subscriptable专题

ptrade排坑日记——交易策略报错: ‘NoneType‘ object is not subscriptable 。
前言 今天要和大家分享的一个问题是交易策略报错,希望大家在使用ptrade过程中遇见这个问题能够快速解决! 一、问题描述 交易策略报错: File "/home/fly/sim_backtest/result/412974e0-a014-11ee-8735-d4f5ef8c353c/user_strategy.py", line 354, in ocall_BSpx_change_rat

【python报错】TypeError: ‘dict_values‘ Object IsNot Subscriptable
【Python报错】TypeError: ‘dict_values’ object is not subscriptable 在Python中,字典(dict)提供了几种不同的视图对象,包括dict_keys、dict_values和dict_items。这些视图对象允许你以只读方式遍历字典的键、值或键值对。如果你尝试使用索引来访问dict_values对象的元素,会遇到TypeErro

【python】成功解决“TypeError: ‘method’ object is not subscriptable”错误的全面指南
成功解决“TypeError: ‘method’ object is not subscriptable”错误的全面指南 一、引言 在Python编程中,TypeError: 'method' object is not subscriptable错误是一个常见的陷阱,特别是对于初学者来说。这个错误通常意味着你尝试像访问列表、元组、字典或其他可迭代对象那样,去访问一个方法(method)对

Hyperopt TypeError: 'generator' object is not subscriptable
原因与解决方案 原因与解决底层库networkx更新造成的,Hyperopt不支持networkx-2.0,我换成了1.11版本就OK了. pip install networkx==1.11

TypeError: 'builtin_function_or_method' object is not subscriptable的一种错误情况
TypeError: ‘builtin_function_or_method’ object is not subscriptable的一种错误情况 初学python,今天在做练习时为一个Error苦恼了很久 最终找到了解决方法 错误代码块如下 def get_new_nums():numbers = input('Well, I don\'t know your favorite numb

scrapy pymysql TypeError: ‘NoneType‘ object is not subscriptable
错误提示:TypeError: ‘NoneType’ object is not subscriptable 由于多个下载管道优先级的原因导致 一个scrapy项目写了很多爬虫,把当前爬虫的管道优先级设置成最高即可。
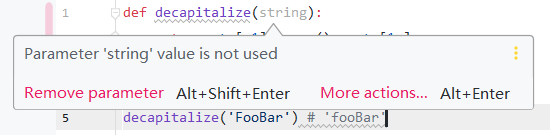
Python 报错 TypeError: 'type' object is not subscriptable
输入代码,结果出现以下报错: TypeError: 'type' object is not subscriptable 翻译成中文就是“类型”对象不可下标。 检查报错时的代码: def decapitalize(string):return str[:1].lower() + str[1:] 问题产生原因分析: 在定义函数的时候,使用的名称是string;而后面调用却用的是st
![遇到问题[已解决]TypeError: ‘odict_keys‘ object is not subscriptable](https://img-blog.csdnimg.cn/01be999d6e7a4f4c9b82bc30f0f6c85c.png)
遇到问题[已解决]TypeError: ‘odict_keys‘ object is not subscriptable
背景 运行CPD代码时,由于源代码踊跃python2.7,但是我的是3.8出现报错 【Python3】【报错】- TypeError: ‘dict_keys‘ object is not subscriptable-CSDN博客 原因: 在Python3中,keys()方法不允许切片 VGG代码如下 解决办法: 就是把keys改为list(keys)
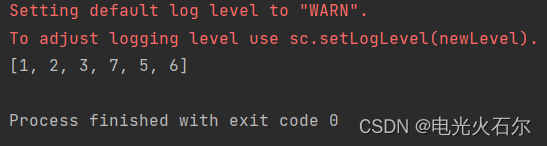
spark中使用flatmap报错:TypeError: ‘int‘ object is not subscriptable
1、背景描述 菜鸟笔者在运行下面代码时发生了报错: from pyspark import SparkContextsc = SparkContext("local", "apple1012")rdd = sc.parallelize([[1, 2], 3, [7, 5, 6]])rdd1 = rdd.flatMap(lambda x: x)print(rdd1.collect())
spark中使用flatmap报错:TypeError: ‘int‘ object is not subscriptable
1、背景描述 菜鸟笔者在运行下面代码时发生了报错: from pyspark import SparkContextsc = SparkContext("local", "apple1012")rdd = sc.parallelize([[1, 2], 3, [7, 5, 6]])rdd1 = rdd.flatMap(lambda x: x)print(rdd1.collect())

Python报错“TypeError: ‘Response‘ object is not subscriptable”如何解决?
问题: 原因: 返回的类型还未转换为json格式,就进行获取参数的操作。 解决方法: 后面加.json() resp_id = resp.json()

高效解决 TypeError : ‘ numpy._DTypeMeta‘ object is not subscriptable 问题
文章目录 问题描述解决问题 问题描述 解决问题 参考博文 打开报错位置 AppData\Roaming\Python\Python39\site-packages\cv2\typing\ 添加single-quotes,即单引号 博主说The trick is to use single-quotes to avoid the infamous TypeEr