本文主要是介绍【模型详解】AutoEncoder详解(七)——栈式自编码:Stacked AutoEncoder,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 更新时间:2018-12-05
前言
之前介绍了AutoEncoder及其几种拓展结构,如DAE,CAE等,本篇博客介绍栈式自编码器。
模型介绍
普通的AE模型通过多层编码解码过程,得到输出,最小化输入输出的差异从而使模型学到有用的特征。但是这种AE结构又一个弊端:虽然经过了多次的特征提取,但对于目标函数的计算只有一次,那么,如果通过“栈化”AE结构进行逐层的贪婪训练得到的性能会不会比现有的要好呢?
实际上,Stacked AutoEncoder就是多个AE的“栈化”结果,其计算流程如下:
下图展示的是一个基础的AE结构,由 x i x_i xi到 h i ( 1 ) h_i^{(1)} hi(1)的过程为编码过程,由 h i ( 1 ) h_i^{(1)} hi(1)到 x ^ i \hat{x}_i x^i的过程为解码过程,通常情况下,最小化损失函数: (1) L = ∑ i = 1 n ( x ^ i − x i ) 2 L=\sum_{i=1}^n(\hat{x}_i - x_i)^2 \tag{1} L=i=1∑n(x^i−xi)2(1)
就可以是模型学习到有用的特征,当然,这个损失函数不唯一。
“栈化”过程指的是将多个下图的训练过程融合到一起,使模型能够学得到更有效的信息。
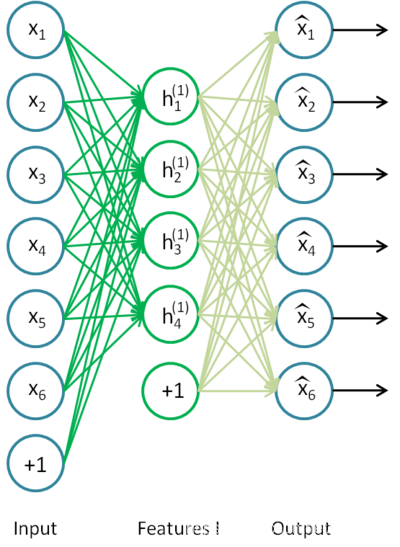
“栈化”过程的基本实现思想如下:训练好上图的AE结构后,舍去解码过程,此时我们可以理解为code(4维)具有一定的降维、提取特征的能力。将此时的code作为输入,输入到新的AE结构中进行训练,如下图所示:
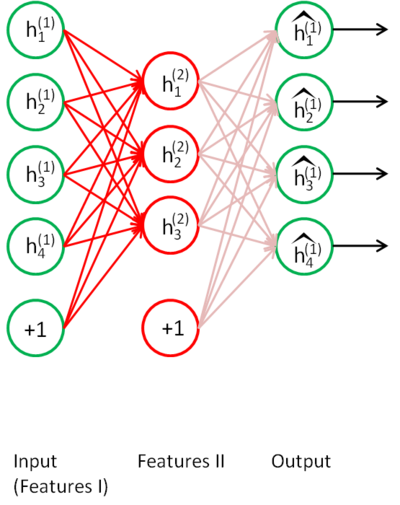
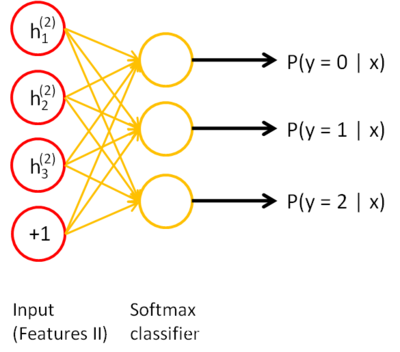
按照与上面同样的思想来训练这个AE,这样可以在上面的code基础上再一次进行降维,如此重复,使每次的“栈化”过程都能够学习到近似最优,最后得到code,可以认为,这个code更能够提取出有效的特征,因为它是多种效果的“叠加”,相应的,如果是进行分类操作,直接将code接入到分类器中,就可以得到分类结果,下图所示的是将code接入到softmax中:
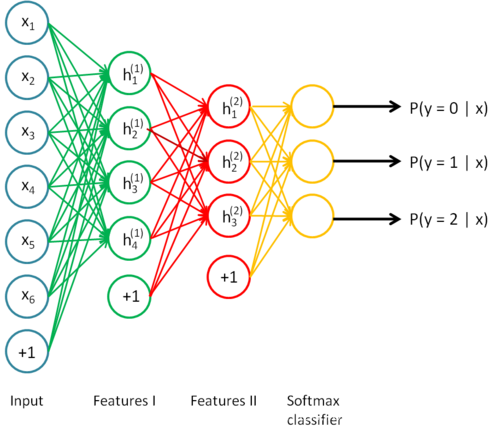
上述栈式自编码器的整体训练过程可以这样表示,途中省略了每次训练的解码过程:
这篇关于【模型详解】AutoEncoder详解(七)——栈式自编码:Stacked AutoEncoder的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





