分句专题

python异常之try/finally分句
1 python异常之try/finally分句 不管try语句代码块是否发生异常,finally分句代码块都会执行。 finally分句用于定义任何情况下都必须执行的清理操作,将会在最后执行。 finally分句用于任何需要保证资源释放的场景。 比如,文件操作后的关闭文件,连接数据库后的断开数据库。 1.1 基本用法 try复合语句必须有一个except分句或finally分句,并且
python异常之try/else分句
1 python异常之try/else分句 如果try语句代码块未发生异常,则执行else语句代码块,else需要放在except分句后面。 1.1 基本用法 用法 try:# try语句代码块# 执行时可能发生异常的代码块except ExceptionType:# except语句代码块# 当发生指定类型的异常时执行的代码块else:# else语句代码块# 如果没有发生异常,则

python异常之try语句分句
1 python异常之try语句分句 (1)分句数量 try复合语句,至少包含except、else、finally分句中的一种,否则报语法错误: SyntaxError: unexpected EOF while parsing 一个try复合语句内,except数目没有限制,else最多只能有1个,finally最多只能有1个。 (2)分句执行 如果try语句代码块触发了异常,则e
使用NLTK对英文文章分句,避免缩略词标点符号干扰
对于英文语料,我们想要获得句子时,可以通过正则或者NLTK工具切分。例如,NLTK: from nltk.tokenize import sent_tokenizedocument=''sentences=sent_tokenize(document) NLTK会根据“.?!”等符号切分。但是当句子中含有缩写词时,可能会产生错误的切分: sent_tokenize('fight among
【Python 千题 —— 基础篇】分句成词
题目描述 题目描述 在数据分析时,我们可能需要将一句话分割成一个个单词,从而分析句子所包含的内容。编写一个程序,输入一句话,然后以空格为分界符将句子分割成一个个单词,最后将这些单词以列表形式输出。 输入描述 输入一个句子。 输出描述 程序将输入句子分割成单词,并以列表形式输出。 示例 示例 ① I love you 输出: ['I', 'love', 'you']
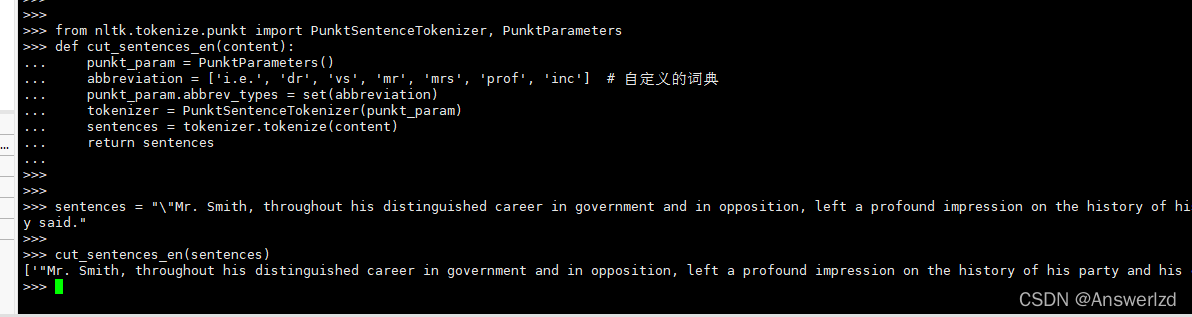
NLTK中文分句 自定义词典 Mr. 不分词
因为我这里已经下载过NLTK了,所以就不提供安装教程了,搜一搜都能找到。 这里就直接演示对英文句子切分: from nltk.tokenize.punkt import PunktSentenceTokenizer, PunktParametersdef cut_sentences_en(content):punkt_param = PunktParameters()abbreviation