https://blog.csdn.net/qq_33445835/article/details/80143598
快速2D到3D转换
摘要
- 深度图的分辨率可能要比其相关联的2D图像要低;
- 能够被高度压缩;
- 保留了2D的兼容性;
- 实时生成立体或者多路立体影像成为可能。
1.简介
最近几年,大众对3D内容的需要如雨后春笋般勃起(强行给自己加戏 )。这很大程度上是由于multiviewer3D立体显示器的商业可用性,比如Stereographics【1】,4D-Vision【2】,Philips【3】(是3家厂商)制造的这些显示器。
)。这很大程度上是由于multiviewer3D立体显示器的商业可用性,比如Stereographics【1】,4D-Vision【2】,Philips【3】(是3家厂商)制造的这些显示器。
这些自由立体显示器要求很多场景的临近的视角,通常是八个或者九个,而不是先前的立体显示技术简单的左右眼视角。基于原材料,使用CGI可以为这些显示器创建初始的内容,同时消费者对于视频格式的需求是最强的。使用同步摄像头实时拍摄多视角已经尝试过,尤其是为了inside shots(原意为内线进球,我不太懂篮球,不知道这个该怎么翻译),但是已经被证明笨重而且耗时。
我们之前已经提到,2D到3D转换的优点是为原2D图像【4】生成深度图。这项技术让现有内容、现场直播、录像的转换到达了商业级别的服务处理层次。
深度图的使用,作为2D转3D过程中的一部分,拥有许多令人满意的特性。用户测试表明,在当前可用的自由立体显示器下,深度图的分辨率可能会比立体图像降格之前的相关联的2D图像要低,这一点显而易见。典型的,对于彩色电视广播标准分辨率的2D图像,深度图分辨率会有4:1的减少。
因为深度图有着更低的分辨率,只含有亮度信息(原文为luminance information),它的带宽和存储要求会比相关联的2D图像更低。最佳压缩技术可以将深度图压缩到不到它相关联2D图像【4】的2%的大小。这使得能将深度图嵌入到原来的2D图像中,最低限度的覆盖,能够生成一幅2D兼容3D的图像。
软件或者硬件解码器可以随后实时渲染单独的立体对,或者一系列适合展示于立体显示器上的大范围的视角图像。
2.深度图的生成
大量能够实时同步捕捉深度图以及2D资源的设备现已上市。这些设备包含“3D摄像头”,“Z轴摄像头”或者其他基于扫描激光【6】【7】的传感器。这些系统能够做到实时播放并且不再需要内容转换。在未来,实时录制最有可能成为主要的3D视频生成方法,但是在教育已有的2D内容创造者学会这项新艺术,以及在工作室实现这项技术相关联的花费两方面,仍然存在着重大的挑战。
同时,2D内容的转换,或者是已经存在的,或者是为了在3D屏幕上显示特地拍摄的,都是商业上可行的选项。考虑到巨大的已有2D材料的库存,用户是有保证的。基于深度图产生的由已有内容的2D转3D现在已经是一项确定的过程。这个技术的主要缺点是生成深度图技术的巨大人力成本,导致其成为了一项耗时昂贵的方法。
这里是一些目前应用于产生深度图的人工方法,如下:
- 手动人工,用艺术性选择的深度值绘制物体的轮廓;
- 半自动画轮廓,然后由操作员手动修正。
其中每一个都有一些缺点。手动绘制的深度图质量很高但是十分耗时而且高价。半自动绘制当遇到复杂轮廓时通常不可靠。
尽管在特定条件下基于单目2D图像序列的全自动深度图恢复已经成为可能,这些技术相关联的操作约束限制了其商业化的可行性。这些方法通常可以归入以下一至两种类别:
- 基于运动的深度(Depth from motion):物体的运动(基于摄像头)和它距离摄像头的距离之间的关系可以通过分析optic flow【8】(视觉流?)来计算深度图。如果所有物体的运动与他们到摄像头的距离成比例的话,那么这项技术只能准确恢复相对深度。这个设想仅适用于遇到的是相对较小比例的连续镜头(比如,一个摄像机移过一个静止的场景)。这个原理,利用了运动视差,也是单镜头立体系统【9】和双目延迟立体影像【10】的基础。
- 基于运动的结构(Structure from motion SFM):SFM是计算机视觉研究的一块活跃的区域,有关对应着随后那些被用来决定深度的帧(或者相同场景的相似视图),以及恢复摄像头参数【11】【12】。这个方法的一个限制是3D场景必须以静止为主——意味着物体必须保持静止。此外,摄像头相对这个静止的场景必须在移动。尽管这项技术已经被用于特效产业来用CGI合成实景拍摄连续镜头,这项深度恢复应用仍然有一定的局限性。
同时也应该指出,这些技术依赖找到帧之间的对应关系,而这个过程在出现低特征,快速移动物体时并不可靠。并且,在没有任何运动的情况下,这些全自动技术并不能恢复深度。
3.改良深度图生成
这篇论文中的研究介绍了一个针对2D到3D转换问题更实用的方法。我们已经开发出一种高效交互式、半自动的方法,在其之中,一位特效美术师使用机器学习算法指导深度图的生成。
3.1 机器学习算法(MLAs)
一个MLA,你可以把它当做一个被训练来学习一系列输入和输出之间关系的黑盒。就其本身而言,大部分的MLAs包含两个阶段,训练和分类。在我们对MLAs的应用中,输入是和单个像素的位置和颜色有关的。为了实现,我们对一个像素定义了5个输入参数:x,y,r,g,b。对任何给定的像素来说,x和y代表的是笛卡尔坐标,r,g,b分别代表的其颜色的红,绿,蓝分量。MLA的输出是像素的深度,我们将其表示为输出z。
3.1.1 训练
在训练的阶段中,给MLA提供的样本是有已知的深度的:
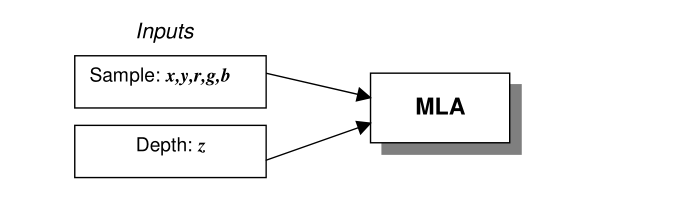
MLA会调节它的内部结构来学习样本和它对应深度之间的关系。学习过程的细节根据使用算法的不同而有所改变。比较流行的算法包括决策树和神经网络,具体的细节超出了本文的内容,不予详述。
3.1.2 分类
在分类的阶段中,在MLA中,有未知深度值的样本被提交,然后用在训练中建立的关系去确定一个输出深度值。

这个学习过程应用在快速2D到3D转换过程中的两个相关阶段:
- 深度绘图(Depth mapping):给关键帧指定深度
- 深度渐变(Depth tweening):在先前阶段中映射的关键帧之间的帧,为它们产生深度图。
3.1.3 深度绘图
在快速2D到3D转换的深度绘图阶段中,MLA被应用于单个关键帧。手工深度绘图技术传统上使用者为原图像的每一个像素都要关联一个深度,代表性的是通过操作一些几何物体(比如贝赛尔曲线)。通过使用MLA,我们能够显著减少生成一幅深度图的工作量。

图1:(左)一幅例子源帧——圆点指出了训练样本的位置。圆点的颜色表明了像素点所对应的深度。一条水平线可以用来加上深度坡。(右)由加了深度坡的MLA得到的完成的深度图。
3.1.4 深度渐变
关键帧的深度图是由上面提到的方法产生。这些帧策略性地分布在视频序列中,每当有物体的颜色或者位置有大的改变时。关键帧可以是手动确定,也可以使用技术来自动操作这个过程,比如检测突变的技术。
在快速转换方法的深度渐变阶段,MLAs被用来产生任意两个存在的关键帧之间的深度图。图2阐明了这个过程。如图,为了每一个关键帧源和深度对单独训练了一个MLA。对序列里的任意其他帧,x,y,r,g,b的值被输入到前后两个关键帧的MLAs里,然后将得到的深度(z1和z2)进行时间加权求和,再标准化。

f是待研究帧中的时间码,k1是第一个关键帧中的时间码,k2是第二个关键帧中的时间码。参数P用来控制MLA随时间衰变的影响速率。图3阐述了当加权函数P=2时MLA的一个例子。
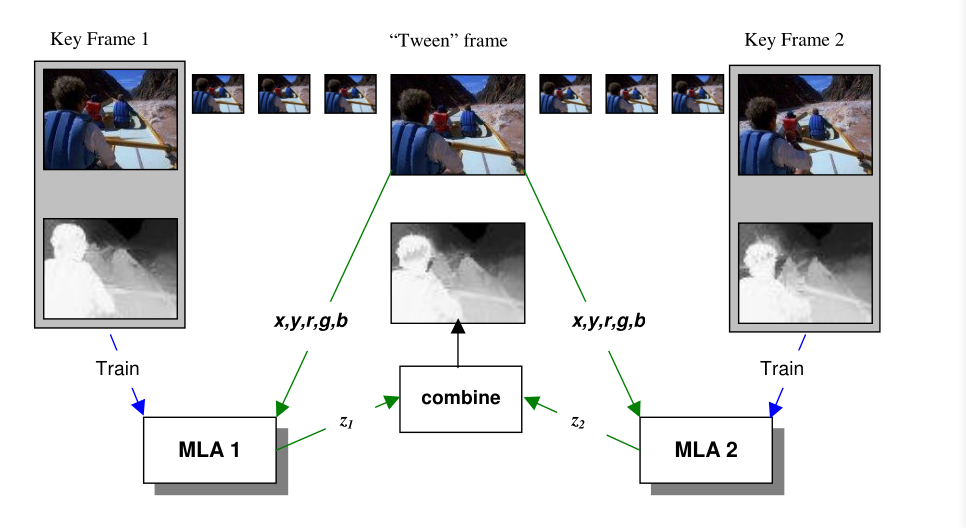
图2:深度渐变过程的图解。在每一个关键帧,用已知源图片的深度图训练一个MLA。对于任意给定的“渐变”帧,联合这些MLAs的结果来产生一个渐变的深度图。
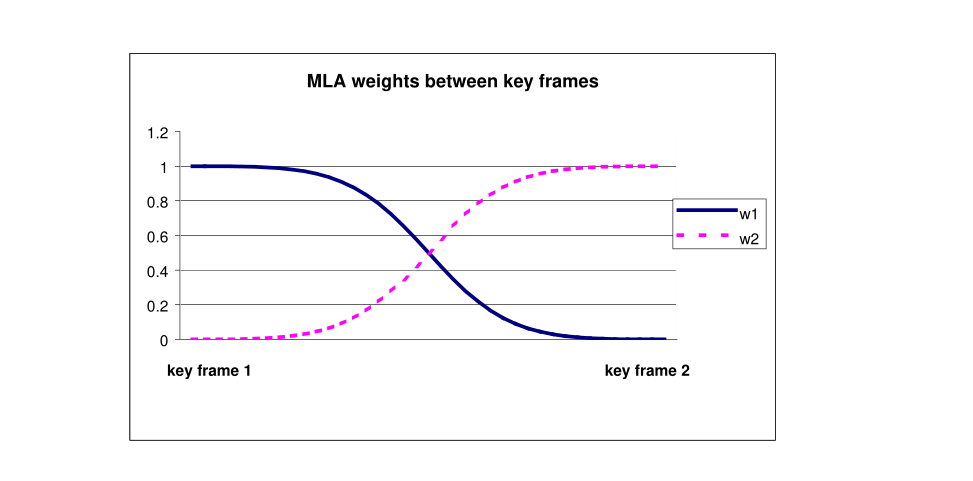
图3:绘图展示了MLA在时间上的相对权重——在这个例子中P=2。
4.结果
这个快速转换过程已在一个包含43帧的短序列上测试过。这个序列相当难,因为它包含快速运动和相似颜色区域的覆盖(比如,这个浆手的头和图片左边的山崖)。三个关键帧(帧数1,14,43)的深度图被绘制出来,剩余帧由深度渐变转换过来。

图4:源图片(左)和用深度渐变产生的第6帧的深度图(右)。
图4展示了用关键帧1,14在第6帧渐变产生的深度图。通常来说,离关键帧最远的帧包含最多的错误,因为在训练和分类中的源图片差异是最大的。图4的深度图准确地表示了场景的主要结构,尽管在浆手的头和背景之间有误分类的错误。同样的,图5展示了用关键帧14和43渐变产生的第32帧的深度图。

图5:源图片(左)和用深度渐变产生的第32帧的深度图(右)。
这个43帧的序列成功地进行了深度绘图,通过对3个关键帧提供了8000个训练样本。这代表着在这个序列中,只有0.05%总数的像素数目进行了深度绘制。
4.1 定量分析
为了评估用渐变方法产生深度图的准确度,在定量比较中,一个CGI序列被用作“参考标准”(ground truth)。用最商业化的CG包可以为CGI场景生成像素精确的深度图。我们用这些深度去测量深度渐变结果的均方根误差。
图6的曲线图展示了有4个关键帧的30帧的均方根分析。均方根误差用整个深度范围的百分比来展示。在关键帧,均方根误差降到0,并且正如所预料的一样,随着离最近的关键帧的距离上升,错误也会增多。在序列的末端,均方根误差更高,因为场景里非常快速运动的出现。
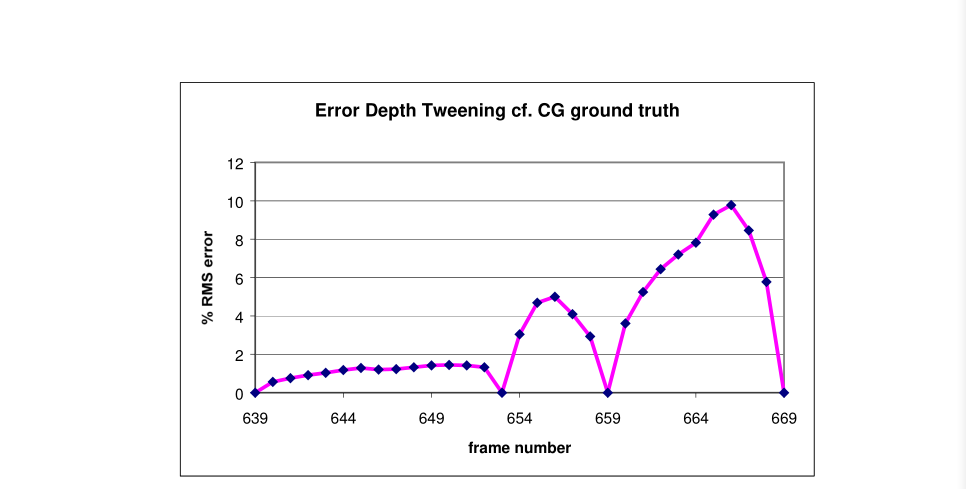
图6:有4关键帧的30帧序列的深度分辨率百分比的均方根误差
在整个深度范围,这个序列的平均均方根误差是7.5%。这些结果表明我们可以以超过90%的准确率重建深度图,在只给略微超出10%的训练数据。值得一提的是,尽管逐帧的均方根误差是一个很有用的评估这些技术的工具,但是其他因素,比如边缘准确度,平滑度以及时序一致性对于产生高效立体影像都是很重要的。
这个快速转换方法,正如所描述的,在近两年里成功部署在商业内容的转换服务上。
5.结论
MLAs在产生深度图的应用已经导致2D图片到3D转换时间和工作量的大幅减少。训练内容转换的MLAs简单,直觉,易于学习。通过快速转换方法产生的深度图已经有足够高的质量进行在自由立体显示器上的商业化应用。
引用
略。
PS:下面是英文原文下载链接:https://download.csdn.net/download/qq_33445835/10387427





