本文主要是介绍Python从诗词名句网站中抓取四大名著之一《三国演义》!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从诗词名句网站中抓取四大名著之一三国演义,并保存!
@ XGan 2019 12 19
**抓取诗词网站(http://www.shicimingju.com/book/sanguoyanyi.html)中的四大名著,并保存到本地文件中,使用该代码可以抓取诗词网上很多的古典诗集的,只需做稍微的修改,但都只支持单部书籍的爬取,等有时间写一个全网爬取的Demo,到时候与大家分享,这里只是以《三国演义》爬取为例。
python代码
import random
import requests
from lxml import etreehead = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
]def get_html(url): #获取每一章节的链接res = requests.get(url,headers={'User-Agent':random.choice(head)}).texthtml = etree.HTML(res)# 得到每一章节的链接url_list = html.xpath("//div[@class='book-mulu']/ul/li/a/@href")return url_list
def get_chapter_content(url_list): #对每一章节发起请求,并提取title,text内容,保存在txt中with open('./data/三国演义.txt','w',encoding='utf-8') as f:print(50 * '*' + "开始抓取" + 50 * '*')for u in url_list:url = 'http://www.shicimingju.com' +ures = requests.get(url,headers={'User-Agent':random.choice(head)}).texthtml = etree.HTML(res)# 获取每张标题title = html.xpath("//div[@class='card bookmark-list']/h1/text()")print(title[0]+"\n")f.write(str(title[0])+"\n")p_list = html.xpath("//div[@class='chapter_content']//p")for p in p_list:# 获取每章内容text = p.xpath("./text()")[0]f.write(str(text)+"\n")print(text)print(50 * '*' + "抓取成功" + 50 * '*')
if __name__ == '__main__':url ='http://www.shicimingju.com/book/sanguoyanyi.html'urllist = get_html(url)get_chapter_content(urllist)结果

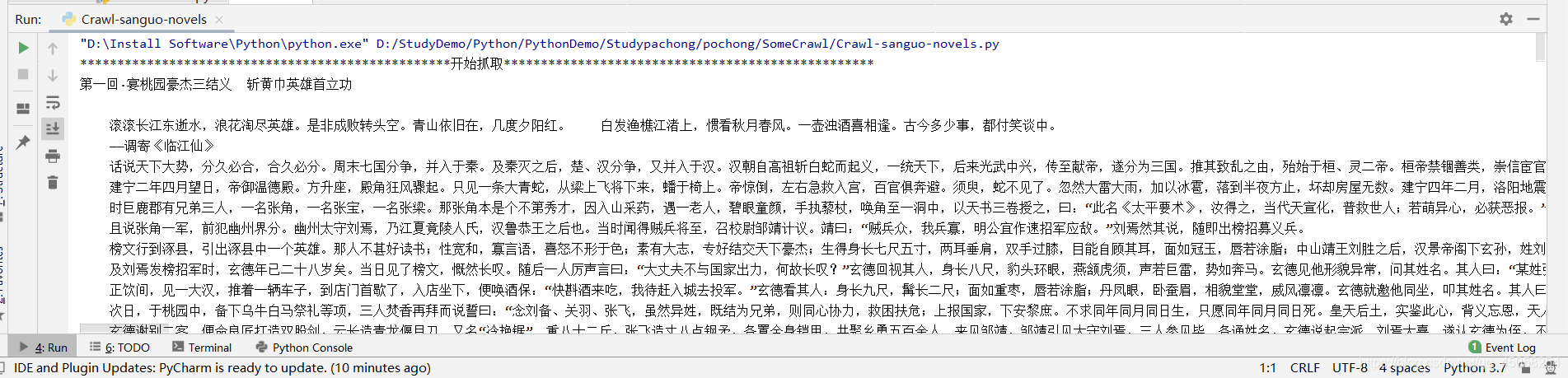
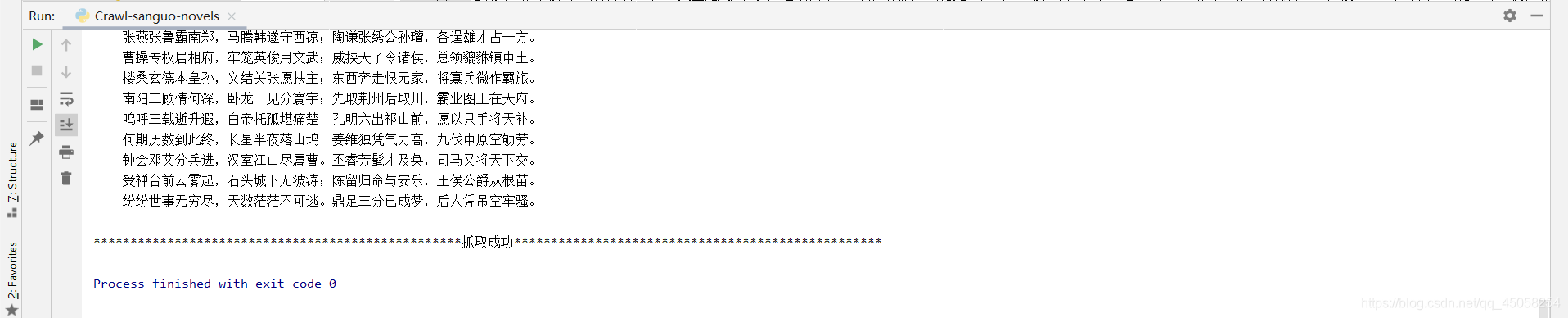
目标网站:http://www.shicimingju.com/book/sanguoyanyi.html
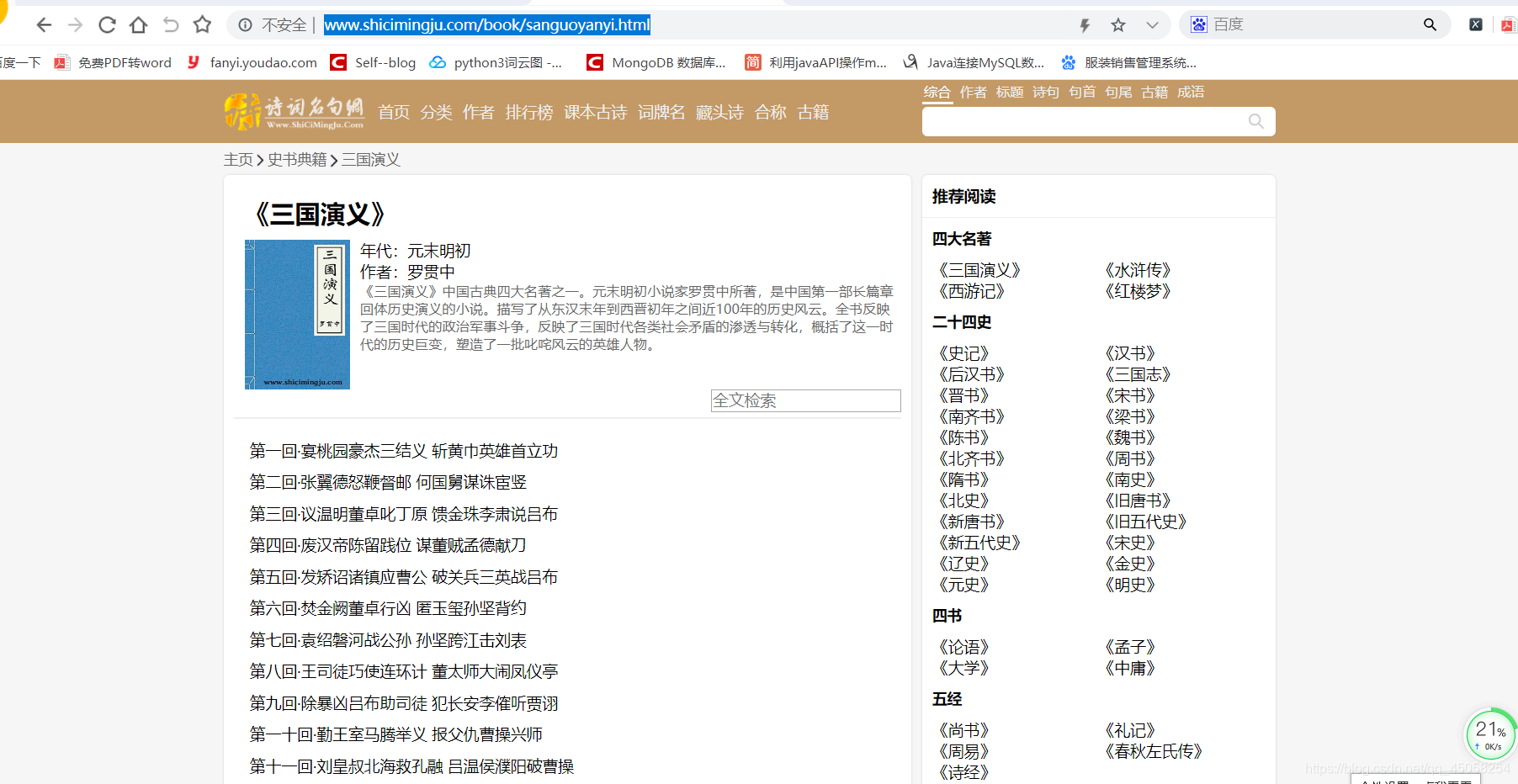
使用xpath提取网页中的想要的信息
每一个章节可从首页获得,xpath为//div[@class=‘book-mulu’]/ul/li/a/@href

每一个章节的标题可由xpath提取为//div[@class=‘card bookmark-list’]/h1/text()

每一个章节的内容可由xpath提取为//div[@class=‘chapter_content’]//p/text()
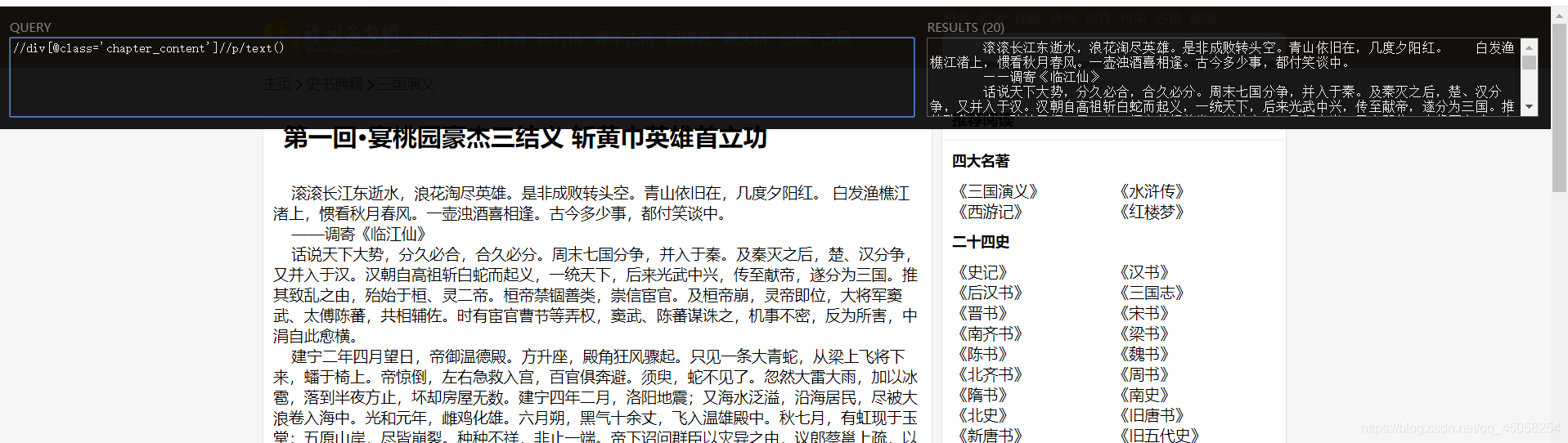
到此完成,整本《三国演义》不大才1.7M

**
这篇关于Python从诗词名句网站中抓取四大名著之一《三国演义》!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







