本文主要是介绍Anaconda中 conda install / Solving environment 速度慢问题其中一些可能的方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Anaconda中 conda install / Solving environment 速度慢问题其中一些可能的方法
问题
今天在用实验室的Linux主机创建新的conda环境的时候遇到了一个问题,在使用Anaconda中的conda install来安装包的时候会卡在Solving environment这一步,有时候还会多次失败重试

原因
Conda中包含的软件越来越多,而且软件的不同版本都保留了下来,软件的索引文件越来越大,安装一个新软件时搜索满足环境中所有软件依赖的软件的搜索空间也会越来越大,导致solving environment越来越慢,确定待安装包的依赖包之间的兼容和已安装软件之间的兼容,获得需要下载的包和对应版本这个过程非常耗时
解决方法
方法一:用pip install而不是conda install
先别急,这是我最近想明白的一点,也是我目前试过的唯一有用的一种方法,虽然很蠢但是有用(本人小白且愚钝,大佬们见笑):
不用conda install,直接用pip install或者pip3 install
原理
与其说原理不如说我脑袋宕机的原因,我自己的电脑上Windows系统拥有本地的原装Python环境和Anaconda的base中的环境,所以直接调用python的话可能会调用到本地没有配置好的环境,相应地,pip指令也会写入对应的本地环境
但是可以通过上移conda的环境变量或者删除本地环境实现
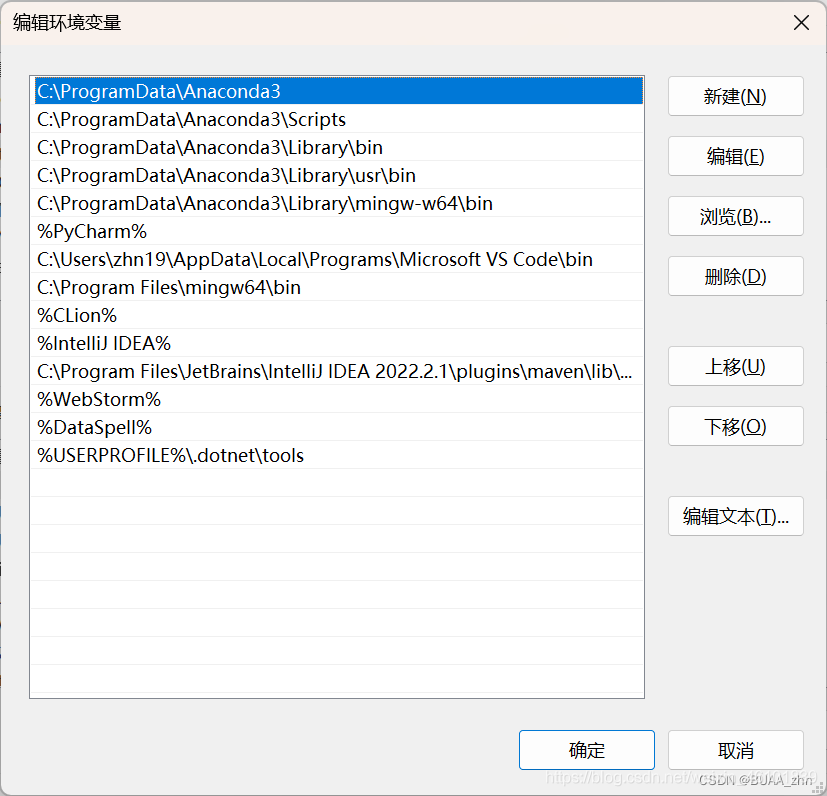
但是当你进入你设置好的Anaconda环境时,无论是conda install还是pip install都会在对应的conda虚拟环境里安装,因此只需要考虑其中一种安装方式即可
很多地方说conda的速度比pip快之类的,所以都推荐用conda,但是在设置了镜像之后,其实原生的pip方法速度也很快
先放几个国内的镜像源:
#中科大源、清华源、豆瓣源
https://pypi.mirrors.ustc.edu.cn/simple/
https://pypi.tuna.tsinghua.edu.cn/simple
https//pypi.doubanio.com/simple/
如果看到这里能帮到你,恭喜你!如果不了解具体操作请继续往下看!
方法二:用mamba安装
mamba是用于管理环境的 CLI 工具,相比于conda 对包和环境的管理,安装过程中对包和依赖的检查过程是最耗时的,mamba可以实现并行运算,速度比较快
安装mamba
conda install mamba -n base -c conda-forge
通过mamba安装的方式和conda一样
mamba install package
但是安装mamba的过程也需要conda install然后又会卡在Solving environment那里,逻辑闭环了属于是
方法三:更换镜像源
这也是很多博客里面提到的方法之一,我认为是治标不治本甚至也不治标,因为速度瓶颈主要在检查包和依赖,跟网速关系不大,关于设置和更换镜像源的方法,我在后面部分介绍了,有需要的可以往后看!
方法四:更新conda
conda update -n env_name conda
这个方法没有验证过,但是在更新的时候可能会遇到更新失败的情况,有些时候是因为更新的是miniconda,可以尝试把conda改成anaconda:
conda update -n env_name anaconda
conda常见虚拟环境操作
创建虚拟环境
conda create --name env_name python=version
其中-n后面的是你自己的虚拟环境的名称,version部分是你指定的Python版本,注意,Python版本在设定之后基本就不能变了,不然很多相关的依赖版本也会变
但是自己新建之后的环境中是不会有Anaconda原生的base环境中那么多丰富的包的(不知道是不是我的问题),所以我选择直接克隆base环境,这样的好处很多必要的包不用重新下载,坏处是Python版本就定死了
克隆虚拟环境
conda create -n new_env_name --clone old_env_name
其中new_env_name是你新建的环境的名称,old_env_name是你要克隆的环境,如果是base的话就是:
conda create -n new_env_name --clone base
进入虚拟环境
conda activate env_name
退出虚拟环境
conda deactivate
删除虚拟环境
conda remove --name env_name --all
查看虚拟环境
conda env list
或者
conda info -e
添加镜像源
使用pip添加镜像源路径
在使用pip的时候可以通过直接在路径前面加-i实现,也即在命令后面添加:
#中科大源、清华源、豆瓣源
-i https://pypi.mirrors.ustc.edu.cn/simple/
-i https://pypi.tuna.tsinghua.edu.cn/simple
-i https//pypi.doubanio.com/simple/
使用conda添加镜像源配置
使用conda的时候一般要先配置镜像源而不是直接在命令后面添加指令
查看镜像源的指令
conda config --show channels
也可以通过以下命令:
conda config --show-sources
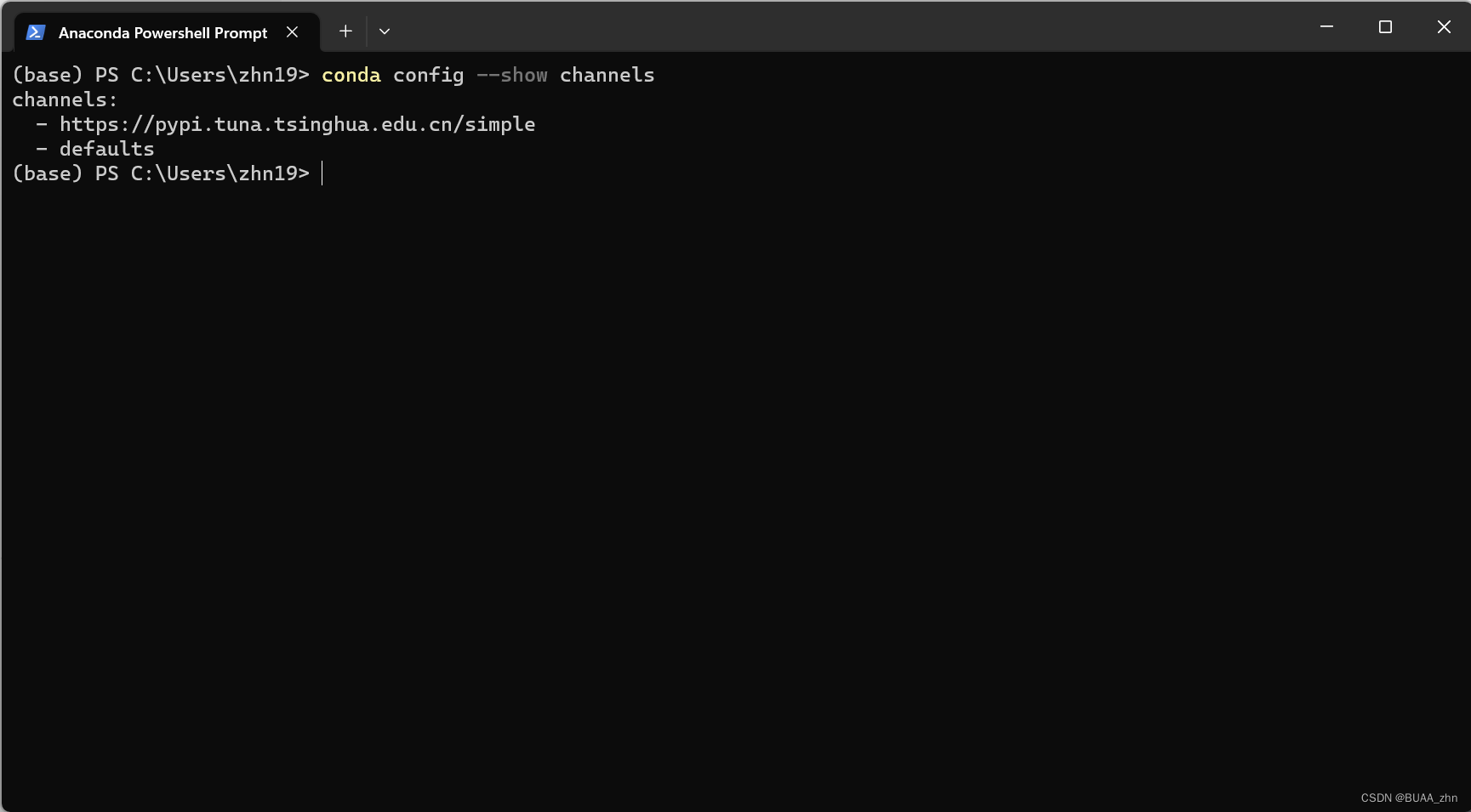
图中的- defaults就是默认源,即使不设置也会有一些国内镜像源,比如我在安装PyTorch的时候就是从阿里云的镜像源下载的:
Collecting nvidia-cudnn-cu11==8.5.0.96Downloading https://mirrors.aliyun.com/pypi/packages/dc/30/66d4347d6e864334da5bb1c7571305e501dcb11b9155971421bb7bb5315f/nvidia_cudnn_cu11-8.5.0.96-2-py3-none-manylinux1_x86_64.whl (557.1 MB)
添加镜像源的指令
conda config --add channels mirror_url
其中的mirror_url是镜像源的网址
# 清华源
conda config --add channels https://pypi.tuna.tsinghua.edu.cn/simple# 阿里源
conda config --add channels https://mirrors.aliyun.com/pypi/simple/#豆瓣源
conda config --add channels https://pypi.doubanio.com/simple/ #中科大源
conda config --add channels https://pypi.mirrors.ustc.edu.cn/simple/

删除镜像源的指令
conda config --remove channels https://pypi.tuna.tsinghua.edu.cn/simple
有时候会遇到镜像源失效的情况,这时候可以通过以上指令删除对应镜像源
实例
安装PyTorch和TensorFlow的过程我都没来得及记录,以下是后面更改PyTorch版本的情况
在安装PyTorch的时候安装了11.6版本,但是和显卡驱动不适配,可以通过以下命令查看CUDA版本:
nvidia-smi
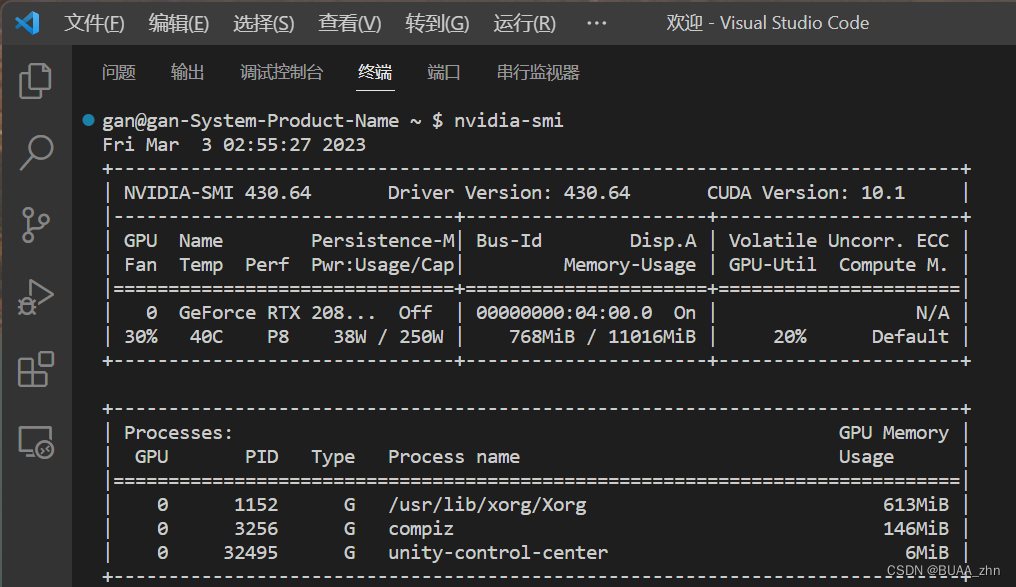
可以在右上角看到CUDA版本是10.1
由于PyTorch版本是和CUDA版本严格绑定的,所以如果用高版本的PyTorch强行调用就会显示CUDA和显卡驱动版本太老。由于更改显卡驱动和CUDA版本很麻烦,所以我退而求次,试图安装10.1版本的PyTorch
官网目前的版本只有11.6和11.7,但是可以通过下面的链接找到之前的版本:
PyTorch官网老版本链接
包含10.1版本的最高PyTorch版本只到1.7.1:
# CUDA 9.2
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=9.2 -c pytorch# CUDA 10.1
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=10.1 -c pytorch# CUDA 10.2
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=10.2 -c pytorch# CUDA 11.0
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch# CPU Only
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cpuonly -c pytorch
但是以上命令除了依旧会遇到conda install的问题之外,还会遇到有些镜像源找不到对应版本的情况,因此采用下面的方式:
# CUDA 11.0
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html# CUDA 10.2
pip install torch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2# CUDA 10.1
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html# CUDA 9.2
pip install torch==1.7.1+cu92 torchvision==0.8.2+cu92 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html# CPU only
pip install torch==1.7.1+cpu torchvision==0.8.2+cpu torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
我安装的是1.6.0版本PyTorch的10.1CUDA,但是又遇到了torchaudio版本不匹配的问题:

ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
torchaudio 0.13.1 requires torch==1.13.1, but you have torch 1.6.0+cu101 which is incompatible.
无所谓,我会出手,更新torchaudio到指定版本就可以,通过查阅 torchaudio官方文档
可以知道1.6.0版本的PyTorch对应的是0.6.0版本的torchaudio,python版本是3.6~3.8
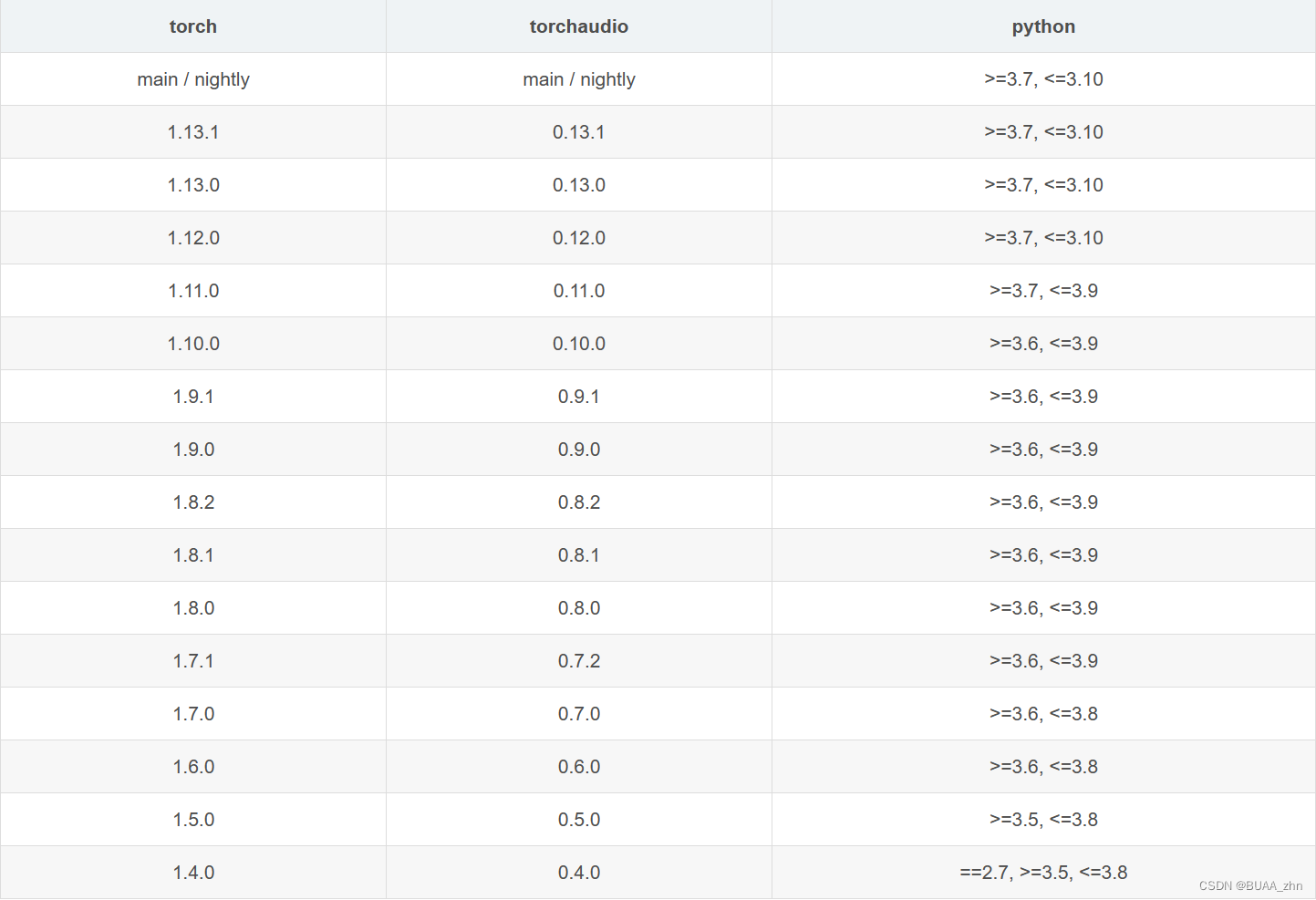
成功安装0.6.0版本torchaudio之后
测试一下:
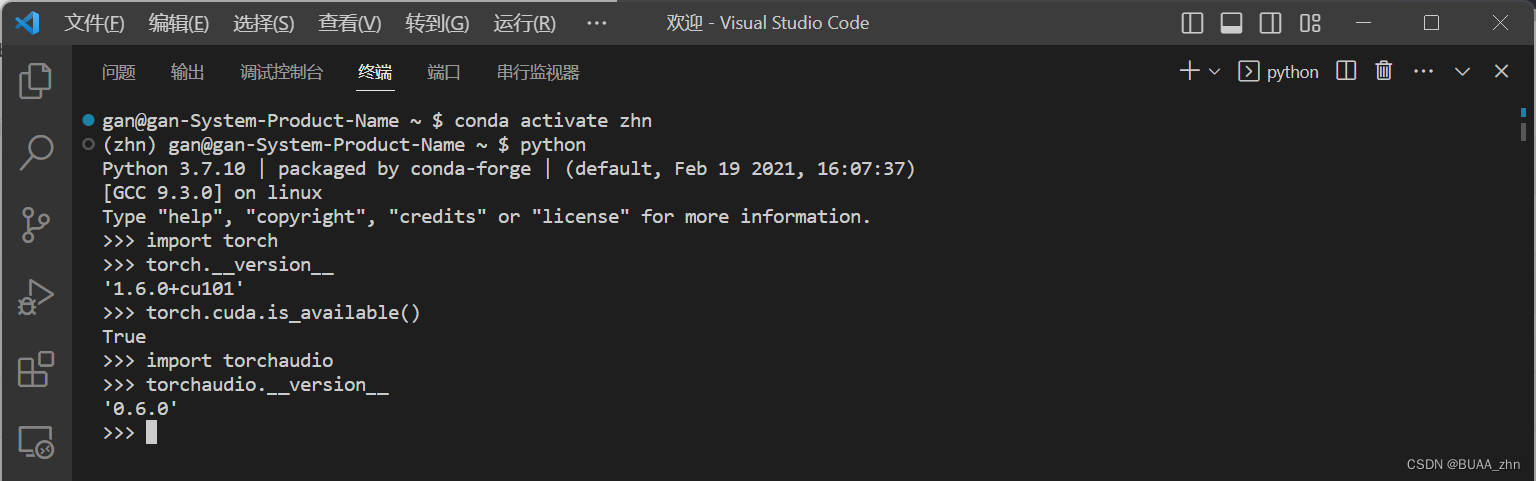
全部可以正常运行!
这篇关于Anaconda中 conda install / Solving environment 速度慢问题其中一些可能的方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







