本文主要是介绍NLTK中文分句 自定义词典 Mr. 不分词,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
因为我这里已经下载过NLTK了,所以就不提供安装教程了,搜一搜都能找到。
这里就直接演示对英文句子切分:
from nltk.tokenize.punkt import PunktSentenceTokenizer, PunktParametersdef cut_sentences_en(content):punkt_param = PunktParameters()abbreviation = ['i.e.', 'dr', 'vs', 'mr', 'mrs', 'prof', 'inc'] # 自定义的词典punkt_param.abbrev_types = set(abbreviation)tokenizer = PunktSentenceTokenizer(punkt_param)sentences = tokenizer.tokenize(content)return sentences测试:
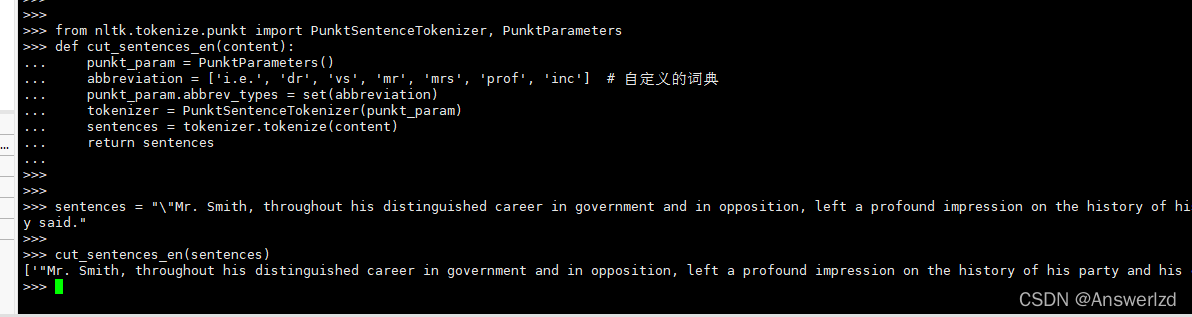
可以发现Mr. Smith并没有被分开。
这篇关于NLTK中文分句 自定义词典 Mr. 不分词的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





