本文主要是介绍NLP中CLM是什么意思,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大多数现代的NLP系统都遵循一种非常标准的方法来训练各种用例的新模型,即先训练后微调。在这里,预处理训练的目标是利用大量未标记的文本,在对各种特定的自然语言处理任务(如机器翻译、文本摘要等)进行微调之前,建立一个通用的语言理解模型。

在本文章中,我们将讨论两种流行的训练前方案,即掩蔽语言建模(MLM)和因果语言建模(CLM)。
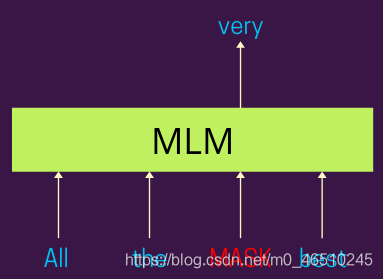
屏蔽语言模型解释
在屏蔽语言建模中,我们通常屏蔽给定句子中特定百分比的单词,模型期望基于该句子中的其他单词预测这些被屏蔽的单词。这样的训练方案使这个模型在本质上是双向的,因为掩蔽词的表示是根据出现的词来学习的,不管是左还是右。你也可以把它想象成一个填空式的问题陈述。
下面的图显示了更详细的视图与损失计算步骤-
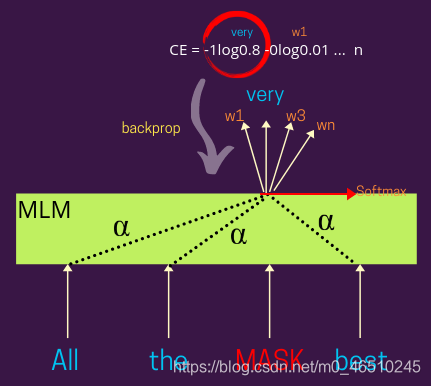
在这里,被屏蔽词的表示可以像BERT和其他变体一样是基于注意力的,或者你也可以不这样设计它。基于α(注意权重)的分布可以权衡其他的表示输入的单词学习表示被遮蔽的词,例如-α= 1将给予同等重视,周围的单词(也就是说,每个词将遮蔽平等的贡献表示)。
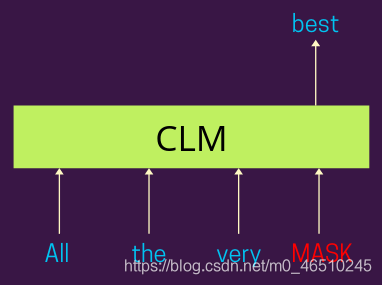
因果语言模型解释
因果语言模型,这里的思想是预测一个给定句子中的蒙面标记,但与MLM不同,这个模型被只考虑发生在它左边的单词来做同样的事情(理想情况下,这个可以是左的或者右的,想法是使它是单向的)。这样的训练方案使得这种模式在本质上是单向的
正如您在下面的图中可以看到的,该模型预计将根据出现在其左侧的单词预测句子中出现的掩码标记。基于模型对实际标签的预测,计算交叉熵损失并反向传播来训练模型参数。
下面的图显示了更详细的视图与损失计算步骤-
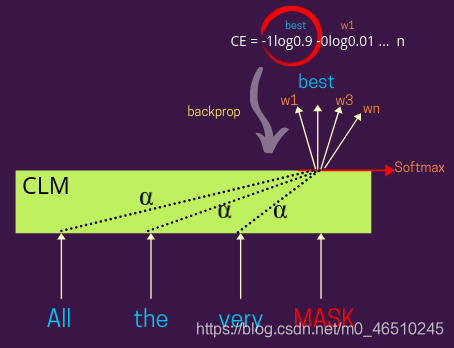
在这里,屏蔽词的表示可以是基于注意力的,就像GPT和变体一样,或者你也可以不这样设计它,就像我们在LSTM里使用它一样。基于α的分布(见图)你可以权衡其他的表示输入的单词学习表示被遮蔽的词,例如-α= 1将给予同等重视,周围的单词(也就是说,每个词将平等贡献了遮蔽表示)。
这些系统也被称为解码器模型,因为在典型的编码器-解码器架构中,如机器翻译、文本摘要等,解码器(文本生成器)的工作原理类似。
何时使用?
当目标是学习输入文档的良好表示时,MLM 损失是首选,而当我们希望学习生成流畅文本的系统时,CLM 是首选。 此外,从直觉上看,这是有道理的,因为在为每个单词学习良好的输入表示时,您想知道它出现的单词是左还是右,而当您想学习生成文本的系统时,您只能看到什么到目前为止看到了什么,您已经生成了所有内容(就像人类的写作方式一样)。 因此,制作一个在生成文本的同时也可以窥视另一侧的系统可能会引入限制模型创造力的偏差。
尽管在训练具有编码器和解码器的整个架构时,您经常会发现 MLM 和 CLM 损失。 两者都有其优点和局限性,一种称为 XLNet 的新模型使用置换技术来利用两全其美(MLM 和 CLM)。
作者:Prakhar Mishra
这篇关于NLP中CLM是什么意思的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





