本文主要是介绍知识点 | 今天好好学习MPP和MapReduce分别是个嘛?!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
来世界是数字化时代,而数据库是数据落地的强有力技术支持。
因数据库的初心是:高效稳定的提供数据服务能力;
数据库高效服务的体现点就是:高效的并行化处理能力。
说起并行化,
就不得不提MPP和MR(MapReduce)这两种并行处理架构和处理思维。
此前,必须要先聊一下数据库架构三种设计架构:
SHARE-EVERYTHING、SHARE-EVERYTING、SHANRE-NOTHING。
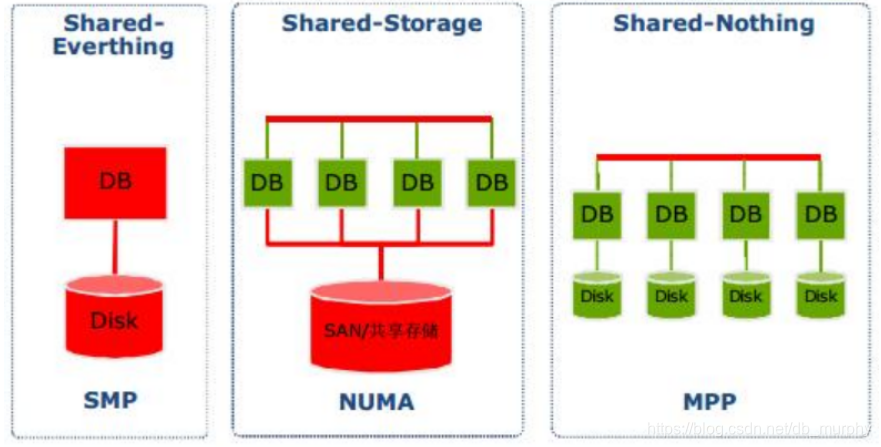
SHARE-EVERYTHING:
Shared Everthting:一般是针对单台服务器,完全透明共享CPU/MEMORY/IO,并行处理能力是最差的,典型代表SQLServer。
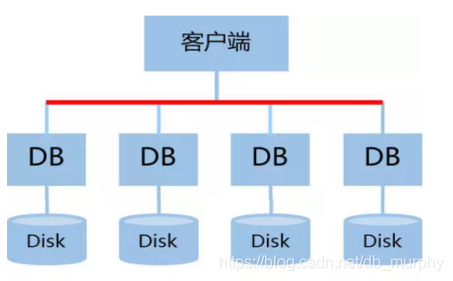
SHARED DISK:
各个处理单元使用自己的私有 CPU和Memory,共享磁盘系统,典型的代表 Oracle Rac。
该架构数据部分被计算节点共享,通过增加计算节点来提高SQL并行处理能力。但是当存储器接口达到饱和的时候,增加节点并不能获得更高的SQL性能。
SHARE-NOTHING
各个处理单元都有自己私有的CPU/内存/硬盘等,不存在共享资源,类似于MPP(大规模并行处理)模式,各处理单元之间通过协议通信,并行处理和扩展能力更好。
一、 什么是MPP?
想了解什么是MPP,首先了解什么是SMP?
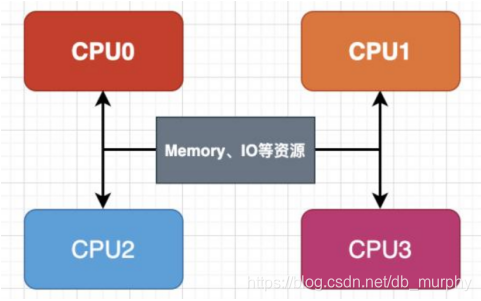
SMP模式(对称多处理,Symmetrical Multi-Processing),SMP是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存及总线。
-
SMP(Symmetric Multi-Processor)对称多处理器结构
-
是指服务器中多个 CPU 对称工作,无主次或从属关系。
-
各 CPU 共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 也被称为一致存储器访问结构 (UMA :Uniform Memory Access) 。
-
对 SMP 服务器进行扩展的方式包括增加内存、使用更快的 CPU 、增加 CPU 、扩充 I/O( 槽口数与总线数 ) 以及添加更多的外部设备 ( 磁盘存储 ) 。
SMP 服务器的主要特征是共享:
系统中所有资源 (CPU 、内存、 I/O 等 ) 都是共享的。
也正是这种特征,导致了 SMP 服务器的主要问题:扩展能力非常有限。
-
对于 SMP 服务器中的每一个共享的环节都可能造成扩展时瓶颈,最受限制则是内存。
-
由于每个 CPU 必须通过相同的内存总线访问相同的内存资源,因此随着 CPU 数量的增加,内存访问冲突将迅速增加,最终会造成 CPU 资源的浪费,使 CPU 性能的有效性大大降低。
-
实验证明:SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU 。
SMP 在扩展能力上的限制,从而不能有效地扩展构建大型服务系统体系。
怎么破?
- NUMA 非对称多处理期器架构
一种很自然想到的高性能扩展构建方式。
利用 NUMA(Non-Uniform Memory Access) 技术,可以把几十个 CPU( 甚至上百个 CPU) 组合在一个服务器内。
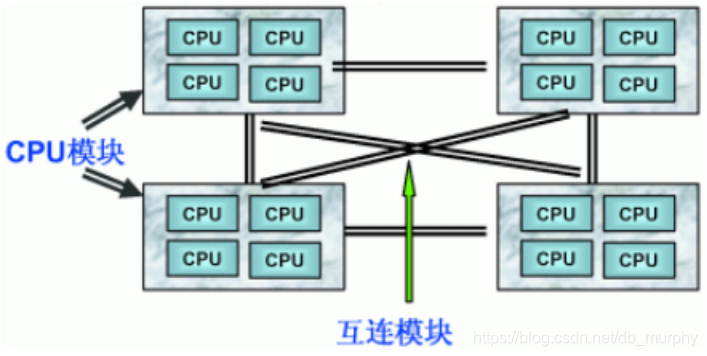
-
NUMA 服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU( 如 4 个 ) 组成,并且具有独立的本地内存、 I/O 槽口等。
-
由于其节点之间可以通过互联模块 ( 如称为 Crossbar Switch) 进行连接和信息交互,因此每个 CPU 可以访问整个系统的内存 ( 这是 NUMA 系统与 MPP 系统的重要差别 ) 。显然,访问本地内存的速度将远远高于访问远程内存 ( 系统内其它节点的内存 ) 的速度,这也是非一致存储访问 NUMA 的由来。
-
由于此设计特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同 CPU 模块之间的信息交互。
但 NUMA 技术同样有一定缺陷:
由于访问远程内存的延时远远超过本地内存,因此当 CPU 数量增加时,系统性能无法线性增加。
一个例子:
64 路CPU的 Superdome (NUMA 结构 ) 的相对性能值是 20 ;
而 8 路 N4000( 共享的 SMP 结构 ) 的相对性能值是 6.3。
- 再谈MPP(Massive Parallel Processing)
MPP 提供了另外一种进行系统扩展的方式,由多个 SMP 服务器通过一定的节点互联网络联通而成,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。
其基本特征是由多个 SMP 服务器 ( 每个 SMP 服务器称节点 ) 通过节点互联网络连接而成,每个节点只访问自己的本地资源 ( 内存、存储等 ) ,是一种完全无共享 (Share Nothing) 结构,因而扩展能力最好,理论上其扩展无限制。
在 MPP 系统中,每个 SMP 节点也可以运行自己的操作系统、数据库等。
但和 NUMA 不同的是,它不存在远程内存访问的问题。
换言之,每个节点内的 CPU 不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配 (Data Redistribution) 。
但,MPP 服务器需要一种复杂机制来调度和平衡各个节点的负载和并行处理过程。
目前一些基于 MPP 技术的服务器往往通过系统级软件 ( 如数据库 ) 来屏蔽这种复杂性。
举例:
-
NCR 的 Teradata 是基于 MPP 技术的一个关系数据库软件,基于此数据库来开发应用时,不管后台服务器由多少个节点组成,开发人员所面对的都是同一个数据库系统,而不需要考虑如何调度其中某几个节点的负载。
-
Teradata是MPP的商业数据库软件,比较有名还有开源版的greenplum。
一个问题/思考:
利用NGINX构建的应用服务器集群算不算MPP处理集群?
利用F5构建的应用服务器集群算不算MPP处理集群?
答案:当然算
MPP(大规模并行处理)服务器架构
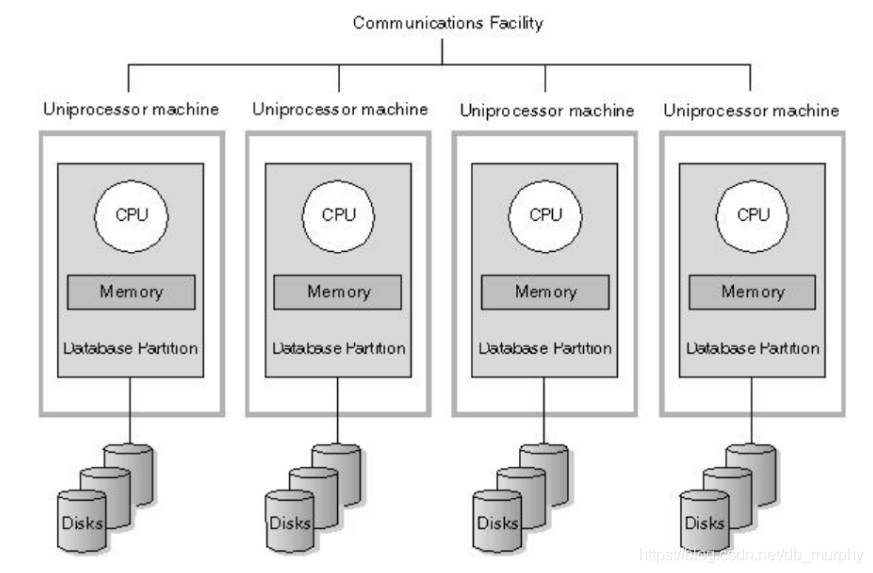
总结下MPP架构特征
-
Shared Nothing架构
-
分布式并行执行
-
数据分布式存储(本地化)
-
横向线性扩展
-
MPP服务器架构小结
由多个SMP服务器(每个SMP服务器称节点)通过节点间的互联网络连接而成,协同工作,完成相同的任务,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构;
从用户的角度来看是一个服务器系统。
因而扩展能力最好,理论上其扩展无限制。
- MPPDB
刚才说过,MPP 服务器需要一种复杂机制来调度和平衡各个节点的负载和并行处理过程。
MPPDB是Shared Nothing 架构的分布式并行结构化数据库集群,具备高性能、高可用、高扩展特性,可为超大规模数据管理提供高性价比的通用计算平台,广泛用于支撑各类数据仓库系统、BI 系统和决策支持系统。
举例:Greenplum 数据库采用高性能的系统架构可以将请求均匀分散到存储 PB 级别的数据仓库上,同时充分利用系统中所有的资源,并行处理请求。
举个栗子:
MPPDB采用完全并行的MPP + Shared Nothing 的分布式扁平架构,这种架构中的每一个节点(node)都是独立的、自给的、节点之间对等,且整个系统中不存在单点瓶颈,具有理论上无限的线性扩展能力。
- MPPDB特征
MPPDB具备以下技术特征:
-
低硬件成本:完全使用 x86 架构的 PC Server,不需要昂贵的 Unix 服务器和磁盘阵列;
-
集群架构与部署:完全并行的 MPP + Shared Nothing 的分布式架构,采用 Non-Master 部署,节点对等的扁平结构;
-
海量数据分布压缩存储:可处理 PB 级别以上的结构化数据,采用 hash分布、random 存储策略进行数据存储;同时采用先进的压缩算法,减少存储数据所需的空间,可以将所用空间减少 1~20 倍,并相应地提高 I/O 性能;
-
数据加载高效性:基于策略的数据加载模式,集群整体加载速度可达2TB/h;
-
高扩展、高可靠:支持集群节点的扩容和缩容,支持全量、增量的备份/恢复;
-
高可用、易维护:数据通过副本提供冗余保护,自动故障探测和管理,自动同步元数据和业务数据。提供图形化工具,以简化管理员对数据库的管理工作;
-
高并发:读写不互斥,支持数据的边加载边查询,单个节点并发能力 300+;
-
行列混合存储(HTAP特性):提供行列混合存储方案,从而提高了列存数据库特殊查询场景的查询响应耗时;
-
SQL标准化支持:支持SQL核心标准SQL92,支持 C API、ODBC、JDBC、ADO.NET 等接口规范。
7、 MPPDB架构的数据库有哪些?
国外DBMPP产品:
-
GREENPLUM(EMC)
-
Asterdata(Teradata)
-
Nettezza(IBM)
-
Vertica(HP)
国内DBMPP产品:
-
DM达梦
-
TiDB (pingCAP)
-
OpenGauss & GaussDB (高斯数据库)
-
SequoiaDB(巨杉数据)
-
OB & PolarDB (阿里)
-
TDSQL(腾讯)
-
GBase 8a MPP cluster(南大通用)
MPP先聊到这;
接下来接着聊MapReduce
二、MapReduce框架
Hadoop最早是Apache基金会开发的一个分布式的系统架构,它实现了分布式文件系统,简称HDFS,最大的特性是利用计算机集群来进行高速计算和存储,其核心是HDFS和MapReduce,HDFS是海量数据的存储、MapReduce是海量数据的计算。
Hadoop技术的开发初衷是雅虎、谷歌等互联网公司为了做海量的互联网数据处理而设计的。2005年将之开源,很多公司例如MapR、Cloudera以及星环等都是利用Hadoop技术做商业化的应用。
本质:MapReduce是一种用于数据处理的编程模型。
模型思维也很简单:
MapReduce会将任务分为小部分,将它们分配给不同系统来独立处理每个部分,在处理完所有零件并进行分析之后,将输出收集到一个位置,然后为给定问题输出数据集。
同一个应用功能的实现,Hadoop环境中,可运行用各种语言编写的MapReduce程序。
-
MapReduce是一编程框架,用于创建在大型商用硬件集群上处理大量数据的应用程序,
举个开发的例子:类似于JRE环境,可以在这个架构下开发应用程序。
-
MapReduce 程序本质上并行,本质是通过并行计算提升算力。
-
MapReduce的优势在于处理大型数据集。
为什么选择MapReduce?
大数据可以定义为传统系统无法处理的海量数据集或此类海量数据集。大数据本身已经成为一个整体主题,它包括对不同工具,技术和框架的研究,而不仅仅是对数据的研究。
传统系统倾向于使用集中式服务器来存储和检索数据。
标准数据库服务器无法容纳如此大量的数据。
而且,集中式系统在同时处理多个文件时会造成太多瓶颈。
Google提出了MapReduce来解决此类瓶颈问题。
MapReduce如何工作?
MapReduce是一种编程模型,用于通过集群上的并行分布式算法处理大型数据集。在大数据分析中,MapReduce扮演着至关重要的角色。
当它与HDFS结合使用时,可使用MapReduce处理大数据。
MapReduce使用的基本信息单位是键值对。
在通过MapReduce模型传递之前,所有结构化或非结构化数据都需要转换为键值对。
顾名思义,MapReduce模型具有两个不同的功能。映射功能和归约功能。
操作顺序始终为Map | Shuffle | Reduce。
Map | Shuffle | Reduce处理阶段讲解:Map阶段:Map阶段是MapReduce框架中的关键步骤,映射器将为非结构化数据提供结构。映射器将一次处理一个键值对。一个输入可以产生任意数量的输出。
基本上,Map函数将处理数据并生成几个小数据块。
还原阶段:shuffle阶段和reducer阶段一起称为还原阶段。Reducer将来自映射器的输出作为输入,并按照程序员的指定进行最终输出,此新输出将保存到HDFS。Reducer将从映射器中获取所有键-值对,并检查所有键与值的关联;将获取与单个键关联的所有值,并将提供任意数量的键值对的输出。
小结:通过了解Map和Reduce阶段,MapReduce是顺序计算。为保障Reducer正常工作,Mapper必须完成执行,否则Reducer阶段将不会运行。
由于Reducer可以访问所有值,因此可以说它将使用相同的键查找所有值并对它们执行计算。实际发生的是,由于reducer在不同的键上工作,才使它们同时工作并实现了并行性。
举个栗子:
假设有4个句子,要统计每种颜色出现的次数:
-
红色,绿色,蓝色,红色,蓝色
-
绿色,棕色,红色,黄色
-
黄色,蓝色,绿色,橙色
-
黄色,橙色,红色,蓝色
当这样的输入传递到映射器中时,映射器会将它们分为两个不同的子集。第一个是前两个句子的子集,第二个是其余两个句子的子集。
现在,Mapper具有:
-
子集1:红色,绿色,蓝色,红色,蓝色和绿色,棕色,红色,黄色
-
子集2:黄色,蓝色,绿色,橙色和黄色,橙色,红色,蓝色
映射器将为每个子集建立键值对。
此列中,键是颜色,值是它们出现的次数。
因此,子集1的键值对将为(Red,1),(Green,1),(Blue,1),依此类推。
对于子集2同样。
完成此操作后,会将键值对提供给reduce作为输入。因此,reducer将为我们提供输入子集中所有颜色的最终计数,然后将两个输出合并。reducer输出为(红色,4),(绿色,3),(蓝色,4),(棕色,1),(黄色,3),(橙色,2)。
小结:
MapReduce的功能是一个顺序流程,它具有并行能力,并基于键值对分析获得输出。当涉及大数据时,能够通过强大的并行计算能力提升处理速度。
三、 MPP和MR的自我理解
-
MPP是一种服务器设计架构,是有效扩展构建大型系统的一种架构设计;
-
MR是hadoop中的一种处理海量数据的并行编程模型;
-
MPP、MPPDB与MR都是将运算分布到节点中独立运算后进行结果合并;
-
MPP对应的一般是具有share-nothing的计算节点;
-
MR对应的是map、shuffle、reducer的并发处理流程,并发数可以根据业务进行调整,重点在于业务的并发拆解和梳理;
-
MPP是将任务并行的分散到多个服务器和节点上,每个节点各自计算,然后汇总一个结果;Hadoop应用在海量数据进行非实时的计算,它支持结构化和非结构化的数据。
-
MPPDB是分布式数据库,对应的一般是具有share-nothing的计算节点和存储节点的结合;数据库的本质在于“并发处理”,带来的问题就是“数据一致性”,
MPPDB分布式数据库的本质就是在保证“数据一致性”下的“高并发”;单实例有lock和latch的概念,集群架构有分布式锁DLM(cache fusion);分布式数据库中有pasox和raft协议保证数据一致性。
- MPP更加强调的实时计算,它其实是中型规模的数据运算,主要支持结构化数据,尤其是像银行、证券、保险、基金等金融机构,强调数据计算实时性,普遍都会用Vertica和Greenplum。
三、 MPP和MR的对比
-
MPP是将任务并行的分散到多个服务器和节点上,每个节点各自计算,然后汇总一个结果;
-
Hadoop应用在海量数据非实时计算,支持结构化、半结构化、非结构化数据;
-
MPP更加强调的实时计算,它其实是中型规模的数据运算,主要支持结构化数据,尤其是像银行、证券、保险、基金等金融机构,强调数据计算实时性,普遍都会用Vertica和Greenplum。
MPPDB、Hadoop与传统数据库技术对比与适用场景
MPPDB与Hadoop都是将运算分布到节点中独立运算后进行结果合并(分布式计算),但由于依据的理论和采用的技术路线不同而有各自的优缺点和适用范围。两种技术以及传统数据库技术的对比如下:
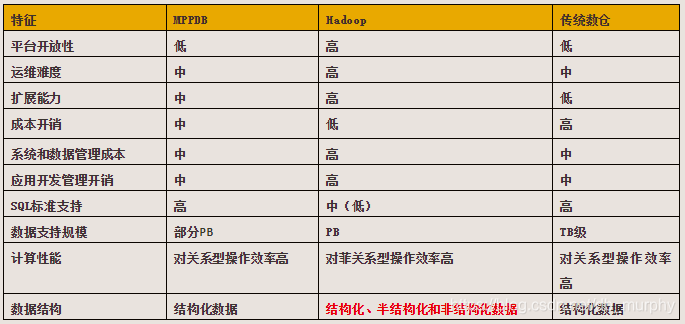
综合而言,Hadoop和MPP两种技术的特定和适用场景为:
-
Hadoop在处理非结构化和半结构化数据上具备优势,尤其适合海量数据批处理等应用要求。
-
MPP适合替代现有关系数据机构下的大数据处理,具有较高的效率。
-
MPP适合多维度数据自助分析、数据集市等;
-
Hadoop适合海量数据存储查询、批量数据ETL、非机构化数据分析(日志分析、文本分析)等。
由上对比,可预见未来大数据存储与处理趋势:MPPDB+Hadoop混搭使用,也就是目前NewSQL的HTAP特性(Hybrid Transactional / Analytical Processing)
HTAP场景需求:
-
用MPP处理PB级别的、高质量的结构化数据,同时为应用提供丰富的SQL和事物支持能力;
-
用Hadoop实现半结构化、非结构化数据处理。这样可以同时满足结构化、半结构化和非结构化数据的高效处理需求。
文章至此。
欢迎关注个人微信公众号图片
这篇关于知识点 | 今天好好学习MPP和MapReduce分别是个嘛?!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!