本文主要是介绍OpenCV3学习(10.3)基于高斯混合模型的背景建模BackgroundSubtractorMOG/MOG2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
OpenCV用于背景建模的类主要有:BackgroundSubtractor、BackgroundSubtractorMOG、BackgroundSubtractorMOG2、BackgroundSubtractorKNN。BackgroundSubtractor在OpenCV2和3版本有较大区别,OpenCV3取消了OpenCV2.4中的高斯背景建模(BackgroundSubtractorMOG),保留了高斯背景建模2(BackgroundSubtractorMOG2),引入了KNN背景建模(BackgroundSubtractorKNN)。
背景建模的思想由来
在监控系统中,拍摄背景通常是变化较少的固定场景。通常我们假定没有入侵物体的静态场景可以用一个统计模型描述。GMM就是用高斯模型,而且是多个高斯模型的加权和混合在一起来模拟背景的特性。这样一旦已知这个背景模型,入侵物体就能通过标出场景图像中不符合这一背景模型的部分来检测到。这一过程被称为背景减除Backgroundsubtraction。
一旦背景以高斯混合模型来模拟了,现在确定这个模型变成了解出高斯混合模型公式中的一系列参数,在解参数时通常用的是EM算法,EM算法分两步:E-step和M-step。
混合高斯模型的必要性:
(1)如果场景中光照条件稳定且背景固定,那么某一点处的像素值会比较稳定,考虑到噪声的存在,使用一个高斯分布即可比较好的描述该点像素值
(2)实际场景中,光照条件往往不稳定,且存在一些局部运动的背景物体(譬如摇摆的树枝),此时使用多个高斯分布表达比较合适
(3)实际场景中背景区域也可能实时改变,所以需要实时更新混合高斯分布参数的策略
混合高斯分布(GMM)是背景建模中的经典算法。opencv将基本版本的GMM封装为BackgroundSubtractorMOG,改进版GMM封装为BackgroundSubtractorMOG2算法类。Mog2用的是自适应的高斯混合模型(Adaptive GMM,Gaussian Mixture Model),在几种背景提取算法MOG,MOG2,GMG的测试结果中,MOG2确实在前景连续性及运算时间上都脱颖而出。
改进后的GMM算法,即BackgroundSubtractorMOG2算法主要有两点改进点:(1)增加阴影检测功能(2)算法效率有较大提升(高斯分量的个数不固定)。前者的意义在于如果不使用一些方法检测得到阴影,那么它有可能被识别为前景物体,导致前景物体得到了错误的形状,从而对后续处理(譬如跟踪)产生不好的影响。
背景建模也称为背景估计,其主要目的是根据当前的背景估计,把对序列图像的运动目标检测问题转化为一个二分类问题,将所有像素划分为背景和运动前景两类,进而对分类结果进行后处理,得到最终检测结果。比较简单的获取背景图像的方法是当场景中无任何运动目标出现时捕获背景图像,但这种方法不能实现自适应,通常仅适应于对场景的短时间监控,不能满足智能监控系统对背景建模的要求。
背景减除法的关键是背景模型,它是背景减除法分割运动前景的基础。背景模型主要有单模态和多模态两种,前者在每个背景像素上的颜色分布比较集中,可以用单分布概率模型来描述,后者的分布则比较分散,需要多分布概率模型来共同描述。最常用的描述场景背景像素颜色分布的概率密度函数是高斯分布。
单高斯背景建模
高斯背景模型是一种运动目标检测过程中提取并更新背景和前景的一种方法。对一个背景图像,特定像素亮度的分布满足高斯分布,即对背景图像B,每一个点(x,y)的亮度满足B(x,y)~N(u,d):
即每一个点(x,y)都包含了两个属性,均值u和方差d:计算一段时间内的视频序列图像中每一个点的均值u和方差d,作为背景模型。对于一幅包含前景的任意图像G,对于图像上的每一个点(x,y)计算,若:
(T为一个常数阈值),则认为该点是背景点,否则为前景点。接下来就背景的更新,每一帧图像都参与背景的更新:
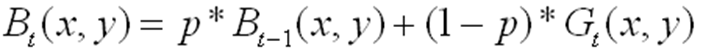
其中,p为一个常数,用来反映背景更新率,p越大,背景更新的越慢。一般情况下,背景更新后d的变化很小,所以在更新背景以后一般不再更新d。
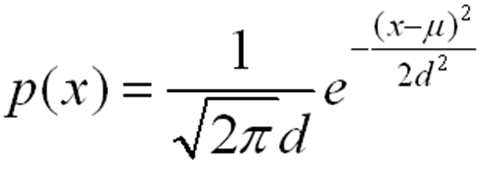
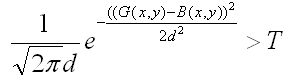



混合高斯模型的原理
图像中每个像素点的值(或特征)短时间内都是围绕与某一中心值一定距离内分布,通常,中心值可以用均值来代替,距离呢可以用方差来代替。这种分布呢是有规律的,根据统计定律,如果数据点足够多的话,是可以说这些点呈正态分布,也称为高斯分布(取名高斯,大概是因为很多地方都用这个名字吧)。根据这个特点,如果像素点的值偏离中心值较远,那么,这个像素值属于前景,如果像素点的值偏离中心值很近(在一定方差范围内),那么可以说这个点属于背景。理论上,如果不存在任何干扰的话,是可以准确区分前景和背景的。但是,现实往往不尽如人意,如果画面中光线变化的话,这个高斯分布的中心位置是会改变的。
混合高斯模型指这个像素点值存在多个中心位置,如来回摆动的树叶,波光粼粼的水面,闪烁的显示器,图像中特征边缘位置的抖动等,这些都会引起某个像素点会在多个中心位置聚集大量的点,每个位置便会产生一个高斯分布,四个以上的高斯分布其实并不常见,这便是混合高斯模型的由来。混合高斯背景建模主要用来解决背景像素点具有多峰特性的场合,如在智能交通场景中,解决视频画面抖动带来的干扰。
针对光线变化的问题,混合高斯模型通过比较当前像素点的值与高斯分布中心位置,选择一定的加权系数对当前高斯分布的中心位置进行更新,以便于适应缓慢的光线变化。
此外,混合高斯模型尤其适合于检测缓慢移动的物体,因为背景已是一个高斯分布,如果车停下来,等到聚集一定的前景数据便会形成一个新的高斯分布,停下来的车也会便是背景。但是如果车缓慢行驶的话,是很难在短时间内形成一个新的高斯分布,也就是应用混合高斯分布很容易检测缓慢行驶的车辆。
混合高斯背景建模的优点
每个像素的运动变化特性是不一样的,这才是混合高斯模型具有优势的主要原因。普通的二值化目标分割,整个画面采用同一阈值,无论这个阈值是固定的,还是自适应的,都存在本质性的缺陷,属于有缺陷的分割,这种算法带有不稳定性,无论怎么调整分割参数,也解决不了根本性的问题。因为,画面中每个部分,其实分割阈值是不一样的。一定得建立统计学的方法,进行局部分割,而混合高斯模型正是采用局部分割的一种算法。
混合高斯背景建模方法评价
从理论上来说,混合高斯背景建模真是一种较为完美的背景分割方法。但是由于像素值在光线干扰下在中心位置停留时间较短,围绕这一中心位置波动的数据准确地来说并不属于高斯分布,因此也就无法准确地确定这些数据的中心值及方差,造成实际分割的效果并不完美。

第一步:即初始化K个高斯分布的参数。
第二部:更新高斯分布权值和参数。



上图中的“排序及删减”有些不确切,实际过程中不会“删减”N之后索引的高斯分布,而是作为前景点判断的一种条件。计算过程中前景点的判断标准包括与当前高斯模型集合都不匹配的点,和虽然匹配上了但是匹配的模型索引超出了由T计算得到的N;后者一般是场景中新出现没有多久的像素点。
原理截图来自:https://wenku.baidu.com/view/273e56855f0e7cd1842536c4.html?from=search
归纳一下其中的流程,首先初始化预先定义的几个高斯模型,对高斯模型中的参数进行初始化,并求出之后将要用到的参数。其次,对于每一帧中的每一个像素进行处理,看其是否匹配某个模型,若匹配,则将其归入该模型中,并根据新的像素值对该模型参数进行更新,若不匹配,则以该像素建立一个高斯模型,初始化参数。最后选择前面几个最有可能的模型作为背景模型,为背景目标提取做铺垫。
opencv3.4.3版本:

MOG(KB方法)
这是一个以混合高斯模型为基础的前景/背景分割算法。它是 P.KadewTraKuPong和 R.Bowden 在 2001 年提出的。它使用 K(K=3 或 5)个高斯分布混合对背景像素进行建模。使用这些颜色(在整个视频中)存在时间的长短作为混合的权重。背景的颜色一般持续的时间最长,而且更加静止。一个像素怎么会有分布呢?在 x,y 平面上一个像素就是一个像素没有分布,但是我们现在讲的背景建模是基于时间序列的,因此每一个像素点所在的位置在整个时间序列中就会有很多值,从而构成一个分布。
在编写代码时,我们需要使用函数: createBackgroundSubtractorMOG()创建一个背景对象。这个函数有些可选参数,比如要进行建模场景的时间长度,高斯混合成分的数量,阈值等。将他们全部设置为默认值。然后在整个视频中我们是需要使用 backgroundsubtractor.apply() 就可以得到前景的掩模了。
MOG原型在(opencv3.4.3版本)opencv_contrib库中的bgsegm模块中:
Ptr<BackgroundSubtractorMOG> cv::bgsegm::createBackgroundSubtractorMOG ( int history = 200,
int nmixtures = 5,
double backgroundRatio = 0.7,
double noiseSigma = 0
)注意BackgroundSubtractorMOG/MOG2函数在opencv3.0与opencv2.4中的不同实现方式 。
BackgroundSubtractorMOG bgSubtractor(20, 10, 0.5, false);//在opencv2版本
Ptr<BackgroundSubtractorMOG> bgsubtractor = createBackgroundSubtractorMOG();//在opencv3版本Ptr<BackgroundSubtractorMOG2> bgsubtractor = createBackgroundSubtractorMOG2();//在opencv3版本from:https://blog.csdn.net/mumu0627/article/details/52741220
在opencv2版本中,MOG算法实例 :
#include "opencv2/opencv.hpp"
int main()
{VideoCapture video("../video.avi");Mat frame, mask, thresholdImage, output;int frameNum = 1;if (!video.isOpened())cout << "fail to open!" << endl;//cout<<video.isOpened();long totalFrameNumber = video.get(CV_CAP_PROP_FRAME_COUNT);video>>frame;//cout<<frame.size;BackgroundSubtractorMOG bgSubtractor(20, 10, 0.5, false);//imshow("video", frame);//waitKey(10000);while (true){if (totalFrameNumber == frameNum)break;video >> frame;++frameNum;bgSubtractor(frame, mask, 0.001);//cout << frameNum << endl;imshow("mask",mask); waitKey(10); }return 0;
}
from:https://blog.csdn.net/mumu0627/article/details/52741220
MOG2(Zivkovic方法)
这个也是以高斯混合模型为基础的背景/前景分割算法。它是以 2004 年和 2006 年 Z.Zivkovic 的两篇文章为基础的。 上面说到MOG是用多个高斯模型的加权和来表示,假定是M个高斯分量,讨论M的取值是MOG2的作者研究的一个重点:MOG取固定个数的高斯分量, MOG2则根据不同输入场景自动选择分量的个数。这个算法的一个特点是它为每一个像素选择一个合适数目的高斯分布。(上一个方法中我们使用是 K 高斯分布)。这样就会对由于亮度等发生变化引起的场景变化产生更好的适应。在较简单的场景下,将只选出一个较重要的高斯分量,节省了后期更新背景时选属于哪一分量的时间,提高了速度。 和前面一样我们需要创建一个背景对象。但在这里我们我们可以选择是否检测阴影。如果detectShadows = T rue(默认值),它就会检测并将影子标记出来,但是这样做会降低处理速度。影子会被标记为灰色。
这样做的好处是有两个测试结果为证:一是用OpenCV中测试程序对同一简单场景测试视频跑不同算法得到的运行时间如下表,明显mog2快很多;
对象构建:
Ptr<backgroundsubtractormog2> cv::createBackgroundSubtractorMOG2 (
int history = 500,
double varThreshold = 16,
bool detectShadows = true
)对象创建方式与参数说明:
例如:
Ptr<BackgroundSubtractorMOG2> mog = createBackgroundSubtractorMOG2(100,25,false);history:用于训练背景的帧数,默认为500帧,如果不手动设置learningRate,history就被用于计算当前的learningRate,此时history越大,learningRate越小,背景更新越慢;varThreshold:方差阈值,用于判断当前像素是前景还是背景。一般默认16,如果光照变化明显,如阳光下的水面,建议设为25,36,具体去试一下也不是很麻烦,值越大,灵敏度越低;detectShadows:是否检测影子,设为true为检测,false为不检测,检测影子会增加程序时间复杂度,如无特殊要求,建议设为false;
运动检测apply函数:
virtual void cv::BackgroundSubtractor::apply (
InputArray image,
OutputArray fgmask,
double learningRate = -1
)eg:mog2->apply(src_Y, foreGround, 0.005);
- image 源图
- fmask 前景(二值图像)
- learningRate 学习速率,值为0-1,为0时背景不更新,为1时逐帧更新,默认为-1,即算法自动更新;
MOG2官方文档(有一些重要参数):https://docs.opencv.org/3.4.3/d7/d7b/classcv_1_1BackgroundSubtractorMOG2.html
eg:mog2->setVarThreshold(20);
部分重要参数介绍
nmixtures:高斯模型个数,默认5个,最多8个,一般设为5就好,个人测试:设为8个的时候检测效果提升有限,但程序耗时增加;
backgroundRatio:高斯背景模型权重和阈值,nmixtures个模型按权重排序后,只取模型权重累加值大于backgroundRatio的前几个作为背景模型。也就是说如果该值取得非常小,很可能只使用权重最大的高斯模型作为背景(因为仅一个模型权重就大于backgroundRatio了);
fVarInit:新建高斯模型的方差初始值,默认15;
fVarMax:背景更新过程中,用于限制高斯模型方差的最大值,默认20;
fVarMin:背景更新过程中,用于限制高斯模型方差的最小值,默认4;
varThresholdGen:方差阈值,用于是否存在匹配的模型,如果不存在则新建一个;
from:https://blog.csdn.net/m0_37901643/article/details/72841289
MOG2背景建模的opencv3官方例程如下:
#include "opencv2/imgproc.hpp"
#include "opencv2/videoio.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/video/background_segm.hpp"
#include <stdio.h>
#include <string>
using namespace std;
using namespace cv;
static void help()
{printf("\n""This program demonstrated a simple method of connected components clean up of background subtraction\n""When the program starts, it begins learning the background.\n""You can toggle background learning on and off by hitting the space bar.\n""Call\n""./segment_objects [video file, else it reads camera 0]\n\n");
}
static void refineSegments(const Mat& img, Mat& mask, Mat& dst)
{int niters = 3;vector<vector<Point> > contours;vector<Vec4i> hierarchy;Mat temp;dilate(mask, temp, Mat(), Point(-1,-1), niters);erode(temp, temp, Mat(), Point(-1,-1), niters*2);dilate(temp, temp, Mat(), Point(-1,-1), niters);findContours( temp, contours, hierarchy, RETR_CCOMP, CHAIN_APPROX_SIMPLE );dst = Mat::zeros(img.size(), CV_8UC3);if( contours.size() == 0 )return;// iterate through all the top-level contours,// draw each connected component with its own random colorint idx = 0, largestComp = 0;double maxArea = 0;for( ; idx >= 0; idx = hierarchy[idx][0] ){const vector<Point>& c = contours[idx];double area = fabs(contourArea(Mat(c)));if( area > maxArea ){maxArea = area;largestComp = idx;}}Scalar color( 0, 0, 255 );drawContours( dst, contours, largestComp, color, FILLED, LINE_8, hierarchy );
}
int main(int argc, char** argv)
{VideoCapture cap;bool update_bg_model = true;CommandLineParser parser(argc, argv, "{help h||}{@input||}");if (parser.has("help")){help();return 0;}string input = parser.get<std::string>("@input");if (input.empty())cap.open(0);elsecap.open(input);if( !cap.isOpened() ){printf("\nCan not open camera or video file\n");return -1;}Mat tmp_frame, bgmask, out_frame;cap >> tmp_frame;if(tmp_frame.empty()){printf("can not read data from the video source\n");return -1;}namedWindow("video", 1);namedWindow("segmented", 1);Ptr<BackgroundSubtractorMOG2> bgsubtractor=createBackgroundSubtractorMOG2();bgsubtractor->setVarThreshold(10);for(;;){cap >> tmp_frame;if( tmp_frame.empty() )break;bgsubtractor->apply(tmp_frame, bgmask, update_bg_model ? -1 : 0);refineSegments(tmp_frame, bgmask, out_frame);imshow("video", tmp_frame);imshow("segmented", out_frame);char keycode = (char)waitKey(30);if( keycode == 27 )break;if( keycode == ' ' ){update_bg_model = !update_bg_model;printf("Learn background is in state = %d\n",update_bg_model);}}return 0;
}MOG和MOG2对比:
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/opencv.hpp>#include "VideoProcessor.h"
#include "FeatureTracker.h"
#include "BGFSSegmentor.h"using namespace std;
using namespace cv;int main(int argc, char* argv[])
{VideoCapture capture("../768X576.avi");if(!capture.isOpened())return 0;Mat frame;Mat foreground, foreground2;BackgroundSubtractorMOG mog;BackgroundSubtractorMOG2 mog2;bool stop(false);namedWindow("Extracted Foreground");while(!stop){if(!capture.read(frame))break;cvtColor(frame, frame, CV_BGR2GRAY);long long t = getTickCount();mog(frame, foreground, 0.01);long long t1 = getTickCount();mog2(frame, foreground2, -1);long long t2 = getTickCount();cout<<"t1 = "<<(t1-t)/getTickFrequency()<<" t2 = "<<(t2-t1)/getTickFrequency()<<endl;imshow("Extracted Foreground", foreground);imshow("Extracted Foreground2", foreground2);imshow("video", frame);if(waitKey(10) >= 0)stop = true;}waitKey();return 0;}
背景提取效果如下图所示,左边为BackgroundSubtractorMOG2算法效果,右边为BackgroundSubtractorMOG效果。忽略左边图像中的一些噪点,两者的最大不同在于左边图像中存在灰色填充的一些区域,这正是BackgroundSubtractorMOG2算法的一个改进点-阴影检测,那些灰色区域就是算法计算得到的“阴影”区域。另外一处不同在于算法的运行时间,根据控制台输出结果,BackgroundSubtractorMOG2每帧检测大概0.03s,BackgroundSubtractorMOG每帧检测大概0.06s,BackgroundSubtractorMOG2算法在运行时间上有较大提升(不全是算法本身原因,实际上BackgroundSubtractorMOG2在执行时通过多线程并行执行)。

from:https://blog.csdn.net/lwx309025167/article/details/78554082(源码解读)
所以目前看来改进后的GMM算法,即BackgroundSubtractorMOG2算法主要有两点改进点:(1)增加阴影检测功能(2)算法效率有较大提升。后者意义不言而喻,前者的意义在于如果不使用一些方法检测得到阴影,那么它有可能被识别为前景物体,导致前景物体得到了错误的形状,从而对后续处理(譬如跟踪)产生不好的影响。
补充:BackgroundSubtractorGMG
此算法结合了静态背景图像估计和每个像素的贝叶斯分割。这是 2012年Andrew_B.Godbehere, Akihiro_Matsukawa 和 Ken_Goldberg 在文章中提出的。它使用前面很少的图像(默认为前 120 帧)进行背景建模。使用了概率前景估计算法(使用贝叶斯估计鉴定前景)。这是一种自适应的估计,新观察到的 对象比旧的对象具有更高的权重,从而对光照变化产生适应。一些形态学操作如开运算闭运算等被用来除去不需要的噪音。在前几帧图像中你会得到一个黑色窗口。 对结果进行形态学开运算对与去除噪声很有帮助。结果:
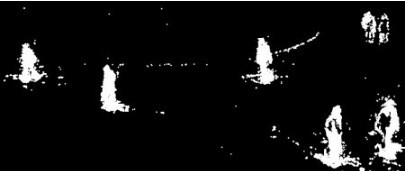
from:前景检测算法(五)--GMM,GMM2,GMG
这篇关于OpenCV3学习(10.3)基于高斯混合模型的背景建模BackgroundSubtractorMOG/MOG2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







