本文主要是介绍sqlldr批量导入数据到Oracle,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.基本命令
查看参数:$sqlldr
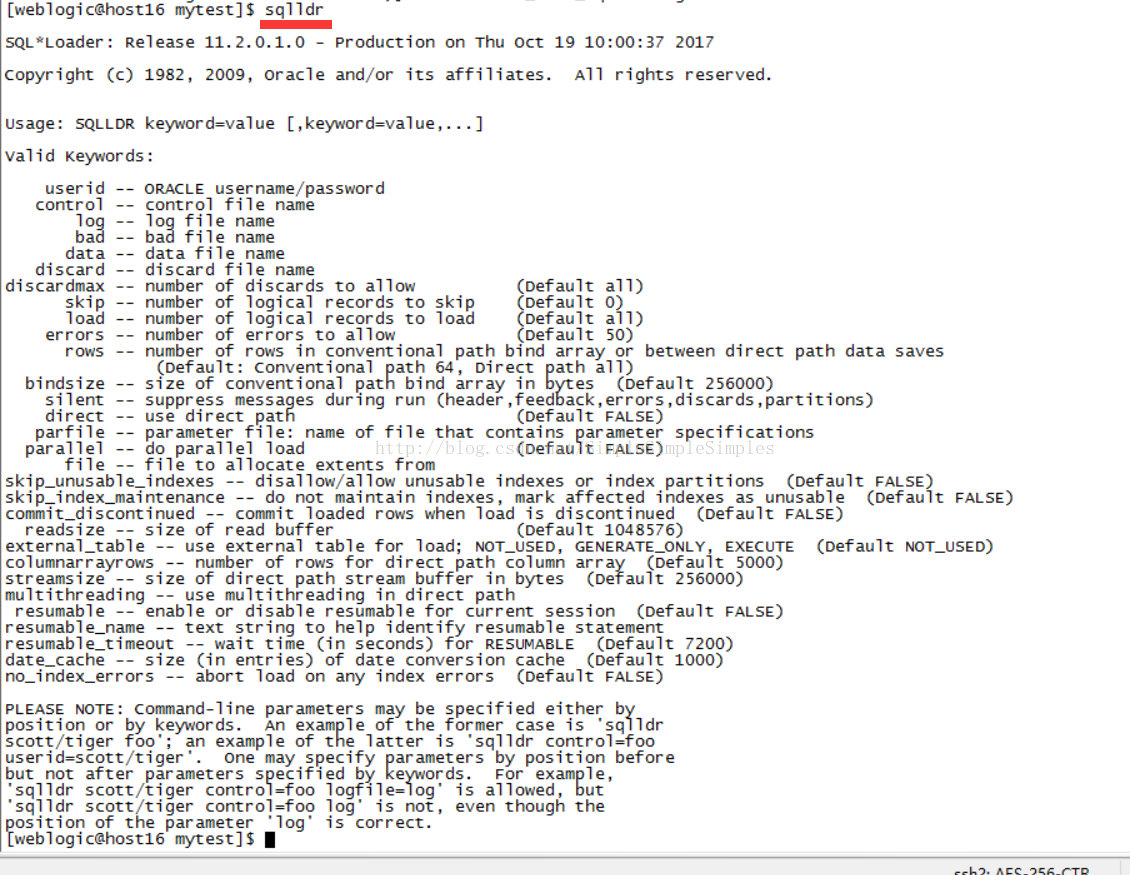
2.导入示例
用服务器创建导入数据的export.txt文件,示例如下:
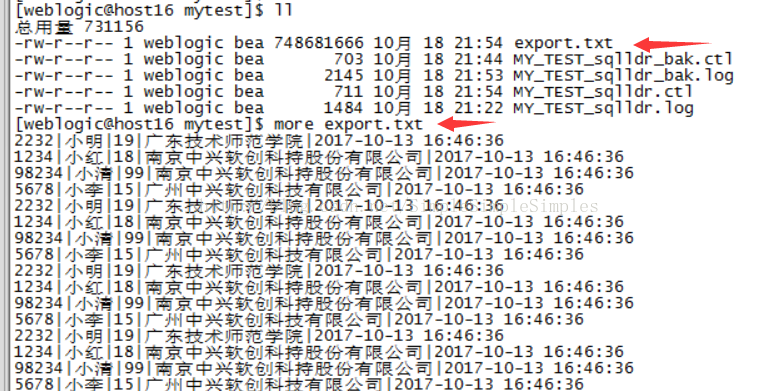
编写MY_TEST_sqlldr_bak.ctl控制文件
OPTIONS(BINDSIZE=10485760,READSIZE=2097152,ERRORS=-1,ROWS=250000,skip=1)
LOAD DATA
CHARACTERSET AL32UTF8
APPEND INTO TABLEMY_TEST
FIELDS TERMINATED BY X'7c'TRAILING NULLCOLS
(
"ID" CHAR(11) NULLIF "ID"=BLANKS,
"NAME" CHAR(20) NULLIF "NAME"=BLANKS,
"AGE" CHAR(12) NULLIF "AGE"=BLANKS,
"ADDRDSS" CHAR(50) NULLIF "ADDRDSS"=BLANKS,
"HIRE_DATE" DATE "YYYY-MM-DD HH24:MI:SS" NULLIF"HIRE_DATE"=BLANKS
)
ctl常见的一些参数解析:
characterset :字符集, 一般使用字符集 AL32UTF8,如果出现中文字符集乱码时,改成 ZHS16GBK。
fields terminated by 'string':文本列分隔符。当为tab键时,改成'\t',或者 X'09';空格分隔符 whitespace,换行分隔符 '\n' 或者 X'0A';回车分隔符'\r' 或者 X'0D';默认为'\t'。
optionally enclosed by 'char':字段包括符。当为 ' ' 时,不把字段包括在任何引号符号中;当为"'" 时,字段包括在单引号中;当为'"'时,字段在包括双引号中;默认不使用引用符。
fields escaped by 'char':转义字符,默认为'\'。
trailing nullcols:表字段没有对应的值时,允许为空
insert:为缺省方式,在数据装载开始时要求表为空;
append:在表中追加新记录 ;
replace:删除旧记录,替换成新装载的记录 ;
truncate:先清空表,再添加记录;
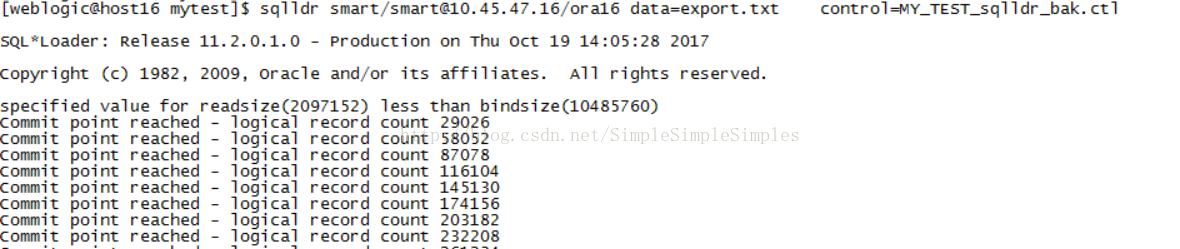
执行导入命令测试(其实就是跟sqluldr2反向执行):
$sqlldr smart/smart@10.45.47.16/ora16 data=export.txt control=MY_TEST_sqlldr_bak.ctl
注意:在数据导入数据库表后,查询表数据时,会发现最后一个字段的数据中含有类似空格的字符,其实不是空格,是回车换行符,通过replace函数将其替换掉即可,如下红色部分处理:
OPTIONS(DIRECT=TRUE,ERRORS=10000000,SKIP=1)LOADDATA
CHARACTERSETZHS16GBK
INTOTABLE TEMP_001 TRUNCATE
FIELDSTERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
TRAILING NULLCOLS
(
PROD_ID CHAR(32) "TRIM(:PROD_ID)",
ACC_NUM CHAR(20) "REPLACE(:ACC_NUM,CHR(13),'')"
)
添加默认值的关键字 CONSTANT使用方法示例:
OPTIONS(BINDSIZE=2097152,READSIZE=2097152,ERRORS=-1,ROWS=50000)
LOAD DATA
CHARACTERSET AL32UTF8
INSERT INTO TABLE TAR_GRP_IMPORT_TEMP APPEND
FIELDS TERMINATED BY X'7C' TRAILING NULLCOLS
(
OBJ_ID "REPLACE(:OBJ_ID,CHR(13),'')",
BATCH_ID CONSTANT 17
)
sqlldr支持的数据类型,可以定义14种数据类型:
CHAR
DATE
DECIMAL EXTERNAL
DECIMAL
DOUBLE
FLOAT
FLOAT EXTERNAL
GRAPHIC EXTERNAL
INTEGER
INTEGER EXTERNAL
SMALLINT
VARCHAR
VARGRAPHIC
a、字符类型数据
CHAR[ (length)] [delimiter]
length缺省为 1,ctl文件中char(20) 一般对应数据库表中 varchar2(20) 。
b、日期类型数据
DATE [ ( length)]['date_format' [delimiter]
使用to_date函数来限制
ctl文件中 date "yyyy-mm-dd hh24:mi:ss" 对应数据库表中 date
c、字符格式中的十进制
DECIMAL EXTERNAL [(length)] [delimiter]
用于常规格式的十进制数(不是二进制=> 一个位等于一个bit)
ctl文件中 decimal external 对应 数据库表中 number
d、压缩十进制格式数据
DECIMAL (digtial [,precision])
ctl文件中 decimal对应 数据库表中 number
e、双精度符点二进制
DOUBLE
f、普通符点二进制
FLOAT
g、字符格式符点数
FLOAT EXTERNAL [ (length) ] [delimiter]
h、双字节字符串数据
GRAPHIC [ (legth)]
i、双字节字符串数据
GRAPHIC EXTERNAL[ (legth)]
j、常规全字二进制整数
INTEGER
ctl文件中的integer 对应数据库表中 integer
k、字符格式整数
INTEGER EXTERNAL
l、常规全字二进制数据
SMALLINT
m、可变长度字符串
VARCHAR
ctl文件中varchar 对应 数据库表中 varchar2
n、可变双字节字符串数据
VARGRAPHIC
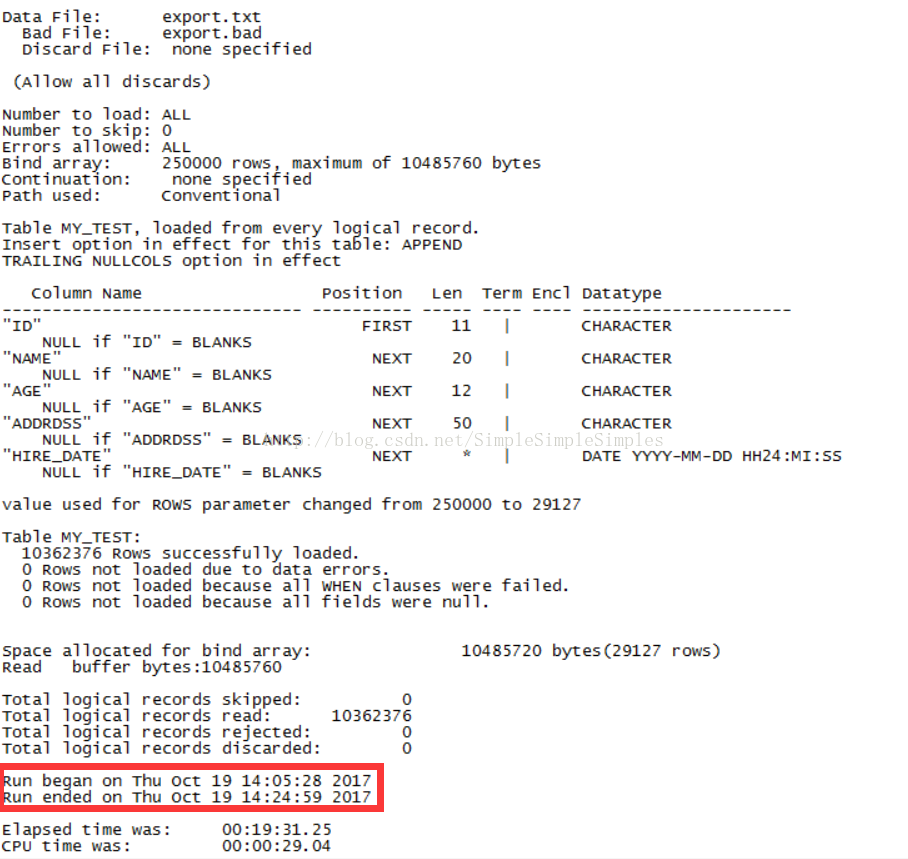
3.导入性能测试(append的形式)
命令示例:
$sqlldrsmart/smart@10.45.47.16/ora16 data=export.txt control=MY_TEST_sqlldr_bak.ctl
这篇关于sqlldr批量导入数据到Oracle的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








