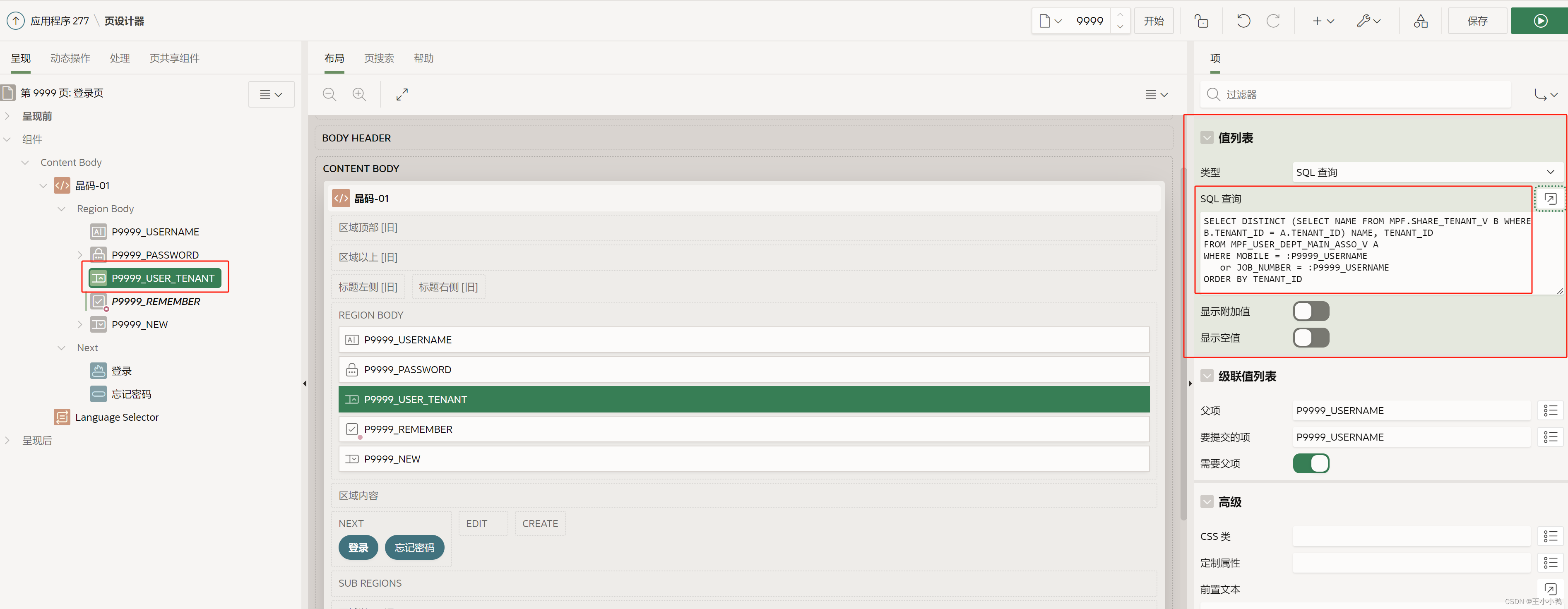
倒是REMEMBER(记住账户)发生了一些改变:
原来的【标识】→【类型】是“复选框”,新的是“复选框组”
新增【值列表】内容,
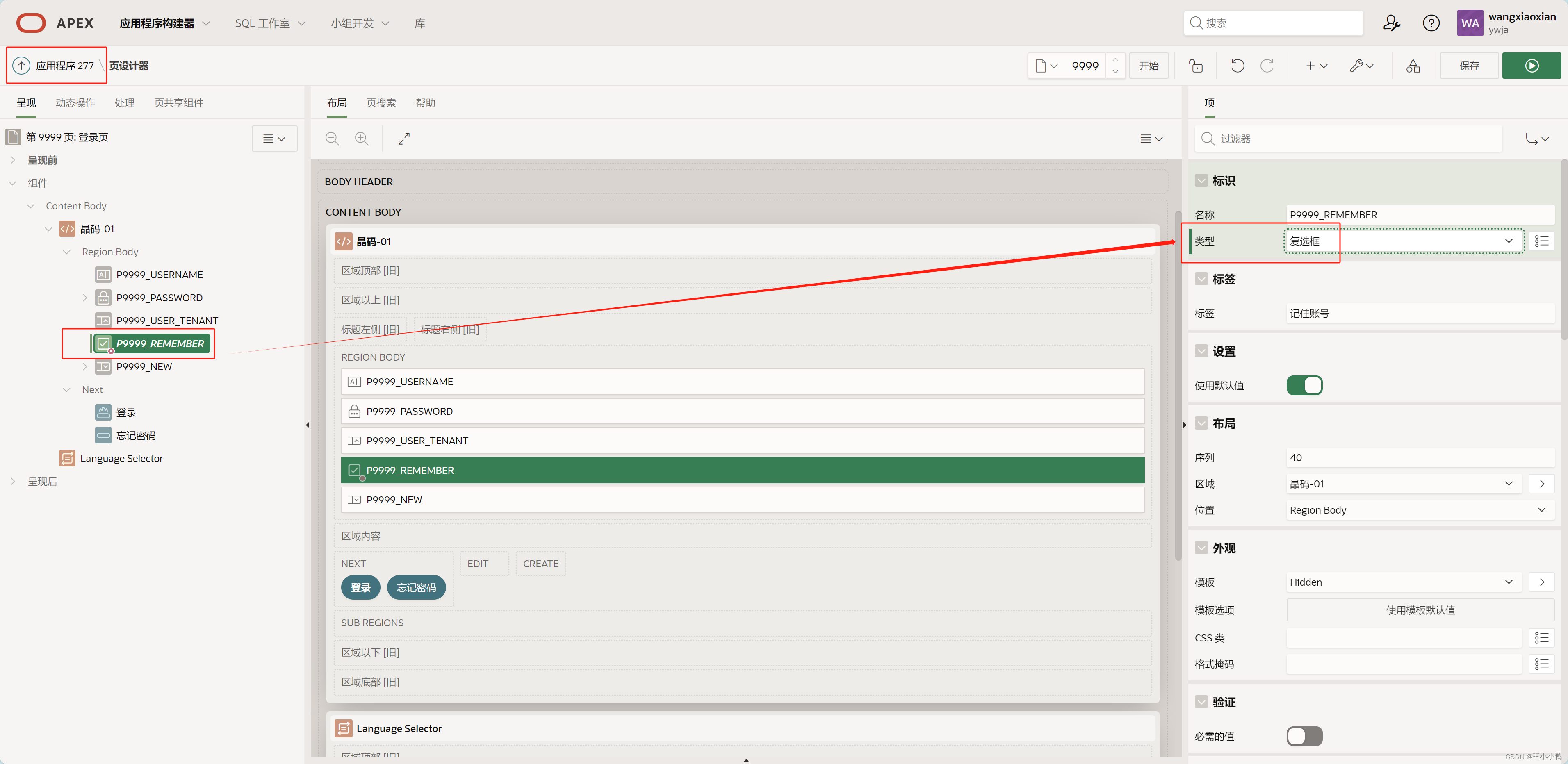
和登录还有样式关系不大,还是去调试里找原因
app277,page14,
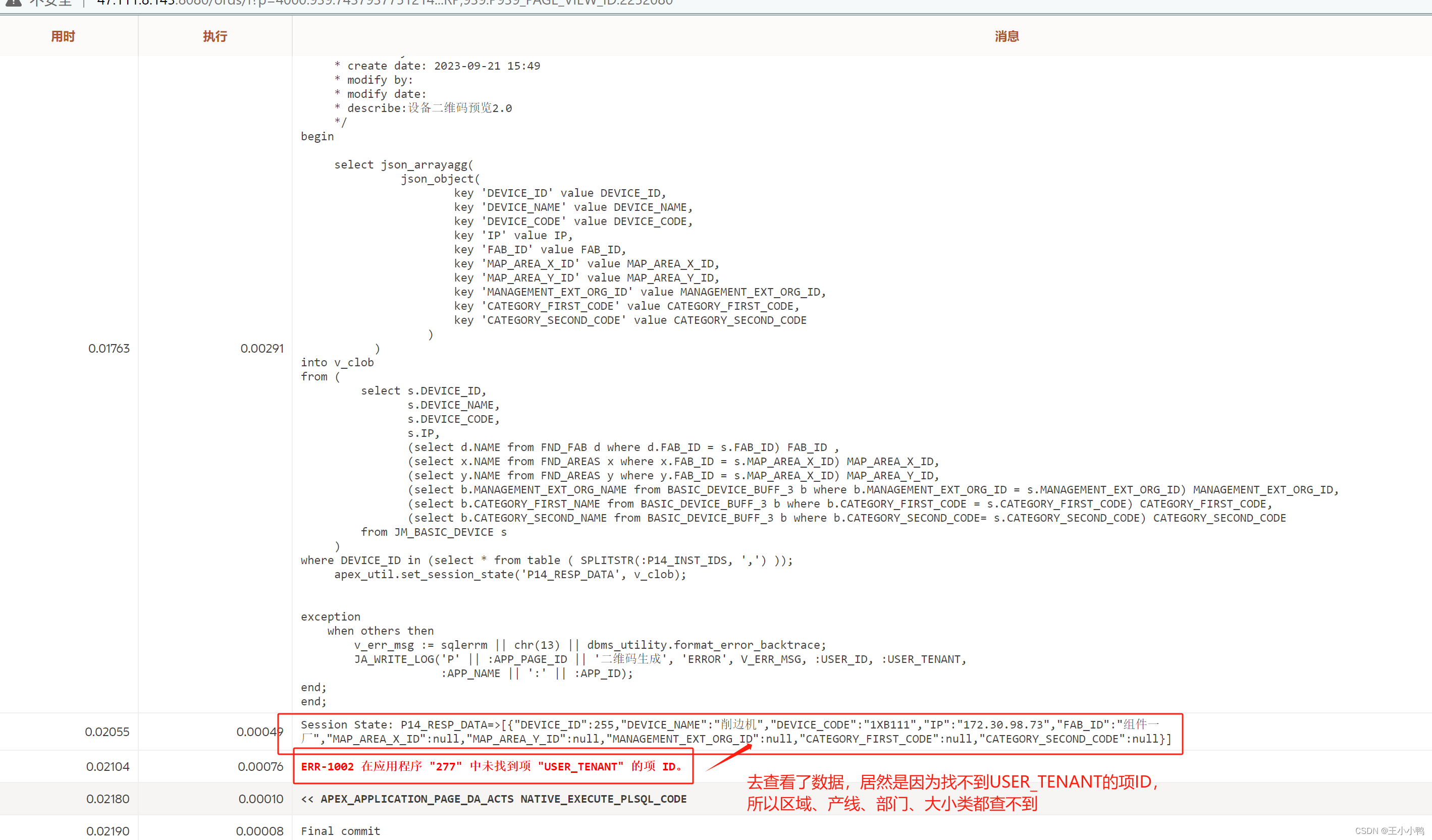
还是之前的问题,
ERR-1002 在应用程序 "277" 中未找到项 "USER_TENANT" 的项 ID。
【问题原因】USER_TENANT租户信息未获取
【问题解决】在USER_TENANT项下的设置【默认值】,获取租户信息
参考存档&改造【05】通过视图实现多表联查&理清级联层级关系&对字段的唯一约束_王小小鸭的博客-CSDN博客
【可操作对象的存储】
-- 可操作对象的指定和存储
declarev_err_msg nvarchar2(2000);v_user_ids varchar2(2000);v_dept_ids varchar2(2000);
-- v_user_ids varchar2(2000) = 'JA063198';
-- v_dept_ids varchar2(2000) = '100';
beginif :AUTH_RANGE = 'IS_ALL' then-- 主表新增一条数据(验证是否存在)select JOB_NUMBER from MPF_USER_DEPT_MAIN_ASSO_Vwhere TENANT_ID = :USERTENANT AND DEL_FLAG = 0;else-- 主表新增一条数据 (验证是否存在)--- 查询本次要新增的人员数据for c in ( select u.JOB_NUMBERfrom (select JOB_NUMBERfrom MPF_USER_DEPT_MAIN_ASSO_Vwhere EXT_USER_ID in (select *from JA_UTILS_PKG.SPLIT_STR(v_user_ids, ','))unionselect JOB_NUMBERfrom MPF_USER_DEPT_MAIN_ASSO_Vwhere EXT_ORG_ID in (select *from JA_UTILS_PKG.SPLIT_STR(v_dept_ids, ','))) uleft join CODE_SYSTEM_OPERATION_AUTH a on u.JOB_NUMBER = a.JOB_NUMBERwhere a.OPERATION_AUTH_ID is null)loopDBMS_OUTPUT.PUT_LINE(c.JOB_NUMBER);end loop;end if;exceptionwhen others thenv_err_msg := sqlerrm || chr(13) || dbms_utility.format_error_backtrace;DBMS_OUTPUT.PUT_LINE(v_err_msg);
end;

未完成功能:
鼠标点击设备编码和设备名称可查看生成的二维码(最好能复制,复制不了就复制链接,蒋老师说不是什么问题,截个图的事儿)
二维码操作入口设置-新增、编辑
存在的问题:
级联树形列表刷新后只能保存一次数据(后续需刷新)
二维码操作入口-列表展示-可操作对象应该设置成仅展示,不能更改(更改在设置里)
重点和难点:
二维码的生成、预览、批量下载
设备模板下载和设备导入
厂区-区域的级联展示
二维码操作入口-操作项设置-设置可操作对象
这篇关于存档&改造【06】Apex-Fancy-Tree-Select花式树的使用误删页数据还原(根据时间节点导出导入)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




