本文主要是介绍QGIS 5. 坡向因子的提取,重分类和栅格数量统计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从QGIS 4.笔记开始会陆续推出使用QGIS分析地质灾害因子的方法,比如高程,坡度,坡向等。整个地灾因子系列配图均为我个人论文中的配图,请勿盗用!!!
结果展示
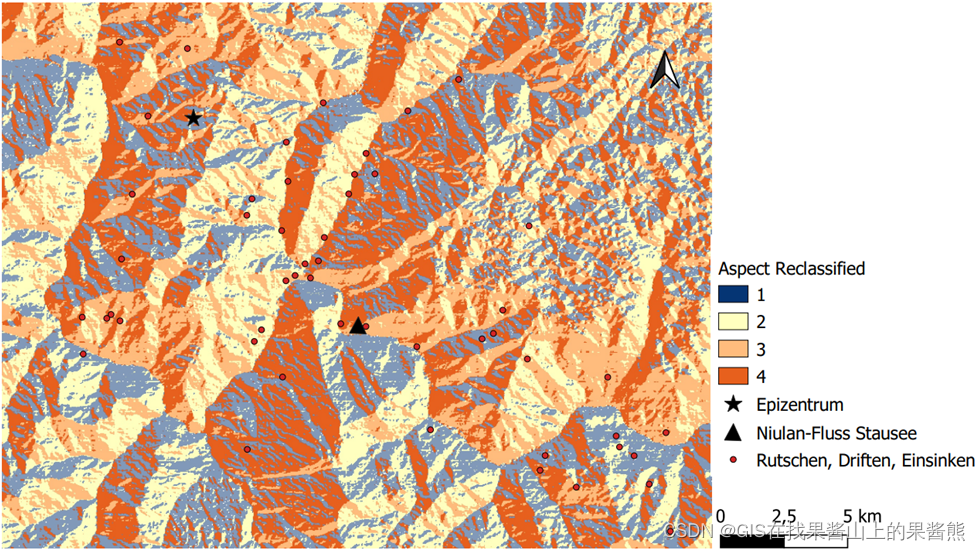
需要数据: DEM高程图,灾害点shp数据
1. 坡向计算
工具> 坡向> 输入图层为DEM图层> 勾选平面返回0而不是-9999和计算栅格边缘数据和无数据值附近的数据,如果不勾选这两项后期重分类和栅格统计会出现栅格数据丢失的情况> 运行

2. 坡向重分类,本次重分类使用按图层重分类的方法
-在excel中自己创立一个分类表格

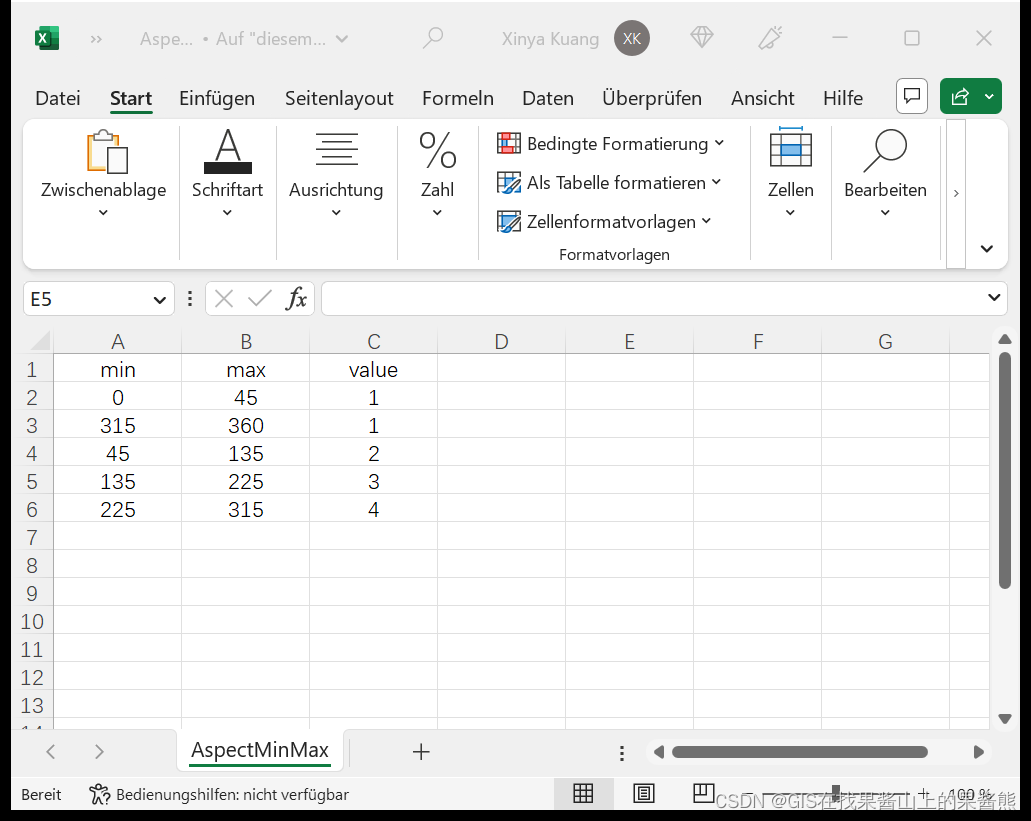
-工具> 按图层重分类> 栅格图层为上一步做好的坡向图层,包含类别间断点的图层为自己分类好的excel表格。(注意表格要保存为csv格式才能导入qgis)。最小最大和值的设置对应excel中的表格设置。>运行
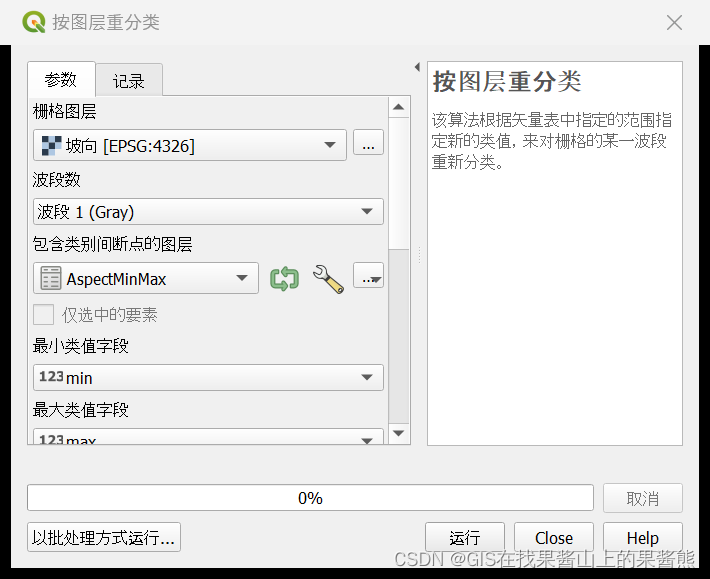
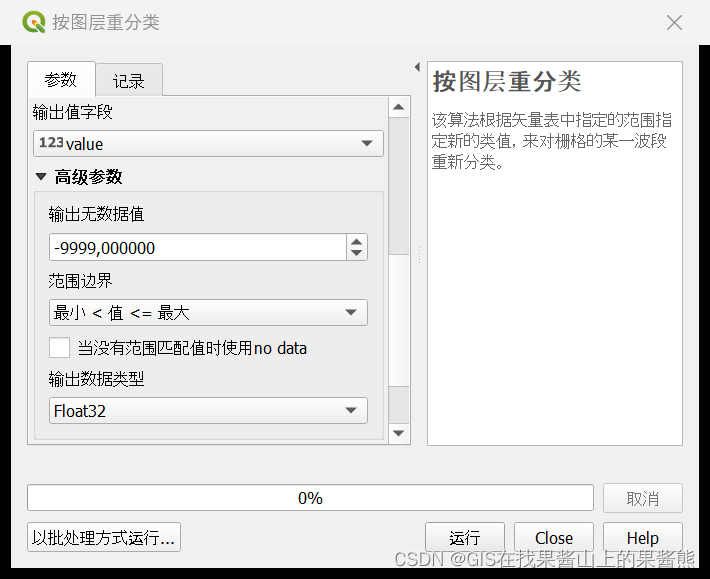
3.右键点击重分类好的坡向图层属性,渲染类型使用唯一值或者单波段伪彩色,我推荐使用唯一值。0值的段可以手动删除这个分类。
结果:
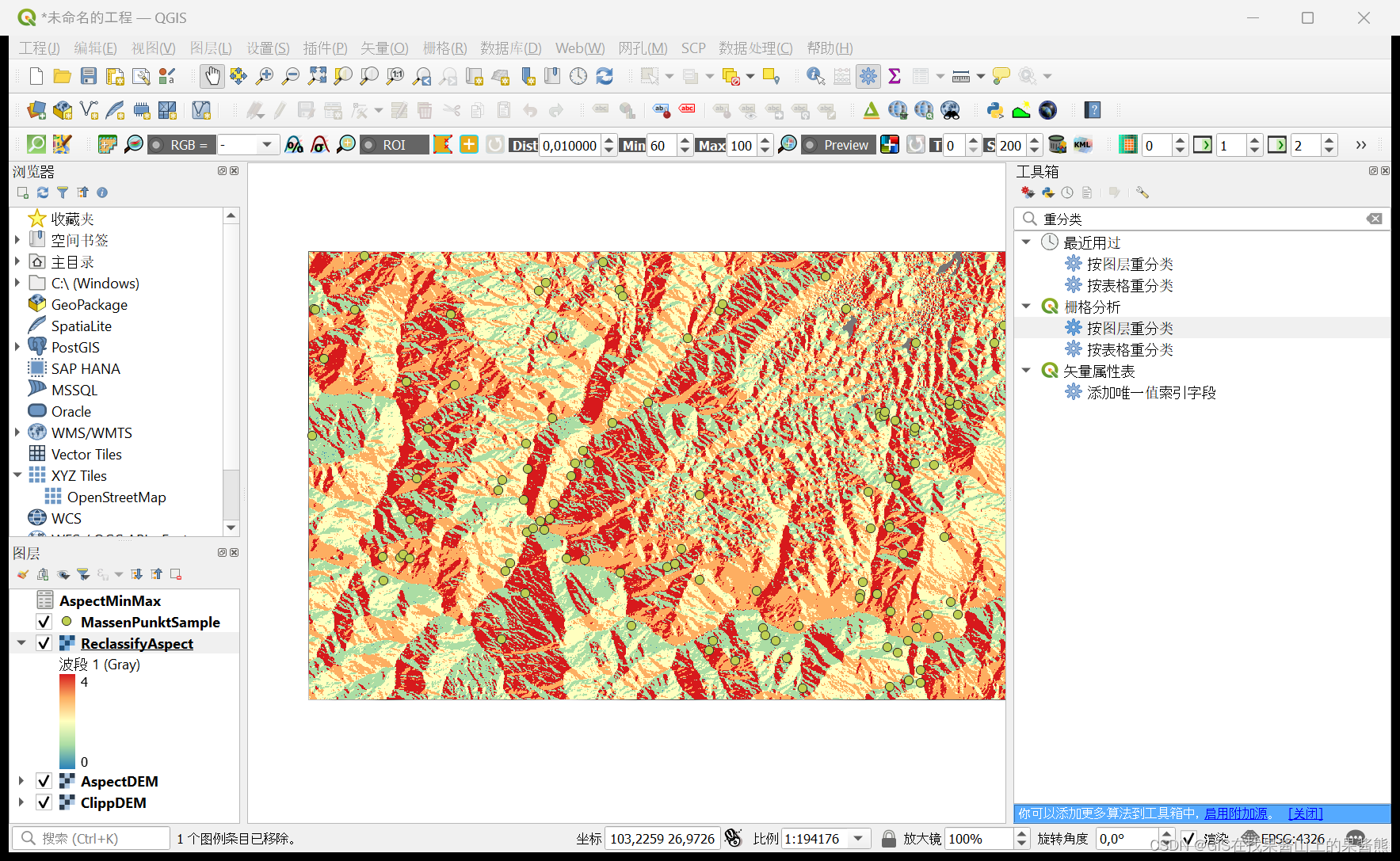
4. 提取灾害点值到坡向重分类
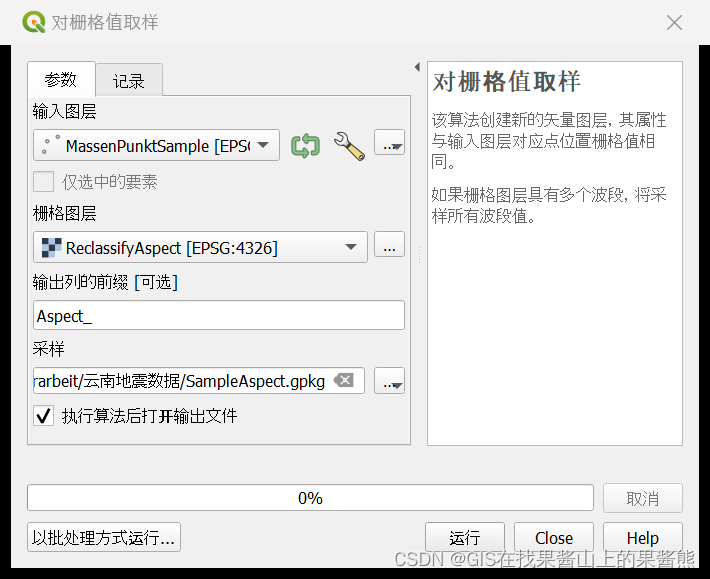
工具> 对栅格值取样> 输入图层为灾害点shp,栅格图层为重分类好的坡向图层
5.栅格数量统计,和笔记QGIS 4.中的步骤相同,具体可看QGIS 4.笔记的最后部分。
工具> 栅格图层唯一值报告栅格图层唯一值报告> 输入图层为重分类好的图层
这篇关于QGIS 5. 坡向因子的提取,重分类和栅格数量统计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







