本文主要是介绍对布匹的疵点数据集进行分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对布匹的疵点数据集进行分析
1. 课题介绍
布匹疵点检验是纺织行业生产和质量管理的重要环节,目前的人工检验速度慢、劳动强度大,受主观因素影响,缺乏一致性。2016年我国布匹产量超过700亿米,且产量一直处于上升趋势,如果能够将人工智能和计算机视觉技术应用于纺织行业,对纺织行业的价值无疑会是巨大的。 通过探索布样疵点精确智能诊断的优秀算法,提升布样疵点检验的准确度,降低对大量人工的依赖,提升布样疵点质检的效果和效率。
本次课程设计的Demo主要工作是通过对布样图像数据集的处理,对布样中疵点形态、长度、面积以及所处位置进行分析 。
2. 课题要求
数据集涵盖了纺织业中素色布的各类重要瑕疵。数据共包括2部分:原始图片和瑕疵的标注数据。具体要求如下 :
- 数据集提供用于训练的图像数据和标注数据,文件夹结构:
- 正常
- 薄段
- 笔印
- …
- 织稀
- 正常: 存放无瑕疵的图像数据,jpeg编码图像文件。图像文件名如:XXX.jpg
- 薄段、笔印、…、织稀: 按瑕疵类别分别存放瑕疵原始图片和用矩形框进行瑕疵标注的位置数据。
- 图像文件jpeg编码。标注文件采用xml格式,其中filename字段是图像的文件名,name字段是瑕疵的类别,bndbox记录了矩形框左上角和右下角的位置。图像左上角为(0,0)点,向右x值增加,向下y值增加。
- 其中defect_code和瑕疵的对应关系:
| norm | defect_1 | defect_2 | defect_3 | defect_4 | defect_5 | defect_6 | defect_7 | defect_8 | defect_9 | defect_10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 正常 | 扎洞 | 毛斑 | 擦洞 | 毛洞 | 织稀 | 吊经 | 缺经 | 跳花 | 油/污渍 | 其他 |
注:“其他”代表剩余所有类型的瑕疵。
3. 代码分析
-
导入程序所需包
import pandas as pd import numpy as np from matplotlib import pyplot as plt from matplotlib import rc as matplotlib_rc from code.main.flaw import Flaw其中os是python的标准库,pandas、numpy、matplotlib是外部引入的第三方库,flaw是此课题中对原始数据提取有关信息的部分。
-
通过main函数对各个分析函数进行调用。因为正常数据非常多,如果把正常布匹数据也进行分析的话,会导致绘图非常不均匀,呈现两极化现象,从而看不出效果,故在处理数据时需要删除正常数据。
if __name__ == '__main__':# 获取所有瑕疵类flaws = get_all_flaw("../../data/train/")# 获取所有所有种类名称并去重type_names = list(set([flaw.type for flaw in flaws]))# 所有种类的数量type_num = [0] * len(type_names)# 删除无瑕疵数据index = type_names.index("正常")del type_names[index]del type_num[index]# 获取所有瑕疵种类的大小type_size = get_all_type_size(flaws, type_names, type_num)df = pd.DataFrame([type_names, type_num,[size[0] for size in type_size],[size[1] for size in type_size],[size[2] for size in type_size]],index=["类型", "数量", "最小瑕疵", "平均瑕疵", "最大瑕疵"])df_sorted = df.T.sort_values(by="数量", ascending=False)print(df_sorted)draw_type_num(df_sorted[0:]['类型'],df_sorted[0:]['数量'], save_path="./")draw_type_size(df_sorted[0:]['类型'],df_sorted[0:]['平均瑕疵'],df_sorted[0:]['最小瑕疵'],df_sorted[0:]['最大瑕疵'], save_path="./")draw_flaw_pos(flaws, save_path="./") -
统计瑕疵数量函数
def draw_type_num(type_names, type_num, save_path):根据type_names和type_num绘制柱状图,如果传入save_path,则保存图片。其中type_names作为x轴,type_num作为y轴,save_path是保存的路径。def draw_type_num(type_names, type_num, save_path=None):# 设置图片大小plt.figure(figsize=(10, 8))plt.bar(type_names, type_num)plt.grid(alpha=0.4, linestyle=':')plt.xticks(rotation=90)# 设置xy标签和图标题plt.xlabel("瑕疵类型")plt.ylabel("样本数量")plt.title("瑕疵类型-样本数量")# 保存图片if save_path:plt.savefig(save_path + "瑕疵类型-样本数量.svg")plt.show() -
统计瑕疵大小函数
draw_type_size(type_names, type_size_avg, type_size_min,type_size_max, save_path): 根据 type_names 和type_num 两个参数绘制柱状图,如果传入了save_path,则保存图片。其中type_size_avg 表示平均瑕疵值,type_size_max 表示最大瑕疵值,type_size_min 表示最小瑕疵值, type_names 作为x轴, save_path是分析图像将其保存的路径。def draw_type_size(type_names, type_size_avg, type_size_min,type_size_max, save_path=None):# 设置图片大小plt.figure(figsize=(10, 8))plt.bar(type_names, type_size_max, label="最大瑕疵")plt.bar(type_names, type_size_avg, label="平均瑕疵")plt.bar(type_names, type_size_min, label="最小瑕疵")plt.grid(alpha=0.4, linestyle=':')plt.xticks(rotation=90)plt.legend(loc="upper left")# 设置xy标签和图标题plt.xlabel("瑕疵类型")plt.ylabel("瑕疵大小")plt.title("瑕疵类型-瑕疵大小")# 保存图片if save_path:plt.savefig(save_path + "瑕疵类型-瑕疵大小.svg")plt.show() -
统计瑕疵位置函数
def draw_flaw_pos(flaws, save_path, step)::通过定义等高线的x、y坐标,将原始数据变成网格数据,画出瑕疵出现的位置。flaws是所有瑕疵类数组,save_path是保存路径,step是区域宽度。此函数中调用了numpy中meshgrid()函数 。def draw_flaw_pos(flaws, save_path=None, step=100):# 定义等高线图的横纵坐标x,yx = range(0, 2560, step)y = range(0, 1920, step)# 将原始数据变成网格数据X, Y = np.meshgrid(x, y)# 设置图片大小plt.figure(figsize=(10, 8))# 各地点对应的高度数据height = np.zeros((len(y), len(x)))for flaw in flaws:if flaw.poses is None:continuefor pos in flaw.poses:for i in range(pos['ymin'], pos['ymax'], step):for j in range(pos['xmin'], pos['xmax'], step):height[(i // step) - 1][(j // step) - 1] += 1# 填充颜色plt.contourf(X, Y, height, 10, alpha=0.6, cmap=plt.cm.hot)# 绘制等高线C = plt.contour(X, Y, height, 10, colors='black')# 显示各等高线的数据标签plt.clabel(C, inline=True, fmt="%d", fontsize="x-large")# 保存图片if save_path:plt.savefig(save_path + "瑕疵坐标分布.svg")plt.show() -
代码
flaw.py定义瑕疵类型,对瑕疵进行相关操作。其中type2id(flaw_type, bin_classify=False)传入瑕疵类型名称,返回瑕疵类型编号。里面还定义了flaw类,其中get_size(self)获取每个瑕疵对应大小。下面只列举了瑕疵分类,完整代码见附录。import xml.etree.ElementTree as ETtypes = ['正常', '扎洞', '毛斑', '擦洞', '毛洞', '织稀', '吊经', '缺经', '跳花', '油/污渍', '其他']
4. 扩展部分
| 第三方库 | 作用 |
|---|---|
| Matplotlib | 用Python实现的类matlab的第三方库,用以绘制一些高质量的数学二维图形 |
| NumPy | 基于Python的科学计算第三方库,提供了矩阵,线性代数等的解决方案 |
| pandas | 为Python编程语言提供了高性能,易于使用的数据结构和数据分析工具 |
| os | 是Python的标准库,提供通用的、基本的操作系统交互功能 |
| xml.etree.ElementTree | 对整个XML文档进行操作 |
-
程序中调用了matplotlib的
matplotlib_rc()库,设置显示中文字体。 -
程序中调用了matplotlib中的
pyplot,对画布图像作出相应的改变。下面仅举几例进行说明。plt.figure(figsize=(10, 8))::自定义画布大小,使后面的图形输出在这块规定了大小的画布上。plt.bar(type_names, type_num):画柱状图,定义了横坐标和纵坐标的内容。
plt.grid(alpha=0.4, linestyle=':'):生成透明度为0.4的网格,网格线为连续的虚线。
plt.xticks(rotation=90):更改绘制x轴标签方向(与水平方向的逆时针夹角度数)
plt.title("瑕疵类型-样本数量"):设置网格的标题。 -
统计瑕疵位置函数
def draw_flaw_pos()调用的是numpy中meshgrid()库 ,将原始数据变成网格数据。还调用了np.zeros((len(y), len(x)))生成相应大小的零矩阵。 -
主函数中
pd.DataFrame()对数据进行整合,将瑕疵大小分布以表格的显示形式列出来。 -
获取瑕疵函数
get_all_flaw(path)调用了os.listdir,以获取指定的文件夹包含的文件或文件夹的名字的列表。 -
代码flaw.py中调用
xml.etree.ElementTree库,ET.parse(xml_name)对文件进行解析。
5. 结果截图
- 瑕疵类型-样本数量
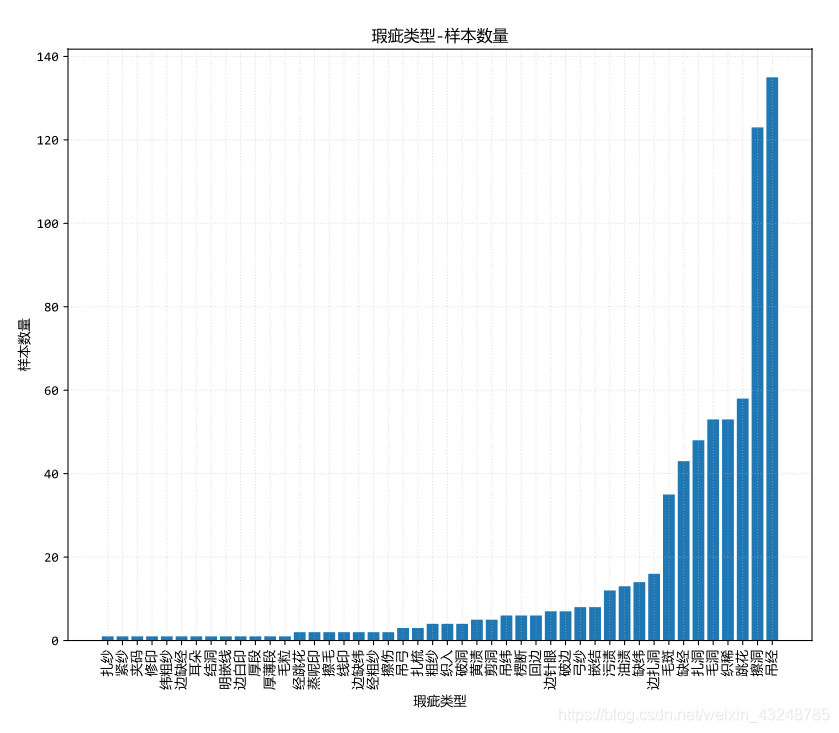
可以看出瑕疵主要集中在右侧,因此后期可以对瑕疵进行明确的分类,分成十一分类就可以了。
-
瑕疵类型-瑕疵大小
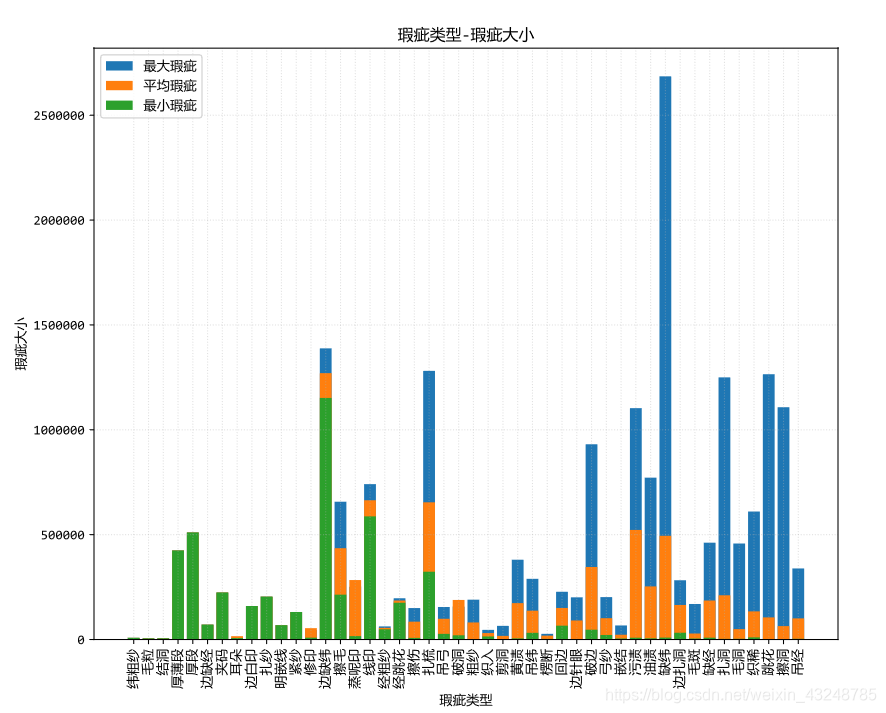
瑕疵大小的绘制,应该先画最大瑕疵,再画平均瑕疵,最后画最小瑕疵,这样前面的图像才不会被完全覆盖,我们才可以清晰地看出结果。
-
瑕疵坐标分布

从中可以看出瑕疵主要分布在一块区域,分布比较集中,这样对于企业来说,制作布匹或者质量检查时就可以着重注意那块区域。
6.收获和改进建议
-
收获:
学习Python这门课程的这段时间以来, 我认识到Python是一种高级动态,完全面向对象的语言,方便快捷,学会了python的基本使用,能够使用python中的graphics库绘制图形化界面和用户交互界面,通过对numpy和pandas的使用,我了解到python在数据分析领域的强大作用。
除此之外,这门课程对我的工程实践项目很有帮助,将其应用到项目中,减少开发周期,从而不再只是单纯的理论学习,更重要的是学以致用。使用Python核心还是要牢牢抓住实际工程的需要,除了技术本身之外,对业务和产品的理解也都非常重要。
-
改进建议:
- 建议老师正式开课之前可以让同学提前搜索Python的相关应用,或者课前给出问题,让学生带着思考预习,从而提前了解本节课的内容,更快吸收课程内容。
- 建议可以做个presentation,主要让同学讲代码框架或者是核心代码,主要思路,而不是很多的代码内容。
附录(源码)
pre_analysis.py
import os
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import rc as matplotlib_rc
from code.main.flaw import Flaw# 设置中文字体
font = {'family': "YaHei Consolas Hybrid"}
matplotlib_rc("font", **font)def get_all_flaw(path):"""根据路径解析所有图片标签(xml文件),获取所有瑕疵类:param path:待解析的图片路径:return: flaws 包含所有瑕疵的数组"""file_names = os.listdir(path)# 获取所有类型flaws = [] # 所有flawfor file_name in file_names:if file_name[-3:] == "jpg":flaw = Flaw(pic_name=path + file_name)flaws.append(flaw)return flawsdef get_all_type_size(flaws, type_names, type_num):"""根据传入的flaw数组,计算各种类型flaw的大小:param flaws:flaw数组:param type_names:对应的type_names数组:param type_nums:对应的type_nums数组:return: type_size各种类型的大小 [min,avg,max]"""type_size = [] # 所有种类的大小 [min,avg,max]for i in range(len(type_names)): # 初始化type_size.append([10000000, 0, 0])for flaw in flaws:if flaw.type == '正常': continue# 获取所有种类数量index = type_names.index(flaw.type)type_num[index] += 1# 获取所有种类的大小[min,sum,max]for size in flaw.get_size():type_size[index][1] += sizeif size < type_size[index][0]:type_size[index][0] = sizeif size > type_size[index][2]:type_size[index][2] = sizetype_size[index][1] /= len(list(flaw.get_size()))# 将大小的和转化为平均值for index in range(len(type_size)):type_size[index][1] /= type_num[index]return type_sizedef draw_type_num(type_names, type_num, save_path=None):"""根据type_names和type_num绘制柱状图,如果传入save_path,则保存图片:param type_names:作为x轴:param type_num:作为y轴:param save_path:保存路径:return:None"""# 设置图片大小plt.figure(figsize=(10, 8))plt.bar(type_names, type_num)plt.grid(alpha=0.4, linestyle=':')plt.xticks(rotation=90)# 设置xy标签和图标题plt.xlabel("瑕疵类型")plt.ylabel("样本数量")plt.title("瑕疵类型-样本数量")# 保存图片if save_path:plt.savefig(save_path + "瑕疵类型-样本数量.svg")plt.show()def draw_type_size(type_names, type_size_avg, type_size_min,type_size_max, save_path=None):"""根据type_names和type_num绘制柱状图,如果传入save_path,则保存图片:param type_size_avg: 平均值:param type_size_max: 最大值:param type_size_min: 最小值:param type_names:作为x轴:param save_path:保存路径:return:None"""# 设置图片大小plt.figure(figsize=(10, 8))plt.bar(type_names, type_size_max, label="最大瑕疵")plt.bar(type_names, type_size_avg, label="平均瑕疵")plt.bar(type_names, type_size_min, label="最小瑕疵")plt.grid(alpha=0.4, linestyle=':')plt.xticks(rotation=90)plt.legend(loc="upper left")# 设置xy标签和图标题plt.xlabel("瑕疵类型")plt.ylabel("瑕疵大小")plt.title("瑕疵类型-瑕疵大小")# 保存图片if save_path:plt.savefig(save_path + "瑕疵类型-瑕疵大小.svg")plt.show()def draw_flaw_pos(flaws, save_path=None, step=100):"""画出所有瑕疵出现的位置:param flaws:所有瑕疵类数组:param save_path:保存路径:param step:区域宽度:return:None"""# 定义等高线图的横纵坐标x,yx = range(0, 2560, step)y = range(0, 1920, step)# 将原始数据变成网格数据X, Y = np.meshgrid(x, y)# 设置图片大小plt.figure(figsize=(10, 8))# 各地点对应的高度数据height = np.zeros((len(y), len(x)))for flaw in flaws:if flaw.poses is None:continuefor pos in flaw.poses:for i in range(pos['ymin'], pos['ymax'], step):for j in range(pos['xmin'], pos['xmax'], step):height[(i // step) - 1][(j // step) - 1] += 1# 填充颜色plt.contourf(X, Y, height, 10, alpha=0.6, cmap=plt.cm.hot)# 绘制等高线C = plt.contour(X, Y, height, 10, colors='black')# 显示各等高线的数据标签plt.clabel(C, inline=True, fmt="%d", fontsize="x-large")# 保存图片if save_path:plt.savefig(save_path + "瑕疵坐标分布.svg")plt.show()if __name__ == '__main__':# 获取所有瑕疵类flaws = get_all_flaw("../../data/train/")# 获取所有所有种类名称并去重type_names = list(set([flaw.type for flaw in flaws]))# 所有种类的数量type_num = [0] * len(type_names)# 删除无瑕疵数据index = type_names.index("正常")del type_names[index]del type_num[index]# 获取所有瑕疵种类的大小type_size = get_all_type_size(flaws, type_names, type_num)df = pd.DataFrame([type_names, type_num,[size[0] for size in type_size],[size[1] for size in type_size],[size[2] for size in type_size]],index=["类型", "数量", "最小瑕疵", "平均瑕疵", "最大瑕疵"])df_sorted = df.T.sort_values(by="数量", ascending=False)print(df_sorted)draw_type_num(df_sorted[0:]['类型'],df_sorted[0:]['数量'], save_path="./")draw_type_size(df_sorted[0:]['类型'],df_sorted[0:]['平均瑕疵'],df_sorted[0:]['最小瑕疵'],df_sorted[0:]['最大瑕疵'], save_path="./")draw_flaw_pos(flaws, save_path="./")
flaw.py
import xml.etree.ElementTree as ETtypes = ['正常', '扎洞', '毛斑', '擦洞', '毛洞', '织稀', '吊经', '缺经', '跳花', '油/污渍','其他']def type2id(flaw_type, bin_classify=False):"""传入瑕疵类型名称,返回瑕疵类型编号| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |10 ||正常|扎洞|毛斑|擦洞|毛洞|织稀|吊经|缺经|跳花|油/污渍|其他|如果bin_classify==True| 0 | 1 ||正常|瑕疵|:param flaw_type: 字符串类型:param bin_classify: bool,是否是二分类问题:return: 整型"""if bin_classify:return 0 if flaw_type == '正常' else 1if flaw_type == "油渍" or flaw_type == "污渍":flaw_type = '油/污渍'try:return types.index(flaw_type)except ValueError:return types.index('其他')def typeid2defect_code(typeid):"""传入瑕疵编号,返回defect_code,为最后结果统计服务0 --> norm1 --> defect_12 --> defect_2...:param typeid: 整型:return: 字符串"""return 'norm' if typeid == 0 else 'defect_{}'.format(typeid)class Flaw(object):"""瑕疵类,仅包含3个属性pic_name : 该瑕疵所属的图片名称id : 瑕疵类型idtype : 瑕疵类型名称poses: 瑕疵位置,为一个字典数组,一个样本可能有多个瑕疵{xmin: ,ymin: ,xmax: ,ymax: }"""def __init__(self, pic_name=None):"""初始化一个瑕疵类型,如果填写了图片名称,则自动解析相关xml文件,获取瑕疵信息:param pic_name: 图片名称"""self.pic_name = pic_nameself.id = 0self.type = "正常"self.poses = Noneif pic_name:# 通过pic_name获取xml_namexml_name = pic_name[:-3] + "xml"try:# 解析瑕疵文件tree = ET.parse(xml_name)root = tree.getroot()self.pic_name = root[0].textself.type = root[4][0].textself.id = type2id(self.type)self.poses = []# 解析所有瑕疵位置for flow_pos in root.iter('bndbox'):d = {'xmin': int(flow_pos[0].text),'ymin': int(flow_pos[1].text),'xmax': int(flow_pos[2].text),'ymax': int(flow_pos[3].text)}self.poses.append(d)except FileNotFoundError:passdef get_size(self):"""获取每个瑕疵对应大小:return: Yield"""if self.poses:for pos in self.poses:yield (pos['xmax'] - pos['xmin']) * (pos['ymax'] - pos['ymin'])def print_flaw(self):print("所属图片名:", self.pic_name)print("瑕疵类型:", self.type)print("瑕疵类型编号:", self.id)print("瑕疵位置:", self.poses)print("瑕疵大小:", list(self.get_size()))这篇关于对布匹的疵点数据集进行分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




