本文主要是介绍pandas数据处理 + matplotlib可视化(电影票房分析),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、首先导入包
# 导入库
import numpy as np
import matplotlib.pyplot as plt # 绘图的库
import pandas as pd
2、读取文件
# 读取、打开文件
df = pd.read_csv(open('E:\电影票房.csv',encoding='ANSI'))
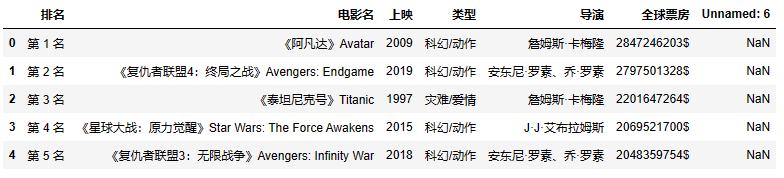
df.head(5)
我们的文件含有中文名,加上open( )好一点
查看数据如下
3、使用iloc( )切片数据
df = df.iloc[:,[3,5]] # 切出行的全部、列的第3第5列
df.head(5)
这里顺便可以讲一下 iloc( ) 和 loc( ) 的区别,iloc 是使用索引取数据,loc 使用列名取数据;
上面的写法用 loc( ) 可以写成:
data.loc[:, ['类型', '全球票房']] # 等同于data.iloc[:, [3, 5]]

4、分割、聚合数据
从第三题的 “类型” 列来看,有两种类型合在一起了(有的一种、有的两种),有两种的由 “竖杠” 分隔;我们要取出两种类型,形成两个列 “类型1” 和 “类型2” (也就是说这里的一个电影有两种类型)
首先定义一个函数,传入 item ,返回的内容是跟据斜杠分隔的 索引 为0的数据,这个是取第一个类型
def func1(item):return item.split('/')[0]
再定义一个函数,取第二个类型;有可能 “类型” 这一列只有一个类型,所以用 if 做个判断,如果有两个类型,就取索引为 1 的那个类型,没有第二个类型就用 0 替代 (后面要把 “类型2” 是 0 的行删除)
def func2(item):if '/' in item:return item.split('/')[1]else:return 0
接下来调用函数,就是让 “这个” 数据通过筛选
df['类型1'] = df['类型'].map(func1)
df['类型2'] = df['类型'].map(func2)
我们看到的数据后面的 .map( func1 )其实是进行匹配、换算,如果一个数据后面写 .map(float) 就是把这个数据类型转换成单精度类型
接着用 iloc( ) 继续取需要的数据
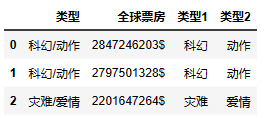
data_1 = df.iloc[:,[2,1]]
data_2 = df.iloc[:,[3,1]]
data_2 = df[data_2['类型2'] != 0] # 剔除“类型2”中为0的项
data_2.head(5)
然后 data_2的数据就如下所示
5、去除 “全球票房” 后面的单位 “ $ ”
在第四题后面我们可以看到 “全球票房” 后面有个单位
这个有两种方法可以做
# 去除 ‘全球票房’ 后面的 ‘ $’data_2['全球票房'] = data_2['全球票房'].str[:-1]
data_2

这里的,str里取的 “-1” 和冒号的意思就是取 “从开头到最后一个(不包含最后一个)”
也可以使用 .replace( “原字符”, “新字符”) 这种方法替换,新字符的地方不用写,直接冒号得了
6、数据单位的转换
跟据第五题后面的图片可以看到,“全球票房” 的数值太大,我们可以把 “元” 变成 “亿元”,就是除以相应的数
# data_2['全球票房'] = data_2['全球票房'].astype('int64')def to_million(x):dollar = round(float(x)/100000000,4)return dollar
data_2['票房(亿元)'] = data_2['全球票房'].map(to_million)
data_2.head()
方法同样是自定义一个函数:
这里的 round( ) 就是用于保留多少位小数的, round(data, 2):就是保留两位小数,里面的float(x)就是强制转换 x 的数据类型为单精度类型, 4 就是保留 4 位小数
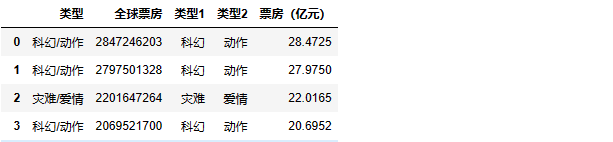
可以看见,换完单位我们的数值小很多,方便后面的可视化操作
7、跟据类型把票房分组求和
# 根据类型分组求和df_counts = data_2[['类型1','票房(亿元)']].groupby('类型1').sum()
df_counts
将数据里面的 “ 类型1 ” 和 “ 票房(亿元)”两个数据单独拿出来
再计算各个类型的总票房(求和),我们把类型单独拿出来分成 类型1 和 类型2 之后还有重复的(这里的重复指的是类型重复,我们要计算这个榜单各个类型的电影有多少票房),现在把他们加起来

8、数据可视化操作
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates
然后准备数据(同时,把数据转化为列表),可视化只要列表数据
y = df_counts.index.tolist()
x = df_counts['票房(亿元)'].tolist()
# 设置画布
fig, ax=plt.subplots(figsize=(8,8))
# 设置标题
plt.title("全球票房")
# 画图(圆形)
plt.pie(x = x,labels = y,autopct='%.0f%%') # autopct='%.0f%%'是让饼图显示
# 设置图例
plt.legend(ncol=6,loc='upper right') # loc 这里这个用于表示图例显示的位置# 让饼图变圆
plt.axis('equal')plt.show()
这篇关于pandas数据处理 + matplotlib可视化(电影票房分析)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






