本文主要是介绍Python制作新型冠状病毒疫情地图-(世界中国),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
之前分享过一篇关于python爬虫制作疫情地图的博客,因为pyecharts版本的不同,其中实现方法也有些许区别。本篇博客中制作地图的代码是在pyecharts 0.5.10版本下完成的。
pyecharts高版本的map地图制作请点这里
1、导包:
import re
from bs4 import BeautifulSoup
from urllib.request import urlopen
from pyecharts import Map, Geo
from world_name_dict import world_name_dict as world_names
说明:
from world_name_dict import world_name_dict as world_names
world_name_dict 是世界各国中英文对照的字典,为显示世界地图做转换。
2、爬虫:爬取疫情数据网页
爬取的疫情详情网页是:丁香园-丁香医生的疫情网页
网页地址:https://3g.dxy.cn/newh5/view/pneumonia_peopleapp
导入urlopen函数,读取网页内容,如果网页中有中文要用“utf-8”解码
html = urlopen("https://3g.dxy.cn/newh5/view/pneumonia_peopleapp"
).read().decode('utf-8')
#获取html网页的源代码
bs= BeautifulSoup(html,"html.parser")
print(bs.body)
3、国内疫情地图:map
(1)对源代码进行操作:
str1=bs.body.text
# print(str1)
str1=str1[str1.find('window.getAreaStat = '):] #查找字符串中指定国内省份对应数据的关键字,进行截取
data = str1[str1.find('[{'):str1.find('}catch')]
data_list=eval(data) #字符串转字典数组
# print(type(data_list))
# print(data_list)
new_dict={} #省份现存确诊数
new_dict1={} #省份累计确诊数
(2) 遍历数据,获取累计确诊与现存确诊:
#循环遍历data_list取数据{省份:确诊数}
for province in data_list:#将省份现存确诊数放入new_dict字典中,处理不合格的省份名称replacenew_dict[province['provinceName'].replace('自治区','').replace('回族','').replace('维吾尔','').replace('省','').replace('市','').replace('壮族','')] = province['currentConfirmedCount']#省份累计确诊数new_dict1[province['provinceName'].replace('自治区','').replace('回族','').replace('维吾尔','').replace('省','').replace('市','').replace('壮族','')] = province['confirmedCount']print(new_dict)
print(new_dict1)
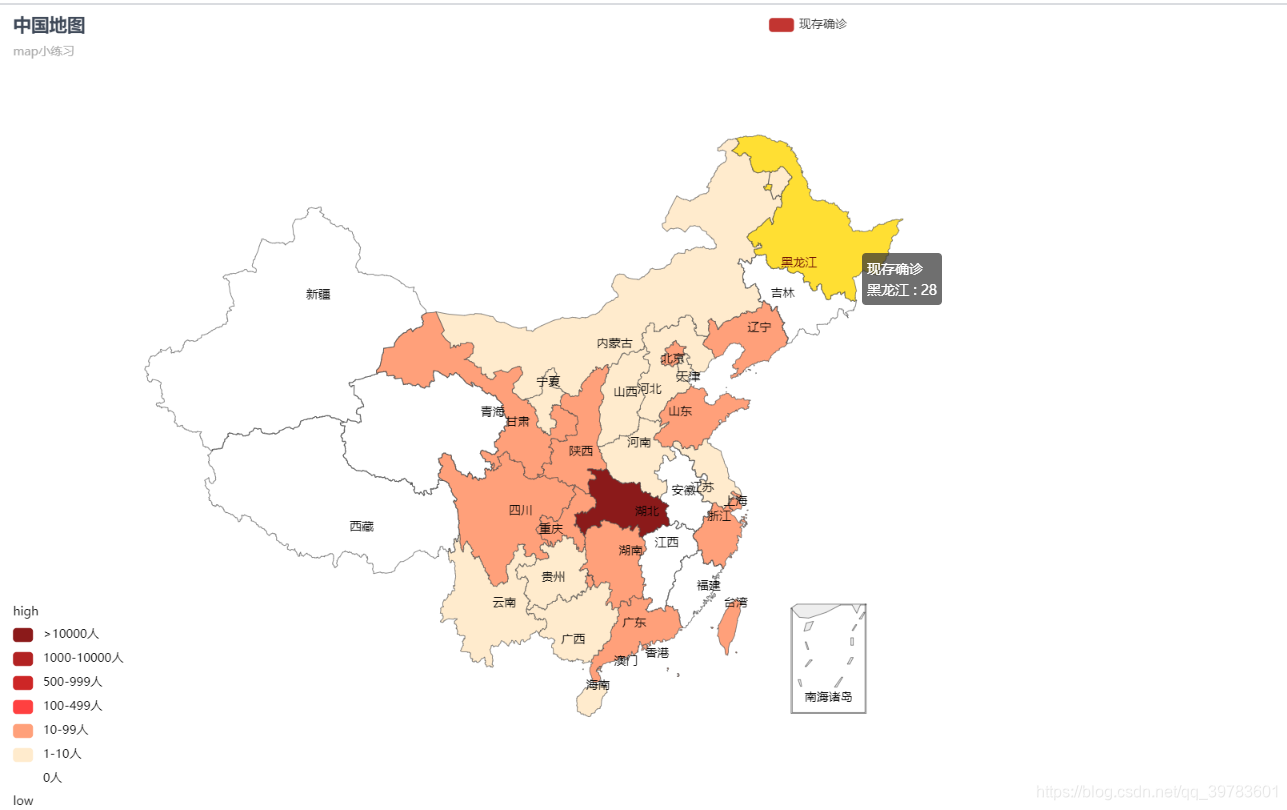
(3) 国内省份地图-现存确诊:
province=list(new_dict.keys()) #将字典中的省份key以列表的形式取出来
values=list(new_dict.values()) #将字典中确诊数values以列表形式取出来
map = Map("中国地图","map小练习", width=1600, height=800,title_pos="left",title_color="#404a59")
map.add("现存确诊", province, values,
pieces=[{"max": 0, "label": "0人", "color": "#FFFFFF"},{"min": 1, "max": 9, "label": "1-10人", "color": "#FFEBCD"},{"min": 10, "max": 99, "label": "10-99人", "color": "#FFA07A"},{"min": 100, "max": 499, "label": "100-499人", "color": "#FF4040"},{"min": 500, "max": 999, "label": "500-999人", "color": "#CD2626"},{"min": 1000, "max": 10000, "label": "1000-10000人", "color": "#B22222"},{'min': 10000, "label": ">10000人", "color": "#8B1A1A"}], # 不指定 max,表示 max 为无限大
isual_range=[0, 1000],is_piecewise=True,is_visualmap=True,visual_split_number=5,maptype='china',visual_text_color='#000',
is_label_show=True,is_map_symbol_show=False)
# maptype='china' 只显示全国直辖市和省级
# 数据只能是省名和直辖市的名称
map.show_config()
map.render(path="G:/疫情地图-中国现存确诊.html")
(4) 国内省份地图-累计确诊:
province1=list(new_dict1.keys())
values1=list(new_dict1.values())
map = Map("中国地图","map小练习", width=1600, height=800,title_pos="left",title_color="#404a59")
map.add("确诊", province1,values1,
pieces=[{"max": 0, "label": "0人", "color": "#FFFFFF"},{"min": 1, "max": 9, "label": "1-10人", "color": "#FFEBCD"},{"min": 10, "max": 99, "label": "10-99人", "color": "#FFA07A"},{"min": 100, "max": 499, "label": "100-499人", "color": "#FF4040"},{"min": 500, "max": 999, "label": "500-999人", "color": "#CD2626"},{"min": 1000, "max": 10000, "label": "1000-10000人", "color": "#B22222"},{'min': 10000, "label": ">10000人", "color": "#8B1A1A"}], # 不指定 max,表示 max 为无限大
isual_range=[0, 1000],is_piecewise=True,is_visualmap=True,visual_split_number=5,maptype='china',visual_text_color='#000',
is_label_show=True,is_map_symbol_show=False)
# maptype='china' 只显示全国直辖市和省级
# 数据只能是省名和直辖市的名称
map.show_config()
map.render(path="G:/疫情地图-中国累计确诊.html")map.add中的标签属性:
map.add():
visual_text_color:标签颜色
is_piecewise :颜色是否分段显示(False为渐变,True为分段)
is_visualmap:是否映射(数量与颜色深浅是否挂钩)
maptype :地图类型,可以是中国地图,省地图,市地图等等
visual_split_number :可视化数值分组
is_label_show = True, # 显示各区域名称
symbol=“circle”:标记的形状(circle,pin,rect,diamon,roundRect,arrow,triangle)
geo_normal_color="#006edd":地图颜色
geo_emphasis_color="#0000ff":鼠标放在地图上的颜色
累计确诊:

现存确诊:
4、世界疫情地图:
(1)处理源码:
str2=bs.body.text
str2=str2[str2.find('window.getListByCountryTypeService2 = '):]
data2=str2[str2.find('[{'):str2.find('}catch')]
data_list2=eval(data2)
# print(data_list2)
world_confirmedCount={} #世界累计确诊数
(2)引用world_name_dict 中的字典(世界中英文字典),将各国名称的中文转换为英文:
for province2 in data_list2:#对特殊字符串做处理world_confirmedCount[province2['provinceName'].replace('钻石公主号邮轮','').replace('其他','')]=province2['confirmedCount']world_confirmedCount[province2['provinceName']]=province2['confirmedCount']try:#获取中英文字典中的key,也就是英文的各国名称world_confirmedCount[[k for (k, v) in world_names.items() if v == province2['provinceName']][0]] = province2['confirmedCount'] # 全世界的国家except Exception as e:print('exception:',province2['provinceName'],' ',e)world_confirmedCount[province2['continents']] = province2['confirmedCount'] #亚洲,非洲...
print(world_confirmedCount)
print("总共有",len(world_confirmedCount),"个国家")
(3)寻找包含中国疫情确诊数据的字符串并截取:
从body的字符串中可知,有关世界疫情的数据中不包含中国的数据,所以我们要取中国的确诊数据,再加入到世界的数据中。即加入到world_confirmedCount中。
ChinaCount=re.search(r'"countRemark":"","currentConfirmedCount":(\-?)\d*,"confirmedCount":(\-?)\d*', bs.body.text)
print("中国现存确诊与累计确诊:",ChinaCount)
(4)进一步取中国确诊数:
对ChinaCount进行操作,去掉字符串countRemark
zs_dict=eval('{'+ChinaCount.group().replace('"countRemark":"",','')+'}')
删除中国的现存确诊currentConfirmedCount,只保留累计确诊
del zs_dict['currentConfirmedCount']
(5)将确诊数confirmedCount的键值key替换为China
zs_dict['China']=zs_dict.pop('confirmedCount')
因为源码中confirmedCount的key值是provinceName,所以要进行替换。
(6)最后将中国加入到世界疫情确诊数中:
# 将中国累计确诊数据{'China': 80981}添加到world_dict
world_confirmedCount.update(zs_dict)
此时world_dict中就包含了所有的国家疫情确诊信息。
(7)绘制世界地图:
country = list(world_confirmedCount.keys())
value=list(world_confirmedCount.values())
print(country)
print(value)
map0 = Map("世界地图示例", width=1400, height=800)
map0.add("世界地图",country, value, maptype="world", is_visualmap=True, is_piecewise=True, visual_text_color='#000',
pieces=[
{"max":0,"label":"0人","color":"#FFFFFF"},
{"min":1,"max":9,"label":"1-9人","color":"#FFEBCD"},
{"min":10,"max":99,"label":"10-99人","color":"#FFA07A"},
{"min":100,"max":499,"label":"100-499人","color":"#FF7F50"},
{"min":500,"max":999,"label":"500-999人","color":"#CD4F39"},
{'min':1000,"max":10000,"label":"1000-10000人","color":"#CD3333"},
{'min':10000,"label":">10000人","color":"#8B0000"} #不指定 max,表示 max 为无限大
],is_label_show = False,is_map_symbol_show=False
)
map0.render(path="G:/新冠肺炎-世界地图.html")
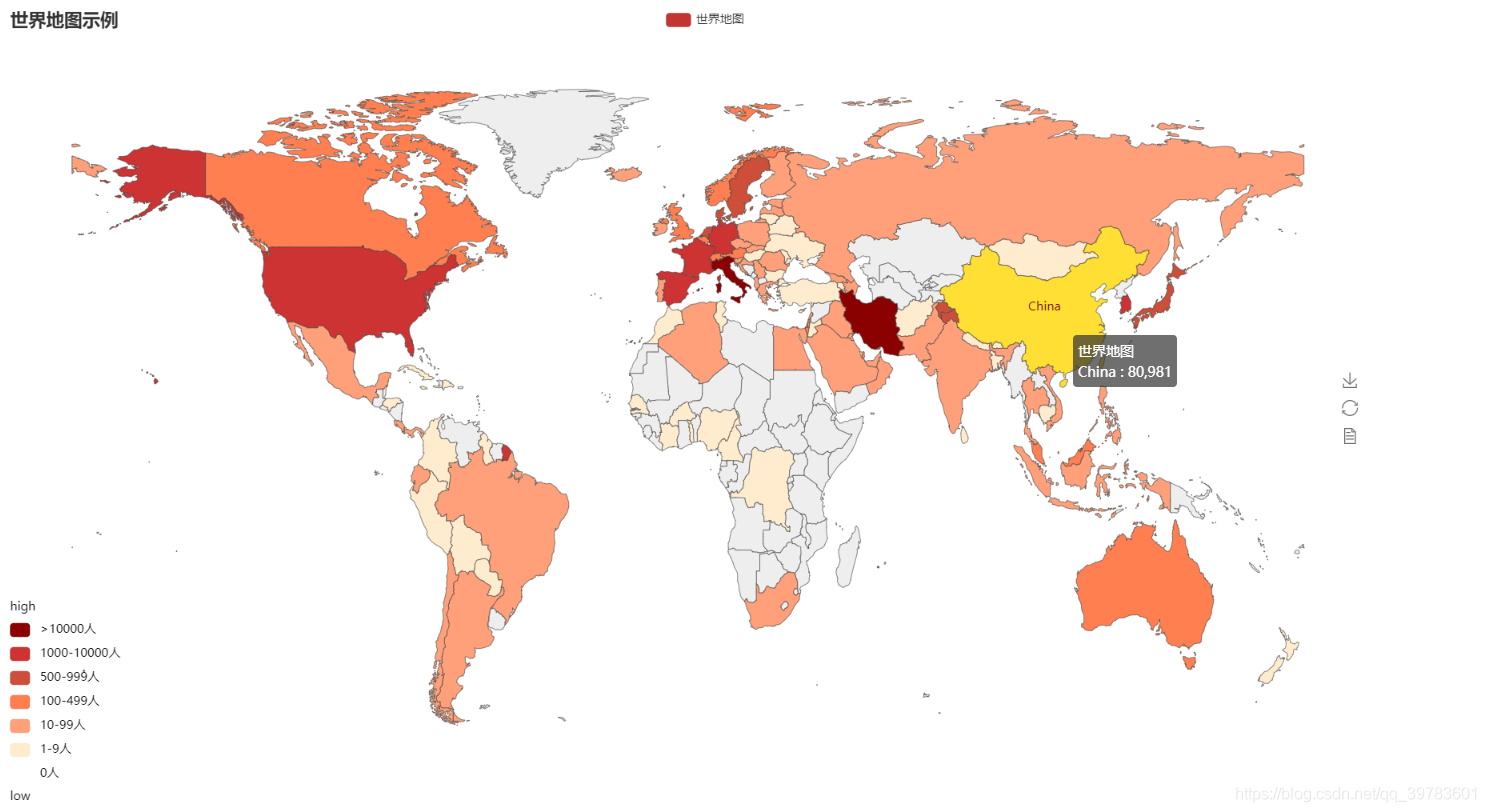
世界地图我只画了累计确诊数据的,现存确诊的你可以自己尝试的画一下哦,方法是一样的。
小白一个,请各位大神指教!
这篇关于Python制作新型冠状病毒疫情地图-(世界中国)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




