本文主要是介绍论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】
- 背景:数据分析师工作范围
- 基于GPT-4的端到端数据分析框架
- 将GPT-4作为数据分析师的框架的流程图
- 实验分析
- 评估指标
- 表1:GPT-4性能表现
- 表2:专业的数据分析师与GPT-4的比较
- 表3:
- 启发
论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】
为了更加清晰地理解ChatGPT等大模型对数据分析领域的影响和帮助我们在工作中灵活应用大模型,下面我们来阅读一下阿里达摩院与新加坡南洋理工大学的一篇评估GPT-4作为数据分析师能力的论文。
| 论文标题 | Is GPT-4 a Good Data Analyst? |
|---|---|
| 论文地址 | https://arxiv.org/abs/2305.15038 |
| 论文预览 | https://browse.arxiv.org/pdf/2305.15038.pdf |
| GitHub代码地址 | https://github.com/DAMO-NLP-SG/GPT4-as-DataAnalyst |

在论文中,为了回答“GPT-4是否是一位好的数据分析师”的研究问题,作者设计了一项对比研究。他们将GPT-4视为一位数据分析师,并使用各种领域的数据库进行端到端的数据分析。
为了进行实验,他们精心设计了GPT-4的提示信息,并设计了几个针对特定任务的评估指标,以系统地比较几位专业的人类数据分析师和GPT-4之间的性能。
实验结果表明,GPT-4在性能方面可以击败一个初级数据分析师,并且在性能上可以与一位高级数据分析师相媲美。在成本和时间方面,与雇佣一位数据分析师相比,GPT-4更便宜和更快速。
另外,作者还对评估结果进行了深入讨论,通过理解这些内容可以启发我们在数据分析领域中ChatGPT/GPT-4等大模型的灵活应用。
背景:数据分析师工作范围
通常而言,数据分析师的主要工作范围包括如下:
- 收集数据并进行初步处理。
- 清洗数据,将原始数据转化为可供分析的数据。
- 描述性统计分析,对数据进行描述和总结。
- 探索性数据分析,通过图表、报告等方式展示数据。
- 推断性分析,根据已有数据推断出未知信息。
- 预测性分析,基于历史数据预测未来趋势。
在论文中也介绍了数据分析师的主要工作范围:包括利用业务数据识别有意义的模式和趋势,并为利益相关者提供有价值的洞察,以支持战略决策。
为了实现这一目标,数据分析师必须具备包括SQL查询编写、数据清洗和转换、可视化生成和数据分析等。
基于上述提到的三个主要技能,数据分析师的主要工作范围可以分为三个步骤:数据收集、数据可视化和数据分析。
初始步骤涉及理解业务需求并决定哪些数据来源与解答问题相关。一旦确定了相关的数据表,分析师可以通过SQL查询或其他提取工具提取所需数据。
第二步是创建图表和图形等可视化工具,有效传达洞察。
最后,在数据分析阶段,分析师可能需要确定不同数据点之间的相关性,识别异常值和离群值,并追踪随时间变化的趋势。从这个过程中得出的洞察可以通过书面报告或演示文稿传达给利益相关者。
基于GPT-4的端到端数据分析框架
对于典型的数据分析师工作范围,论文作者提出了一个端到端的自动化框架(end-to-end automatic framework),用于进行数据收集、可视化和分析。
端到端的自动化框架(end-to-end automatic framework)是一种用于自动化数据分析和处理的框架。该框架通过以下三个主要步骤来实现自动化:
-
代码生成(code generation):利用GPT-4的能力,根据输入问题和数据,自动生成相应的代码。这些代码用于数据处理和分析。
-
代码执行(code execution):运行生成的代码,从数据库中提取数据并生成图表(处理和分析数据)。
-
分析生成(analysis generation):对提取的数据进行分析,识别趋势、模式和洞见。自动生成分析报告或可视化结果,帮助用户更好地理解和解释数据,
将GPT-4作为数据分析师的框架的流程图
使用GPT-4自动化整个数据分析过程如下图所示:
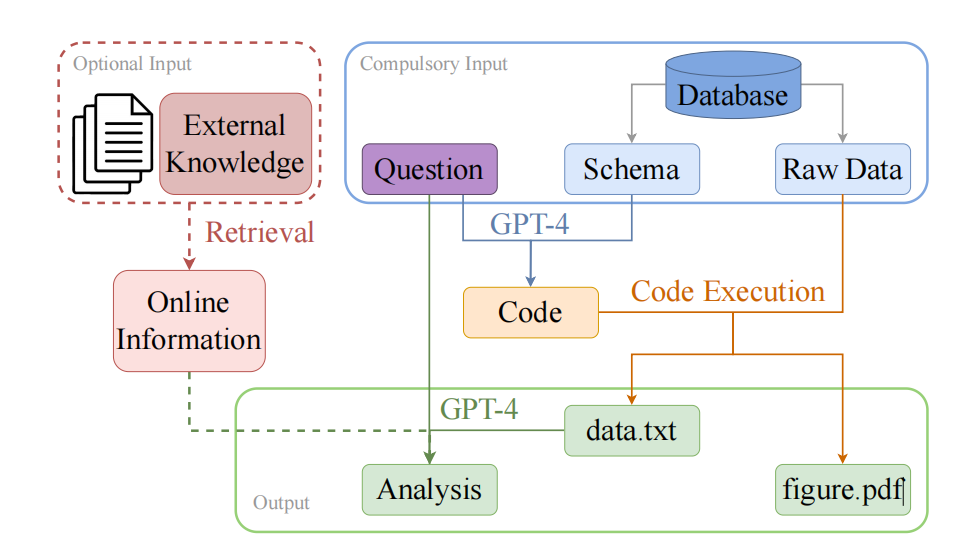
※图1:将GPT-4作为数据分析师的框架的流程图
将GPT-4视为数据分析师的框架的流程可以表示为以下步骤:
-
接收业务问题和数据库:
GPT-4必需的输入信息包括业务问题和数据库(右上方的蓝色框所示)。
业务问题提供了分析数据的目的和目标,而数据库则为GPT-4提供了所需的数据来源。 -
对业务问题和数据库进行分析:(生成代码)
GPT-4根据用户提出的问题,理解和解析数据库中的数据(Schema),生成SQL和可视化代码,以便找到与业务问题相关的数据。 -
从数据库中提取数据:(执行代码)
根据业务问题和数据库的分析结果,GPT-4从数据库中提取与业务问题相关的数据。
这可以包括从数据库中检索特定类型的数据,或者根据业务问题的需求对数据进行筛选、处理和清洗。
GPT-4需要处理提取的数据,这可能包括统计分析、预测模型的构建等。同时,GPT-4还需要将处理后的数据可视化,例如创建图表、图形或图像来帮助理解和解释数据。 -
接收可选输入
可选输入指的是外部知识来源,用于查询与问题相关的额外文本信息(左上方的红色虚线框)。 -
输出提取的数据、数据可视化和分析结果:(生成分析)
GPT-4根据需要输出提取的数据、数据可视化的结果和分析结果(底部的绿色框)。
这些输出可以包括“data.txt”文件(包含提取的数据)、“figure.pdf”文件(包含数据可视化的结果)和分析报告(包含分析结果)。
实验分析
在论文中设计了上述框架,让GPT-4从各种领域数据库中进行端到端的数据分析,并将其性能与使用精心设计的任务特定评估指标的专业人类数据分析师进行了比较。
评估指标
作者精心设计了几个人工评估指标,分别评估生成的图表和数据分析。
图表评估包括如下3个指标:
- 信息准确性:图表中显示的数据和信息是否准确?
- 图表类型准确性:图表类型是否与问题要求匹配?
- 美观度:图表是否美观清晰,没有任何格式错误?
分析评估包括如下4个指标:
- 准确性:分析中是否包含错误的数据或信息?
- 对齐度:分析是否与问题一致?
- 复杂度:分析的复杂程度和深度如何?
- 流畅度:生成的分析是否流畅,语法正确,没有不必要的重复?
通过几个表格列举了GPT-4模型和数据分析师的各种比较数据。
表1:GPT-4性能表现
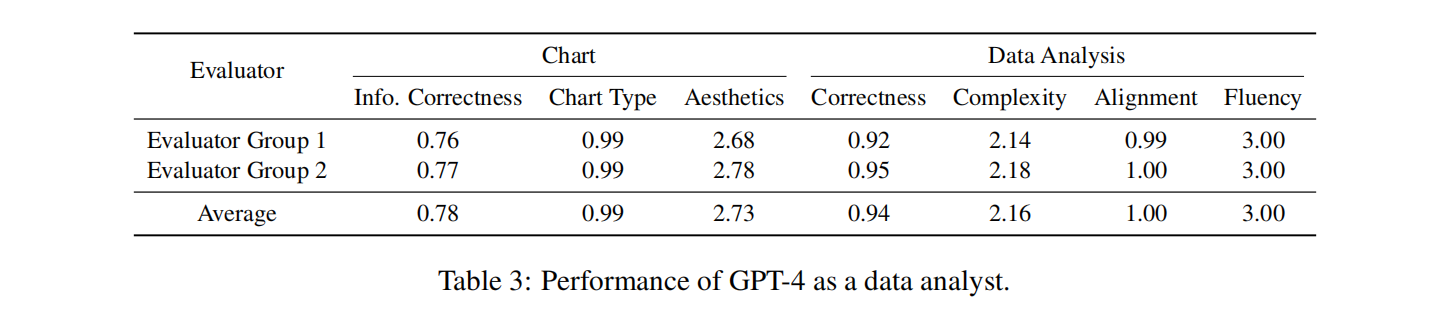
上表是GPT-4模型作为数据分析师的性能表现。
GPT-4在图表处理(生成)方面的各指标如下:
- 信息准确性:平均得分为0.78(满分为1),尽管存在一些小错误,但大多数图表基本上能够获得正确的结果。
- 图表类型准确性:平均得分为0.99%(满分为1),几乎满分的分数
- 美观度:平均得分为2.73(满分为3),大多数生成的图表对观众来说清晰无误,没有任何格式错误。
GPT-4在数据分析方面的各指标如下:
- 准确性:平均得分为0.94(满分为1),分析的正确性得分平均比图表的信息正确性得分要高得多。
- 复杂度:平均得分为2.16(满分为3),合理且令人满意
- 对齐度:平均得分为1.0(满分为1),满分
- 流畅度:平均得分为3.0(满分为3),满分
表2:专业的数据分析师与GPT-4的比较
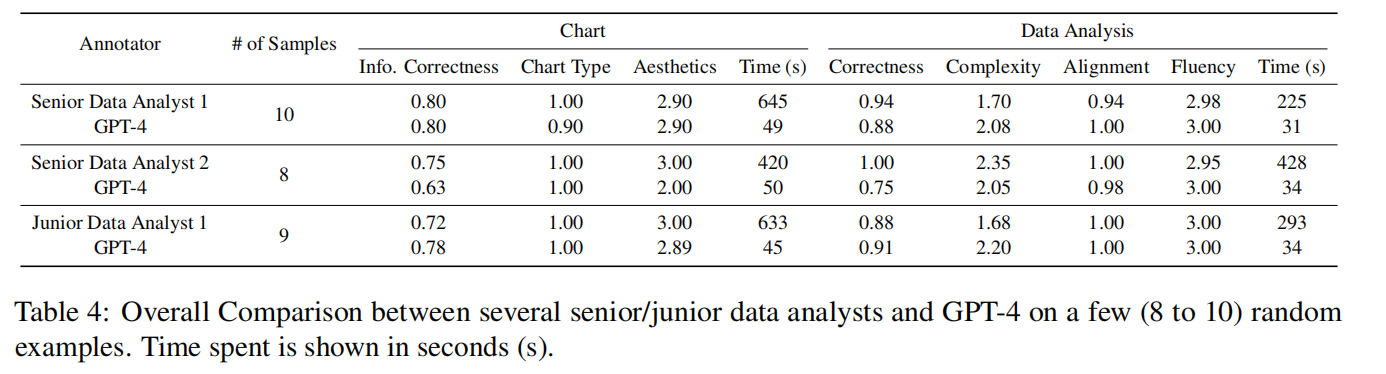
专业的数据分析师与GPT-4的比较结果显示GPT-4能力介于初级分析师和高级分析师之间,但GPT-4花费的时间比人类数据分析师要短得多。
表3:
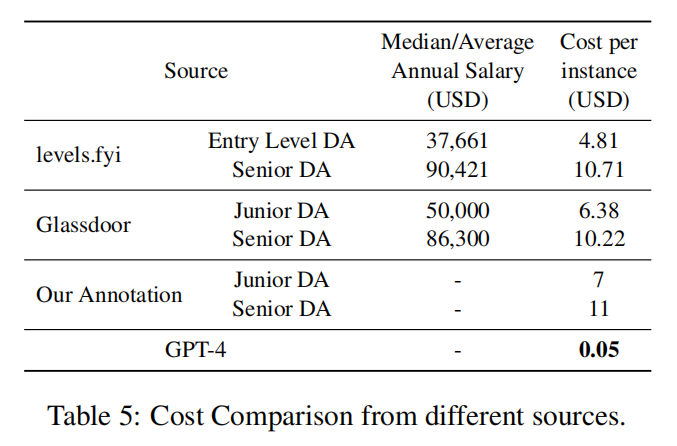
GPT- 4的成本约为初级数据分析师成本的0.71%,高级数据分析师成本的0.45%。
启发
通过这篇论文,我们可以学到以下几点:
-
如何使用GPT-4模型进行数据分析。
首先,需要提出一个问题,然后根据问题的性质选择合适的图表类型,并使用适当的软件或编程语言生成图表。最后,需要对数据进行分析以识别趋势、模式和洞察力,从而回答初始问题。 -
端到端的框架来自动化整个数据分析过程。
该框架包括三个步骤:代码生成、代码执行和分析生成。通过执行Python代码,可以获得图表和提取的数据。然后,使用GPT-4模型生成分析和见解,以强调关键要点。
根据业务场景,我们也可以借鉴这个框架来设计符合特定要求的自己框架。 -
大模型(如GPT-4)在数据分析领域具有潜力和应用价值。
尽管目前还没有关于是否可以用人工智能完全替代人类数据分析师的明确结论,但论文研究试图通过进行一系列初步实验来回答这个问题。通过实验的结果可以看到大模型(如GPT-4)在数据分析领域具有潜力和应用价值。在实际工作中,我们可以继续探索如何利用大模型技术来提高数据分析的效率和准确性。 -
数据分析师面临着巨大的挑战。
只有不断学习并跟上技术的发展和变化,在未来才能够有一席之地。
这篇关于论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







