本文主要是介绍1.2.1存储结构:层次化存储结构、外存(辅存)、内存(主存)、CPU内部的寄存器、Cache(相联存储器),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.2.1存储结构:层次化存储结构、外存(辅存)、内存(主存)、CPU内部的寄存器、Cache(相联存储器)
- 存储系统--层次化存储结构
- 外存(辅存)
- 内存(主存)
- CPU内部的寄存器
- Cache(相联存储器)
- 这么多的存储结构,作为一个程序员来看的话,可以操作那些内容呢?
存储系统–层次化存储结构
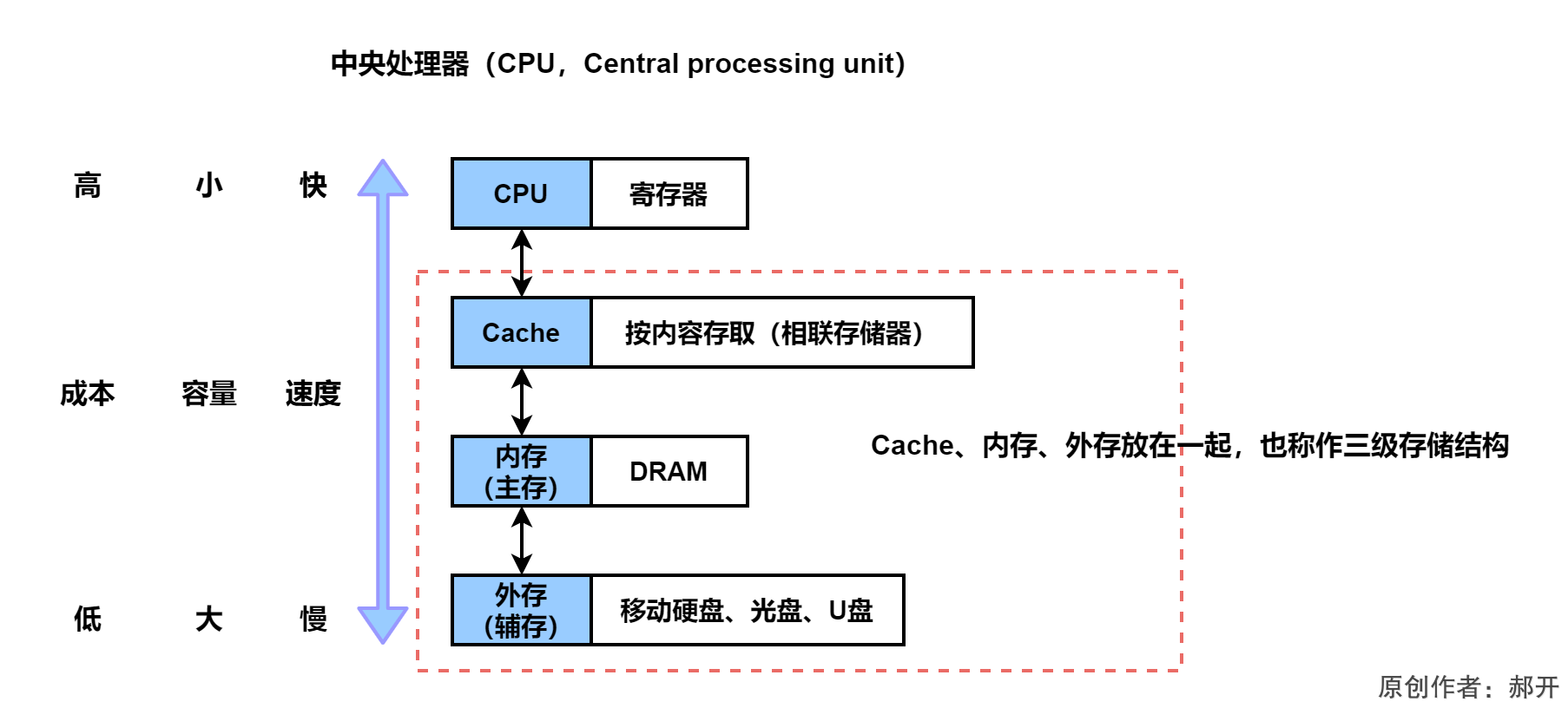
整个层次化存储系统划分,每一个存储系统里面会有多种存储器,这些存储器可以分层,各个层次速度、容量、以及成本是相差很大的,由于速度、容量、成本三者的平衡关系,所以才有层次化存储结构。
外存(辅存)
我们解除较多的存储器,比如像U盘、移动硬盘、光盘这一类是挂接在计算机外部的存储器,我们一般把这一类存储器叫做外存,也叫做辅助存储器,简称辅存。
我们买了一台电脑,硬盘规格为500G或1T,虽然这个硬盘是集成在一台计算机的内部,我们也把它叫做外存。
内存(主存)
在外存除外,还有内存的说法,内存可以理解为集成在主板上,属于主机部分的存储器,这种存储器叫做内存,也简称主存。
我们在买电脑的时候,一般看到内存8G或16G,比较富有的还可以自己扩容32G内存,这里的内存指的就是我们的内存,即主存。
这种存储器的特点:一般用RAM(随机存储器)来组成的。
典型特点是吊链数据会丢失,经常说电脑卡了,重启一下就好了,就是因为重启之后,内存会被清掉,然后重新分配,去加载需要的东西,所以对于内存一般用到的是RAM。
DRAM(动态随机存储器) 是内存所用到的存储器的类型,D表示动态,会定时做刷新的动作,与DRAM相对比的话,还有ROM(只读存储器)。
ROM(只读存储器) 吊链数据不会丢失,比如操作系统,不会每次重启,就要重装操作系统,还有BIOS吊链数据也不会丢失。
可以发现,从外存到内存越接近核心CPU,它的存储的整个容量是越来越小,而速度会越来越快,而成本也会越来越高,比如你买4T的硬盘也就几百块,你买16G的内存条,要上千了。
CPU内部的寄存器
整个层次化结构所划分的部分当中,最快的是CPU内部的寄存器,这些寄存器组可以暂存数据,CPU可以直接使用,所以速度是极快的。寄存器的容量是只有bit大小的,一般是与字长有关系,常见的像32位的系统,寄存器大小只有32bit大。
Cache(相联存储器)
CPU中的寄存器和内存对比的话,其容量和速度差距是非常大的,因此在这种速度容量不匹配的情况下,在二者之间插入了一个折中的存储器,速度和容量是二者折中,从而解决CPU和内存速度容量不匹配的问题,这就是Cache的来源。
Cache也叫做高速缓存,我们目前在软考体系中,缓存只了解CPU和内存之间的缓存。而每一级结构或者每两级及结构都是可以去插入一个缓存的,但是目前考试所涉及的一般指CPU和内存之间的缓存——高速缓存。
高速缓存这种存储器的组成比较特殊,用的是相联存储器,也就是按内容存取的存储器。可以通过页面编号直接去查找它的存储位置,内容与位置相关,就叫做按内容存取,名字就叫做相联存储器。
整个层次化存储系统划分,每一个存储系统里面会有多种存储器,这些存储器可以分层,各个层次速度、容量、以及成本是相差很大的,由于速度、容量、成本三者的平衡关系,所以才有层次化存储结构。
以实际场景为例
喜欢玩游戏的、或者需要安装大型软件的,比如100G的游戏,显然内存是不可能放下的,因此只能存放在外存,那么存放在外存,最终有谁来调用?是由CPU来调用,而CPU只有bit的容量,是如何支撑100G的游戏跑起来的?最终游戏是在内存当中运行的,一个内存8G或者16G,因此内存加载的时候,不会一次性把整个100G的都放进去,它也放不下,因此只会加载一部分,一般是用什么调什么。
为什么可以用什么调什么这样来执行?
这个过程当中也有局部性原理来支撑,所谓的局部性原理就是用什么调什么,由于用的都是某一个区域、或者某一个区域相邻的数据居多,所以此时可以支撑整个软件的运行,简单来看的话,由于只需要一部分数据立即来使用,因此可以将100G切片之后,用什么调一部分调到内存中去,这种内存与外存可以把这两个级别的存储器放在一起称之为虚拟存储体系,那这个调用的过程一般由操作系统来控制,调到内存中,依然与CPU有速度容量上的差距,因此还会调到Cache,再由Cache再调到CPU的寄存器。
因此将Cache、内存、外存放在一起,也称作三级存储结构。
这么多的存储结构,作为一个程序员来看的话,可以操作那些内容呢?
显然可以安装软件,安装在外存中,所以可以操作外存
使用过程中,是可以写一些编程地址的,因此内存也是可以使用的
而寄存器,在汇编指令中有时候会用到,因此也可以对寄存器进行操纵
唯一不能用到的是Cache,Cache对程序员来说一般会有透明性,也就是程序员其实是看不到Cache的,因此不能对它进行操作。
这篇关于1.2.1存储结构:层次化存储结构、外存(辅存)、内存(主存)、CPU内部的寄存器、Cache(相联存储器)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



