本文主要是介绍R爬虫可视化第1季-卫视实时收视率对比,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
几经思考,终于下定决心开设这个公众号,希望在这里与大家分享一些关于数据分析&数据挖掘有意思的事情,如果对于内容有任何的意见或建议,都希望大家在评论中不吝赐教。
言归正传,在今后的几期推送中,会与大家分享一些自己用R语言爬虫+可视化实现的案例,第一期就从本人最喜欢看的电视说起,分析各省级卫视收视率。
部分篇章代码量较多,可能无法在正文中全部给出,之后会在公众号中给出代码的下载地址。
相关Package:
## 爬虫相关包
library(RCurl)
library(XML)
library(RSelenium)
## 数据读取相关包(表格和地图文件)
library(data.table)
library(maptools)
## R中实现sql代码处理表格
library(sqldf)
## 数据可视化相关包
library(ggplot2)
library(ggthemes)数据爬取:
实时数据可以在欢娱网(http://www.csm-huan.com)中获得,该网站数据的爬取需要借助RSelenium包获得动态页面,网站的界面如下:
爬取的核心代码:
ele_str1 <- sprintf('//*[@id="tbody"]/tr[%d]/td[1]/a',i)
elem_1 <- getNodeSet(htmlParse(remDr$findEleent(using = "xpath",ele_str1) $getElementAttrbute("outerHTML")[[1]],ecoding='utf-8'), '//a[@href="javascript:vid(0);"]')
station <- sapply(elem_1,xmlValue)剩下要做的就是循环得到每个电视台的数据,其中i为循环变量
地图数据读取、融合:
地图数据的处理需要完成两部分工作,包括地图shp文件读取与收视率数据融合
数据读取:
china_map <- readShapePoly("中国地图shp格式/china_basic_map/bou2_4p.shp")
china_map1 <- china_map@data
china_map1$id <- 0:(nrow(china_map1)-1)
china_map1$id <- as.character(china_map1$id)
china_map2 <- fortify(china_map)
china_map3 <- left_join(china_map2, china_map1,by='id')
colnames(province_rate)[2] <- 'NAME'
china_map3$NAME <- as.character(china_map3$NAME)收视率数据融合:
province_rate <- sqldf('select b.*,a.* from tv_rate a inner join province b on a.station = b.station')
province_rate$rate <- as.numeric(substr(as.character(province_rate$rate),1,6))
china_map4 <- left_join(china_map3,province_rate,by = 'NAME')数据可视化-全国地图展示数据:
完成了前期数据准备,就要进入到了数据可视化的阶段,我们选取了ggplot包进行数据的可视化,并且结合ggthemes包提供的一些不错的配色方案,提高展示的可读性。
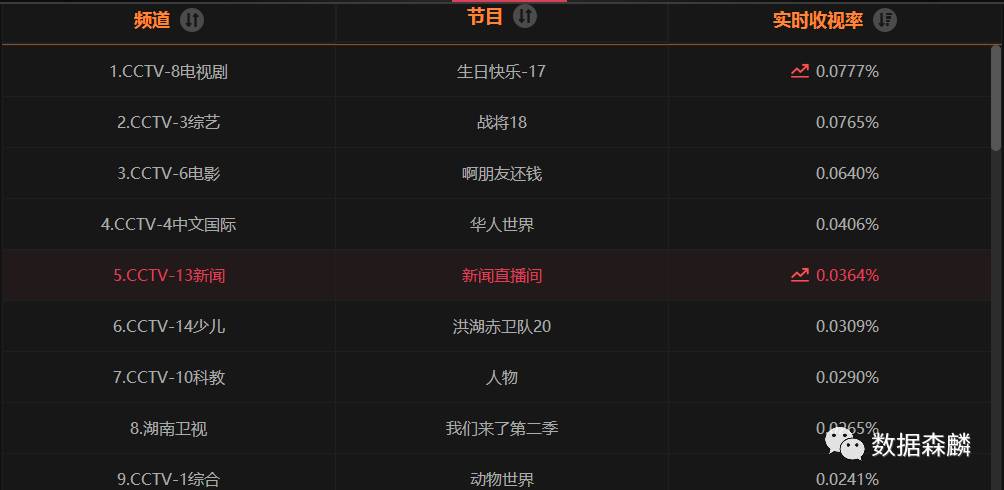
首先绘制的是全国地图数据,我们用颜色的深浅表示收视率的高低,分别选取了ggthems包中theme_economist,theme_wsj,theme_map三种配色方案作图进行对比
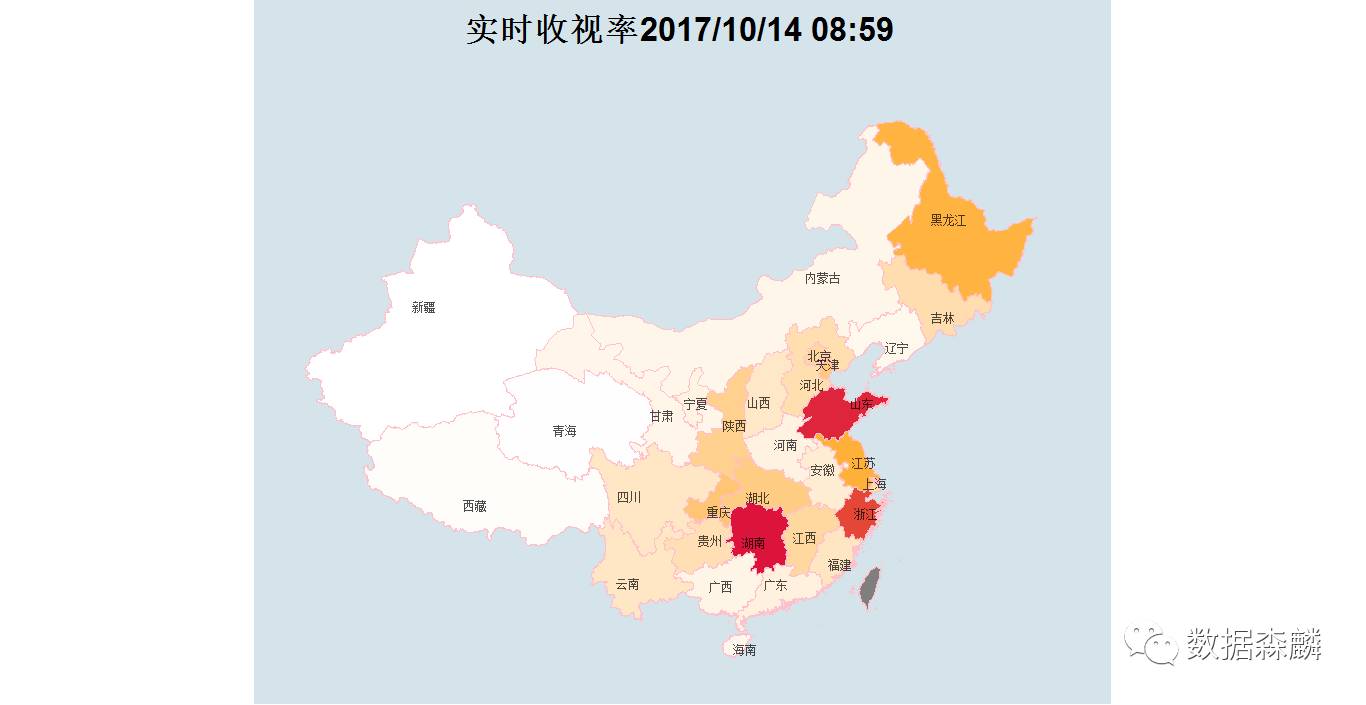
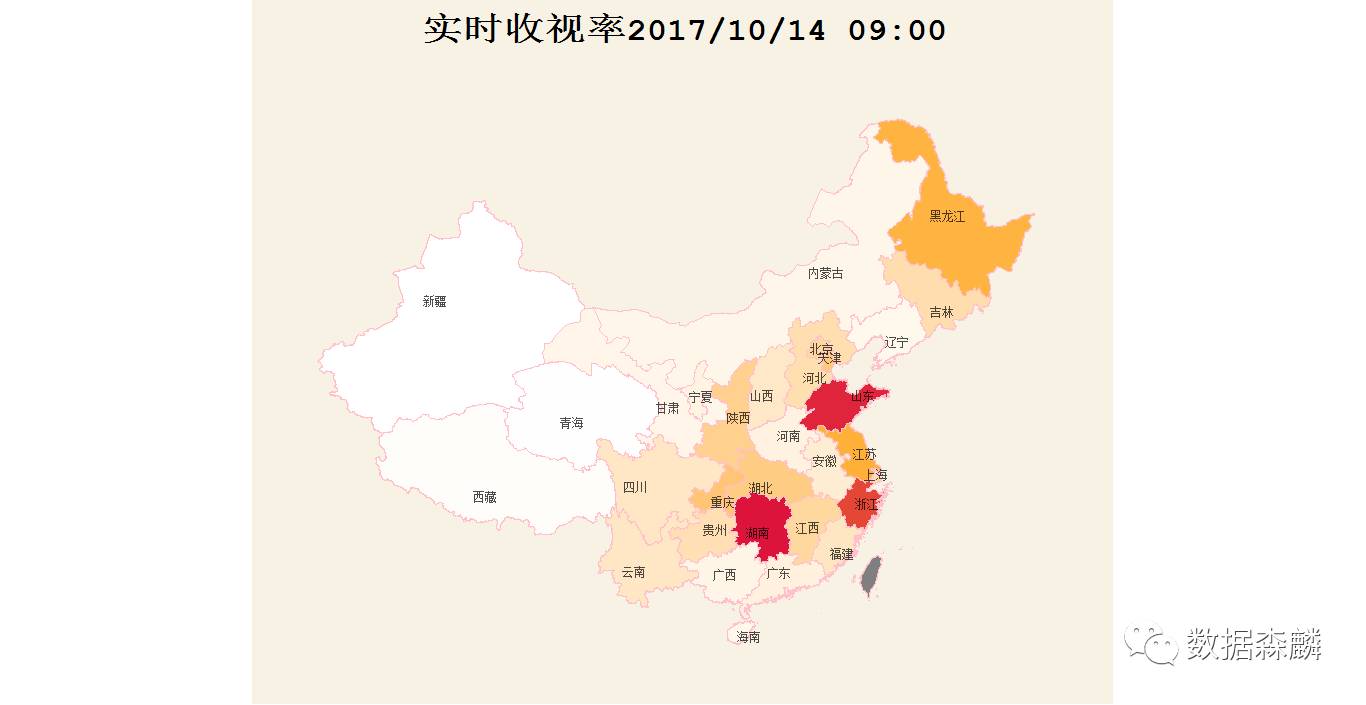
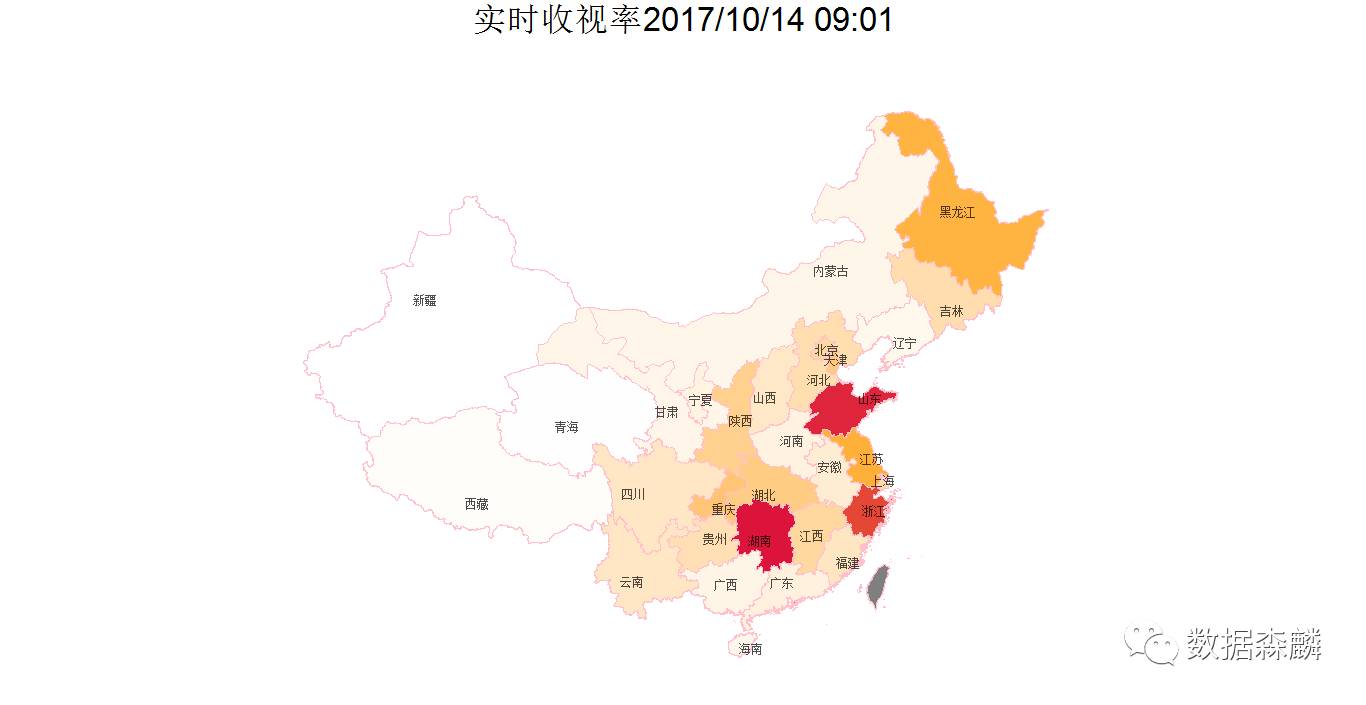
附作图代码:
p <- ggplot() + geom_polygon(data=china_map4,aes(x=long,y=lat,group=group,fill=收视率百分比),col='pink')+coord_map()+ scale_fill_gradient2(low='white',high='#DC143C',mid='orange', midpoint=max(province_rate$rate,na.rm = TRUE)/2)+ xlim(73,137)+ylim(17,55)+ geom_text(data=province_rate,aes(x=longitude,y=latitude,label=province_name),size=2.8,alpha=0.7)+ ggtitle(label = sprintf('实时收视率%s',format(Sys.time(),format="%Y/%m/%d %H:%M")))+ theme_map()+theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(), axis.ticks = element_blank(), axis.line = element_blank(), axis.text = element_blank(), axis.title = element_blank(), legend.position = 'NONE', plot.title = element_text(hjust=0.5,size=25) )
print(p)数据可视化-分省市对比数据:
与上一部分相比,加入了facet_wrap函数,实现了将各个省市轮廓进行切分,并且根据收视率的高低进行排序,提高可读性,以下分别是上午,下午,晚上三个时段的数据。


我们不难发现,不同收视段的排名靠前节目有明显不同,上午收看电视的观众更加关注股市和民生类节目,下午则更加注重养生,晚上则是娱乐节目的天下,我们可以针对于此进行更加深入的分析。
这篇关于R爬虫可视化第1季-卫视实时收视率对比的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





