本文主要是介绍selenium+IE爬取行政处罚信息公示表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬取某官网的行政处罚信息公示表,先从官网的某省市分站进行数据抓取,每个网页包括10条数据,共31页310份文书,批量下载到行政处罚文书文档,为后期使用python代码合并和数据筛选提供基础的数据信息。
目标网页,每页10条信息:
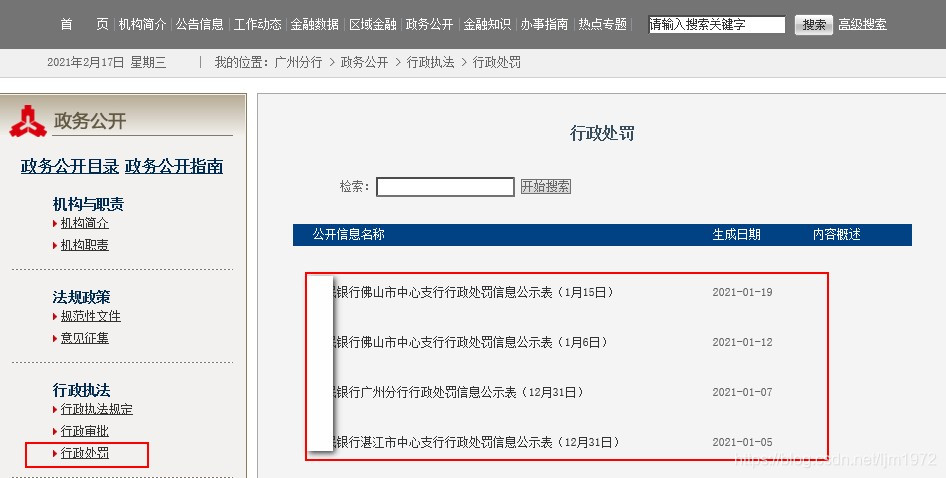
详情网页,每页只有一条信息(信息公示表),点击该点信息可以下载保存。
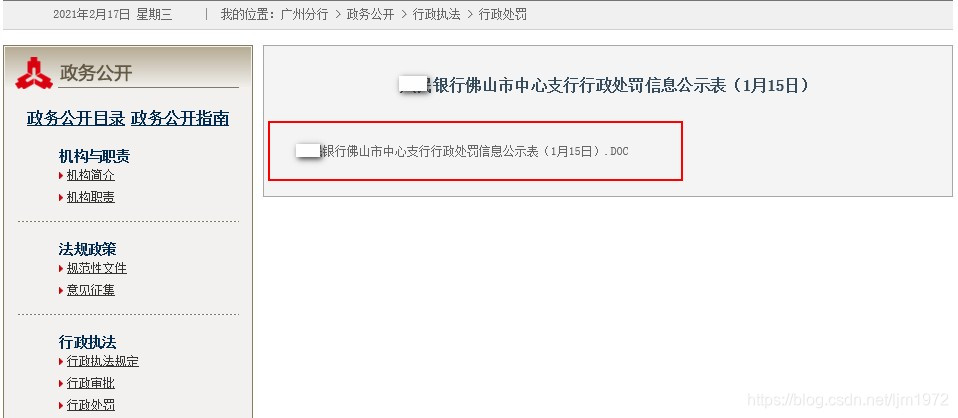
首先分析首页链接地址和第二页,第三页及下一页的链接地址,发现首页链接地址差异较大,从第二页开始,地址index后面多了页数编号,index前面多了20713/,找出了规律就好办了。
pageurl0='http://guangzhou.pbc.gov.cn/guangzhou/129142/129159/129166/index.html'#首页的链接
pageurl='http://guangzhou.pbc.gov.cn/guangzhou/129142/129159/129166/20713/index'+str(num)+'.html'#第二页及后面各页的链接
网站上右键点击可以查看到详情页的链接地址和原码,但是F12调用开发人员工具,找不到详情页的链接和内容。返回的response是空的,只有网站的框架结构代码。
绕道,使用selenium+IE,返回的browser.page_source出现了详情页的链接地址。
决定用selenium构造完整的下载链接地址。
使用IE浏览器模拟点击。结果发现,Firefox,Chrome浏览器已成爬取网页的主流。我还是坚持用IE浏览器,因为公司内部使用的就是IE,结果就是,IE浏览器不仅速度慢,还出现了一些意想不到的难题。许多人使用selenium过程中都绕开了IE浏览器,也是无奈中的办法。
先上代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
#from selenium.webdriver.support.ui import webDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
from lxml import etree
import time,re
import os
import requests
import random
import urllib.request
from urllib.request import urlopen
import win32api
import win32condef doctext(url_next,header):wb=requests.get(url_next,headers=header)wb.encoding='utf-8'print(wb)browser.get(url_next)#根据第一页生成的链接地址,获取第二页信息time.sleep(2)text = re.findall(r'td align="left" class="hei14jj"><p>(.*?)</a></p></td>',browser.page_source)#从第二页信息中提取每一条处罚书的链接和名称 #print(text)url_next2 = re.findall(r'a href=\"(.*?)\">',text[0])#提取每一条处罚书的链接 url_down = 'http://guangzhou.pbc.gov.cn'+url_next2[0]#加上网站的链接头,构成完整的处罚书下载链接 #打印抓取到的行政处罚信息公示表的名称 url_text = re.findall(r'DOC">(.*?)\.DOC',text[0])#行政处罚信息公示表的格式为DOC的文档名称,如果不是DOC,返回一个空的列表fileType = '.DOC' #文档名称的扩展名if url_text == []:#如果不是DOC,接着判断是不是xlsurl_text = re.findall(r'xls">(.*?)\.xls',text[0])#行政处罚信息公示表的格式为.xls的文档名称fileType = '.xls'if url_text == []:#如果不是xls,接着判断是不是eturl_text = re.findall(r'et">(.*?)\.et',text[0])#行政处罚信息公示表的格式为.et的文档名称fileType = '.et'if url_text == []:url_text = re.findall(r'doc">(.*?)\.doc',text[0])#行政处罚信息公示表的格式为doc的文档名称fileType = '.doc'if url_text == []:url_text = re.findall(r'ET">(.*?)\.ET',text[0])#行政处罚信息公示表的格式为.ET的文档名称fileType = '.ET'if url_text == []:url_text = re.findall(r'docx">(.*?)\.docx',text[0])#行政处罚信息公示表的格式为docx的文档名称fileType = '.docx'if url_text == []:url_text.append(url_down[-23:])fileType = url_down[-4:]#print(url_text)print('下载网址:%s' % (url_down)) if fileType == '.xls' or fileType == '.xlsx' or fileType == '.et' or fileType == '.ET':browser.get(url_down)time.sleep(3)#alt+s快捷键win32api.keybd_event(0x12, 0, 0, 0) #按下altwin32api.keybd_event(83, 0, 0, 0) #按下swin32api.keybd_event(83, 0, win32con.KEYEVENTF_KEYUP, 0) #松开swin32api.keybd_event(0x12, 0, win32con.KEYEVENTF_KEYUP, 0) #松开alttime.sleep(3) print('已下载并保存:%s' % (url_text[0]))else:print('等待下载:%s%s' % (url_text[0],fileType))def Excel_down(pageurl):print(pageurl)#第n页,包括10条数据browser.get(pageurl)time.sleep(2)#webDriverWait(drive,10).until(EC.presence_of_element_located((By.ID,''))) titles = re.findall(r'font class="hei12">(.*?)</a></font>',browser.page_source)urls = []#第n页,10条数据所对应的链接网页for title in titles:url = re.findall(r'href=\"(.*?)\" target="_blank">',title)urls.append('http://guangzhou.pbc.gov.cn'+url[0])user_agent_list = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36","Mozilla/5.0 (Windows NT 10.0; WOW64; rv:60.0) Gecko/20100101 Firefox/61.0","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)","Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15",]header={'User-Agent':'Mozilla/5.0'}header['User-Agent'] = random.choice(user_agent_list)for i in range(len(urls)):#第n页,10条数据所对应的链接网页,逐条点击并进入对应的网页#print(urls[i])url_next = urls[i]doctext(url_next,header) #第一页的数据if __name__ == '__main__':start = time.time()IEdriver = "C:\Program Files\internet explorer\IEDriverServer.exe" browser = webdriver.Ie(IEdriver)url_all = []pageurl0='http://guangzhou.pbc.gov.cn/guangzhou/129142/129159/129166/index.html'url_all.append(pageurl0)num = 2 #从第2页开始 while num <= 5: #从第2页开始,总共要爬取多少页,置为N pageurl='http://guangzhou.pbc.gov.cn/guangzhou/129142/129159/129166/20713/index'+str(num)+'.html'#print(pageurl)url_all.append(pageurl) num +=1for i in range(len(url_all)):#print(url_all[i])url_next1 = url_all[i]Excel_down(url_next1)end = time.time()print ('运行时间:', end-start)
爬取到的文档保存在指定的路径

先试试爬取前面5页的数据,碰到几个难题。
第一个就是下载弹窗,selenium无法识别到弹窗,如果是Firefox,Chrome浏览器下载保存均可预设1次后,不再每次提示,自动化进程不会被打断。偏偏这个IE下载弹窗是window系统级别的窗口,在自动触发下载前,用win32API还获取不到该下载提示窗的句柄,触发后由于停在提示上,不进行手点鼠标或手工按ALT+S,程序就执行不下去。查出了许多资料,可调用AutoIT实现自动下载并保存文件,于是SciTE Script Editor写了一个脚本:
Sleep(1000)
ControlFocus("Internet Explorer","","DirectUIHWND1")
WinWait("[CLASS:#32770]","",10)
ControlClick("Internet Explorer","","Button2")
Sleep(1000)
保存为au3格式,编译成可执行文件autobaocun.exe,编译后在Python代码中调用。
import subprocessfile_path=r'C:\Users\CF-SZ5\Downloads\处罚通知书'
cmd='D:/CF-sz5/pachu/autobaocun.exe'+' '+file_path
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True,stderr=subprocess.PIPE)
out, err = p.communicate()
if p.returncode == 0:print('ok')
单独运行可以自动完成下载,但是放到Python整个爬取文件的代码中,运行到弹窗就停了。
放弃AutoIT,使用 win32api和 win32con模拟键盘自动点击,完成自动下载保存。
time.sleep(3)#alt+s快捷键win32api.keybd_event(0x12, 0, 0, 0) #按下altwin32api.keybd_event(83, 0, 0, 0) #按下swin32api.keybd_event(83, 0, win32con.KEYEVENTF_KEYUP, 0) #松开swin32api.keybd_event(0x12, 0, win32con.KEYEVENTF_KEYUP, 0) #松开alttime.sleep(3) print('已下载并保存:%s' % (url_text[0]))
又发现一个难题,当下载文档是Words时,弹窗位置和名称出现了变化 ,就无法自动点击完成下载保存。最后,只下载到扩展名是xls和et的文档。为确保爬虫程序顺利运行,增加了下载文档的扩展名判断,并且只对扩展名是xls和et的文档进行下载。
#打印抓取到的行政处罚信息公示表的名称 url_text = re.findall(r'DOC">(.*?)\.DOC',text[0])#行政处罚信息公示表的格式为DOC的文档名称,如果不是DOC,返回一个空的列表fileType = '.DOC' #文档名称的扩展名if url_text == []:#如果不是DOC,接着判断是不是xlsurl_text = re.findall(r'xls">(.*?)\.xls',text[0])#行政处罚信息公示表的格式为.xls的文档名称fileType = '.xls'if url_text == []:#如果不是xls,接着判断是不是eturl_text = re.findall(r'et">(.*?)\.et',text[0])#行政处罚信息公示表的格式为.et的文档名称fileType = '.et'if url_text == []:url_text = re.findall(r'doc">(.*?)\.doc',text[0])#行政处罚信息公示表的格式为doc的文档名称fileType = '.doc'if url_text == []:url_text = re.findall(r'ET">(.*?)\.ET',text[0])#行政处罚信息公示表的格式为.ET的文档名称fileType = '.ET'if url_text == []:url_text = re.findall(r'docx">(.*?)\.docx',text[0])#行政处罚信息公示表的格式为docx的文档名称fileType = '.docx'if url_text == []:url_text.append(url_down[-23:])fileType = url_down[-4:]#print(url_text)print('下载网址:%s' % (url_down)) if fileType == '.xls' or fileType == '.xlsx' or fileType == '.et' or fileType == '.ET':browser.get(url_down)time.sleep(3)#alt+s快捷键win32api.keybd_event(0x12, 0, 0, 0) #按下altwin32api.keybd_event(83, 0, 0, 0) #按下swin32api.keybd_event(83, 0, win32con.KEYEVENTF_KEYUP, 0) #松开swin32api.keybd_event(0x12, 0, win32con.KEYEVENTF_KEYUP, 0) #松开alttime.sleep(3) print('已下载并保存:%s' % (url_text[0]))else:print('等待下载:%s%s' % (url_text[0],fileType))
最后,成功爬取到4页,xls和et的文档。总结一下有待完善的地方:
1。IE下载提示要打开或保存时是模拟键盘点击,所以下载过程一使用键盘就会中断运行。
2。IE下载速度较慢,要根据网速设置爬取过程中的停留时间,否则下载的文件可能不全。
3。少部分Word格式的文档,有待重新写代码才能下载,或者只能放弃IE浏览器,改用Firefox,Chrome浏览器。
这篇关于selenium+IE爬取行政处罚信息公示表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






