本文主要是介绍spark中使用flatmap报错:TypeError: ‘int‘ object is not subscriptable,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、背景描述
菜鸟笔者在运行下面代码时发生了报错:
from pyspark import SparkContextsc = SparkContext("local", "apple1012")rdd = sc.parallelize([[1, 2], 3, [7, 5, 6]])rdd1 = rdd.flatMap(lambda x: x)
print(rdd1.collect())
报错描述如下:
2、报错原因
显然这是传入的数据类型发生了错误:
因为我们试图对整数对象执行下标操作,而这是不允许的。
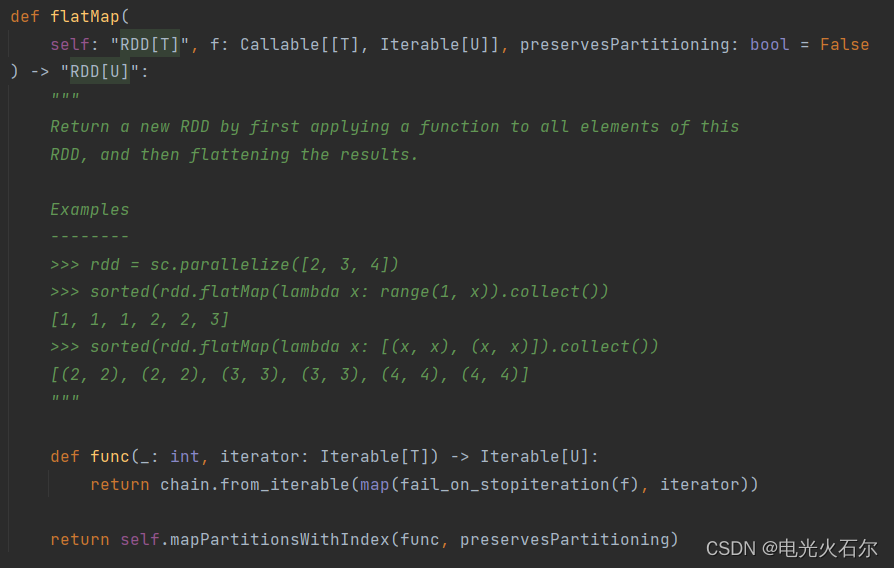
原来flatMap底层通过取下标来展开元素 如果rdd集合里面有非可迭代对象(如int元素)则会报错TypeError: 'int' object is not subscriptable。
查看flatmap算子源码我们知道,传入的参数被要求是一个可迭代对象,那么rdd集合中有int元素报错也就不奇怪了。
3、解决方案
解决方法如下:
我们可以在映射函数内部处理这种情况。例如,如果要返回单个元素,可以将其放入一个列表中,以确保总是返回一个可迭代对象。
from pyspark import SparkContextsc = SparkContext("local", "apple1012")rdd = sc.parallelize([[1, 2], 3, [7, 5, 6]])# flatMap底层通过取下标来展开元素 如果rdd集合里面有非可迭代对象(如int元素)则会报错TypeError: 'int' object is not subscriptabledef my_flatmap(x):if isinstance(x, int):# 如果是整数,将其放入一个列表中return [x]else:# 如果不是整数,直接返回可迭代对象return xrdd1 = rdd.flatMap(my_flatmap)
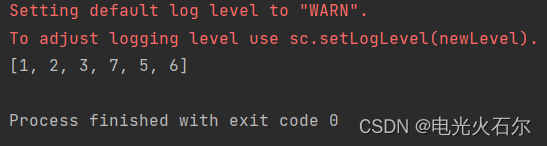
print(rdd1.collect())修改代码后我们运行程序,完美执行:
这篇关于spark中使用flatmap报错:TypeError: ‘int‘ object is not subscriptable的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




