本文主要是介绍春城无处不飞花,小白带你侃SparkStreaming(原理引入篇),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍完了SparkSQL,接下来让我们推开SparkStreaming的大门,接收新知识的洗礼。跟刚入坑SparkSQL时一样,让我们来回顾一下Spark的内置模块。

相信勤奋好学的大家肯定都还记得的对吧,那么接下来我们就要正式开始学习SparkStreaming咯~
码字不易,先赞后看,养成习惯!

文章目录
- 第一章 Spark Streaming引入
- 1.1 新的场景需求
- 1.2 Spark Streaming介绍
- 1.3 实时计算所处的位置
- 第二章 SparkStreaming原理
- 2.1 SparkStreaming原理
- 2.1.1 整体流程
- 2.1.2 数据抽象
- 2.2 DStream相关操作
- 2.2.1 Transformations
- 2.2.2 Output/Action
- 2.3 总结
第一章 Spark Streaming引入
1.1 新的场景需求
- 集群监控
一般的大型集群和平台, 都需要对其进行监控的需求。要针对各种数据库, 包括 MySQL, HBase 等进行监控;要针对应用进行监控, 例如 Tomcat, Nginx, Node.js 等;要针对硬件的一些指标进行监控, 例如 CPU, 内存, 磁盘 等。
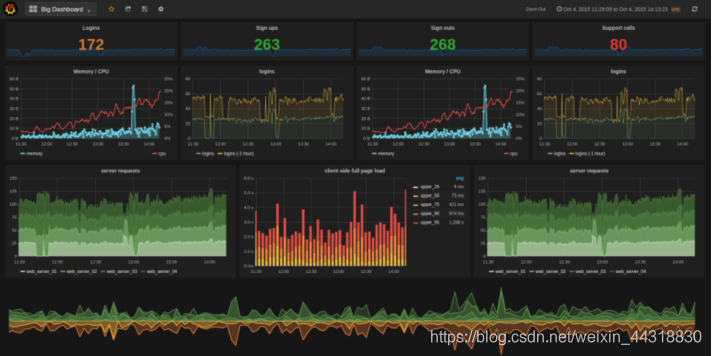
- 双11实时交易数据大屏

- 智慧公厕
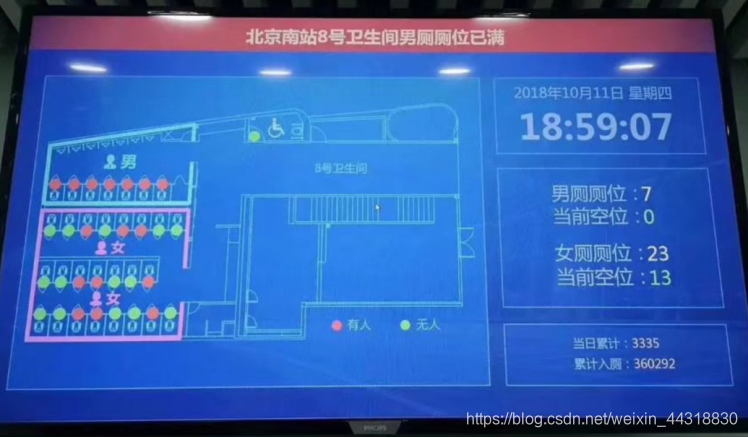
1.2 Spark Streaming介绍
- 官网
http://spark.apache.org/streaming/ - 概述
Spark Streaming是一个基于Spark Core之上的实时计算框架,可以从很多数据源消费数据并对数据进行实时的处理,具有高吞吐量和容错能力强等特点。

- Spark Streaming的特点
1.易用
可以像编写离线批处理一样去编写流式程序,支持java/scala/python语言。
2.容错
SparkStreaming在没有额外代码和配置的情况下可以恢复丢失的工作。
3.易整合到Spark体系
流式处理与批处理和交互式查询相结合。
1.3 实时计算所处的位置

我们也可以看到SparkStreaming也是做分布式实时计算的,但具体其原理是什么,如何操作?具体讲解请往下看。
第二章 SparkStreaming原理
2.1 SparkStreaming原理
2.1.1 整体流程
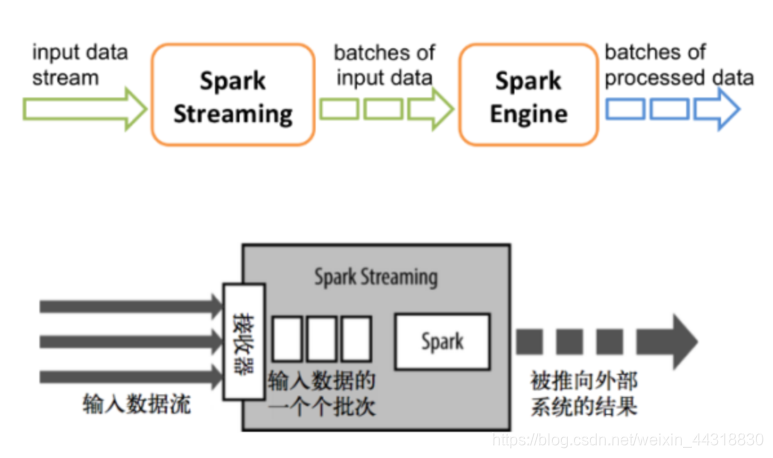
Spark Streaming中,会有一个接收器组件Receiver,作为一个长期运行的task跑在一个Executor上。Receiver接收外部的数据流形成input DStream
DStream会被按照时间间隔划分成一批一批的RDD,当批处理间隔缩短到秒级时,便可以用于处理实时数据流。时间间隔的大小可以由参数指定,一般设置在500毫秒到几秒之间
对DStream进行操作就是对RDD进行操作,计算处理的结果可以传给外部系统。
Spark Streaming的工作流程像下面的图所示一样,接收到实时数据后,给数据分批次,然后传给Spark Engine(引擎)处理最后生成该批次的结果。
2.1.2 数据抽象
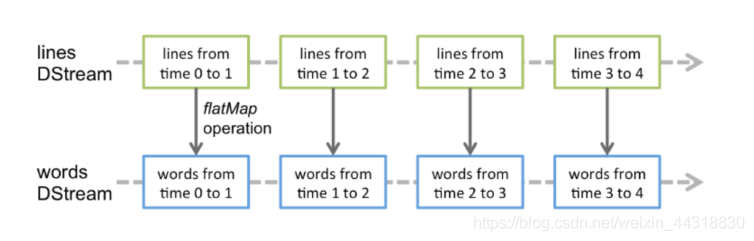
Spark Streaming的基础抽象是DStream(Discretized Stream,离散化数据流,连续不断的数据流),代表持续性的数据流和经过各种Spark算子操作后的结果数据流
- 可以从以下多个角度深入理解DStream
1.DStream本质上就是一系列时间上连续的RDD

2.对DStream的数据的进行操作也是按照RDD为单位来进行的
3.容错性
底层RDD之间存在依赖关系,DStream直接也有依赖关系,RDD具有容错性,那么DStream也具有容错性
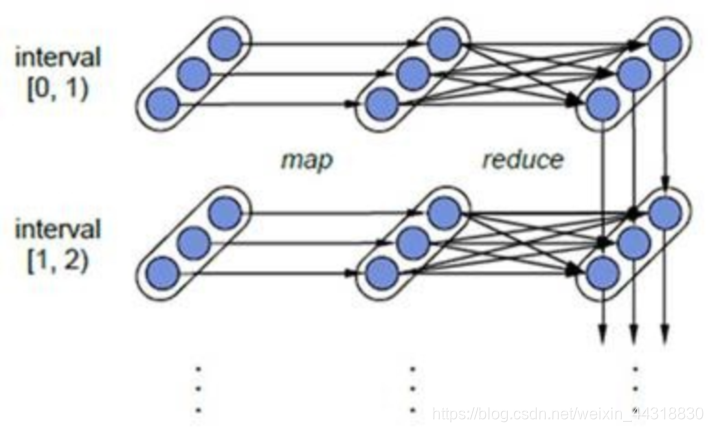
如图:
每一个椭圆形表示一个RDD
椭圆形中的每个圆形代表一个RDD中的一个Partition分区
每一列的多个RDD表示一个DStream(图中有三列所以有三个DStream)
每一行最后一个RDD则表示每一个Batch Size所产生的中间结果RDD
4.准实时性/近实时性
Spark Streaming将流式计算分解成多个Spark Job,对于每一时间段数据的处理都会经过Spark DAG图分解以及Spark的任务集的调度过程。
对于目前版本的Spark Streaming而言,其最小的Batch Size的选取在0.5~5秒钟之间
所以Spark Streaming能够满足流式准实时计算场景,对实时性要求非常高的如高频实时交易场景则不太适合
- 总结
简单来说DStream就是对RDD的封装,你对DStream进行操作,就是对RDD进行操作。对于DataFrame/DataSet/DStream来说本质上都可以理解成RDD

2.2 DStream相关操作
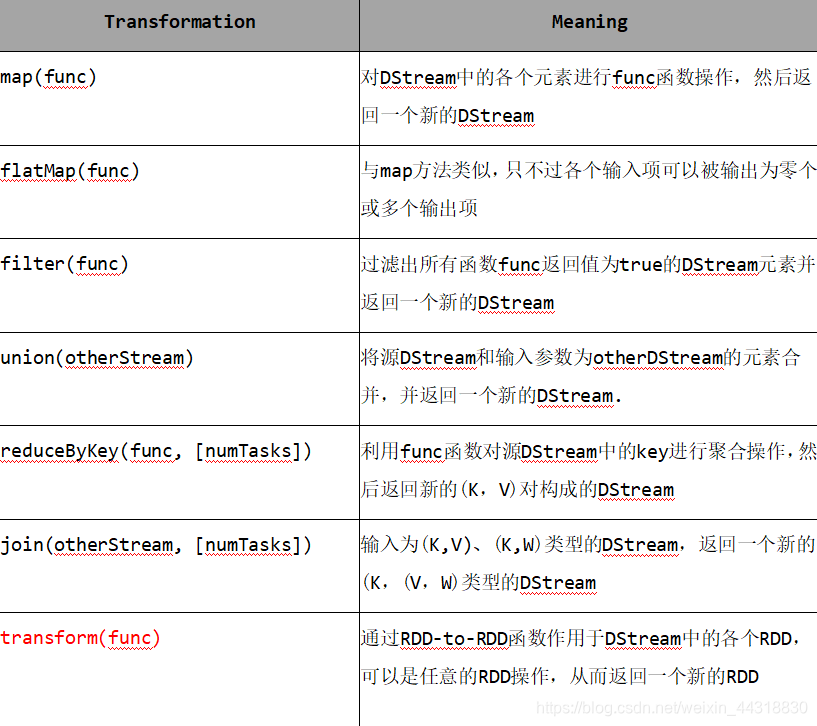
DStream上的操作与RDD的类似,分为以下两种:
- Transformations(转换)
- Output Operations(输出)/Active
2.2.1 Transformations
- 常见Transformation—无状态转换:每个批次的处理不依赖于之前批次的数据
- 特殊的Transformations—有状态转换:特殊的Transformations—有状态转换:当前批次的处理需要使用之前批次的数据或者中间结果。
有状态转换包括基于追踪状态变化的转换(updateStateByKey)和滑动窗口的转换
- 1.UpdateStateByKey(func)
- 2.Window Operations 窗口操作
2.2.2 Output/Action
Output Operations可以将DStream的数据输出到外部的数据库或文件系统。当某个Output Operations被调用时,spark streaming程序才会开始真正的计算过程(与RDD的Action类似)

2.3 总结
如果说用一幅图来总结上面的核心知识点,我觉得下面这个流程图就很不错~
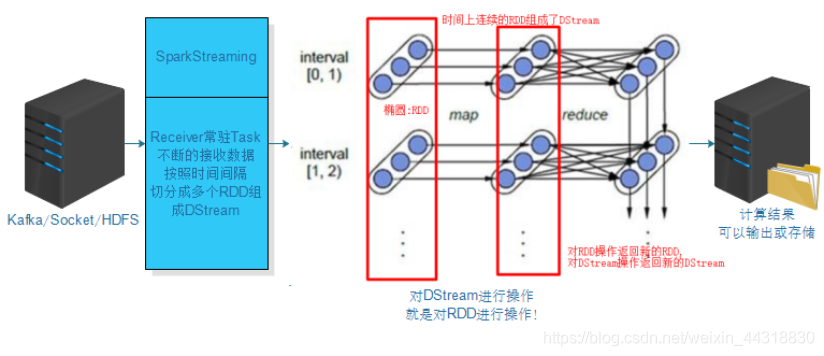
好了,本篇主要讲解的都是基于SparkStreaming的基础理论,下一篇博客博主将带来实战篇,敬请期待!!!受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波(^U^)ノ~YO

这篇关于春城无处不飞花,小白带你侃SparkStreaming(原理引入篇)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






