本文主要是介绍Copysets: Reducing the Frequency of Data Loss in Cloud Storage,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- ABSTRACT
- 1. INTRODUCTION
- 2. THE PROBLEM
- 2.1 Definitions
- 2.2 Random Replication
- 3. INTUITION
- 3.1 Minimizing the Number of Copysets
- 4. DESIGN
- 4.1 Durability of Copyset Replication
- 4.2 Optimality of Copyset Replication
- 4.3 Expected Amount of Data Lost
- 5. EVALUATION
- 5.1 HDFS Implementation
- 5.1.1 Nodes Joining and Failing
- 5.2 HDFS Evaluation
- 5.2.1 Hot Spots
- 5.3 Implementation of Copyset Replication in RAMCloud
- 5.4 Evaluation of Copyset Replication on RAMCloud
- 5.4.1 Master Recovery
- 5.4.2 Backup Recovery
- 6. DISCUSSION
- 6.1 Copysets and Coding
- 6.2 Graceful Power Downs
- 7. RELATED WORK
- 7.1 Combinatorial Design Theory
- 7.2 DHT Systems
- 7.3 Data Center Storage Systems
- 8. ACKNOWLEDGEMENTS
原文链接
ABSTRACT
随机复制广泛应用于数据中心存储系统中,以防止数据丢失。但是,在由于集群范围内的电源中断而同时发生节点故障的常见情况下,随机复制几乎肯定会丢失数据。由于每次数据丢失事件的固定成本很高,许多数据中心运营商倾向于将此类事件的频率降到最低,而代价是在每次事件中丢失更多数据。我们介绍了Copyset复制,这是一种新的通用复制技术,可显著降低数据丢失事件的频率。我们在两个开源数据中心存储系统HDFS和RAMCloud上实现并评估了Copyset复制,结果表明它在所有操作上的开销都很低。这种系统要求每个节点的数据分散在多个节点上(Such systems require that each node’s data be scattered across several nodes),以便并行地恢复和访问数据。 Copyset Replication 在数据分散的节点数和数据丢失的概率之间提供了一种接近最优的折衷。例如,在断电的5000节点RAMCloud集群中,复制集复制将数据丢失的概率从99.99%降低到0.15%。对于Facebook的HDFS集群,它将概率从22.8%降低到0.78%。
1. INTRODUCTION
随机复制是数据中心存储系统的常用技术,如Hadoop分布式文件系统(HDFS)[25]、RAMCloud[24]、Google文件系统(GFS)[14]和Windows Azure[6],以确保持久性和可用性。这些系统将它们的数据划分为chunk,这些chunk在不同机架上随机选择的节点上复制多次(我们使用R表示复制因子)。当一个节点发生故障时,它的数据将通过复制副本从中读取其chunk来恢复。
然而,大规模相关故障(如群集断电,这是一种常见的数据中心故障场景)[7、10、13、25])通过随机复制处理得很差。这个场景强调了系统的可用性,因为不可忽略的节点百分比(0.5%-1%)[7,25]在恢复供电后不会恢复正常。当大量节点未通电时,系统中至少一个区块的所有副本很可能不可用。
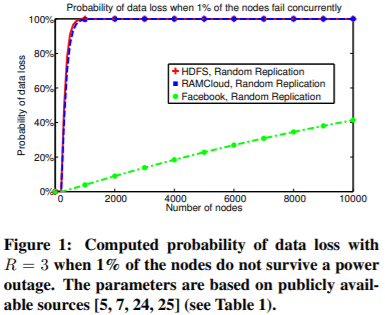
图1显示,一旦集群规模扩展到300个节点以上,这种情况几乎可以保证会在其中一些系统中导致数据丢失事件。这样的数据丢失事件已经被雅虎在实践中记录下来了[25]、LinkedIn[7]和Facebook[5]。据报道,每一个事件都会产生与数据丢失量不成正比的高固定成本。此成本是由于在备份中查找不可用的块或重新计算包含这些块的数据集所需的时间。用Facebook HBase工程团队的技术负责人Kannan Muthukkaruppan的话说:“由于定位和恢复不可用数据的开销,即使丢失一个数据块也会产生很高的固定成本。因此,在每年有固定数量的不可用数据的情况下,每次丢失数据越多,丢失数据的事件就越少,这比丢失数据越少的事件要好得多。我们希望优化以最大限度地降低发生任何数据丢失的概率“[22]。其他数据中心运营商也有类似的经历[8]。
Luiz André Barroso(Google研究员)表达了关于这种权衡的另一种观点:“拥有一个允许存储系统提供商管理数据丢失频率和大小的框架非常有用,因为不同的系统喜欢不同的策略。例如,一些提供商可能更喜欢频繁的、小的损失,因为他们不太可能对数据重建流量峰值的存储节点和结构征税。即使只有一小部分数据不可用,其他服务也可能无法正常工作。这些人宁愿拥有全部或没有,并会选择较少的事件,即使他们在一个更大的损失罚款。
随机复制是在数据丢失事件的频率和每个事件的丢失量之间进行权衡的一个方面。在本文中,我们介绍了Copyset Replication,这是一种替代的通用复制方案,其具有与随机复制相同的性能,它位于频谱的另一端(最后一句好难翻译which sits at the other end of the spectrum)。
Copyset Replication 将节点拆分为Copyset,即R节点集。单个区块的副本只能存储在一个 copyset 上。这意味着只有当某个Copyset Replication的所有节点同时发生故障时,才会发生数据丢失事件。
当每个节点正好是一个副本集的成员时,数据丢失的概率就最小化了。例如,假设我们的系统有9个R=3的节点,它们被分成三个副本集:{1,2,3},{4,5,6},{7,8,9}。只有当节点1、2和3、节点4、5和6或节点7、8和9同时发生故障时,我们的系统才会丢失数据。
相反,在足够数量的块时随机复制(with random replication and a sufficient number of chunks),3个节点的任何组合都将是一个 copyset,同时失败的3个节点的任何组合都将导致数据丢失。(笔者:这里我的理解是比如copyset有很多,而失效与分配数据又是随机的,这就意味着任意的三个节点宕机都会导致部分数据丢失,而现在的分配方式只有在上面三个副本集中任意一个全部宕机时才会导致大量数据丢失)
上述方案在相关故障下提供了尽可能低的数据丢失概率,但是每个事件的数据丢失量很大。但是,上面的copyset选择限制了将每个chunk复制到单个copyset,因此会影响系统的其他操作参数(However, the copyset selection above constrains the replication of every chunk to a single copyset, and therefore impacts other operational parameters of the system.)。值得注意的是,当单个节点发生故障时,只有R − 1个其他节点包含其这份数据。对于某些系统(如HDFS),这限制了节点的恢复时间,因为只有R− 1个其他节点可用于恢复丢失的块的其他节点。这也会在少量节点上产生高负载。(笔者:这里黑体字不太理解是什么意思)
为此,我们将 scatter width (S) 定义为每个节点数据副本的节点数。
使用较低的 scatter width 可能会减慢独立节点故障的恢复时间,而使用较高的 scatter width 则会增加相关故障导致的数据丢失频率。在上面的9节点系统示例中,S = 4时的copyset构造将产生:{1,2,3},{4,5,6},{7,8,9},{1,4,7},{2,5,8},{3,6,9}。在此示例中,节点5的块将在节点4和6或节点2和8处复制。scatter width的增加会带来更多的 copyset 故障可能。
Copyset Replication 的目标是通过使用最小数量的Copyset ,在给定任何 scatter width 的情况下,使数据丢失的概率最小化。我们证明了 Copyset Replication 为这个问题提供了一个近乎最优的解决方案。我们还表明,这个问题已经在组合设计理论领域的不同背景下进行了部分探讨,该理论最初用于设计农业试验[26]。
Copyset Replication 改变了数据丢失事件的模式:假设每年发生一次断电,平均5000节点的RAMCloud集群需要625年才能丢失数据。在这种罕见的情况下,系统平均会丢失64GB(相当于整个服务器的数据量)。使用随机复制时,数据丢失事件频繁发生(在每次断电期间),并且每个事件中都会丢失多个数据块。例如,一个5000节点的RAMCloud集群在每次断电时会损失大约344MB。
为了证明Copyset复制的普遍适用性,我们在两个开源数据中心存储系统HDFS和RAMCloud上实现了它。我们表明,Copyset Replication 在两个系统上产生的开销都很低。它将RAMCloud中的数据丢失概率从99.99%降低到0.15%。此外,Copyset 使用3个副本的复制方案比使用5个副本的随机复制方案实现的数据丢失概率更低。对于Facebook的HDFS部署,Copyset Replication 将数据丢失的概率从22.8%降低到0.78%。
本文分为以下几个部分。第2节提出了问题。第3节提供了解决方案的intuition。第4节讨论了 Copyset Replication 的设计。第5节详细介绍了在HDFS和RAMCloud中实现 Copyset Replication及其性能开销。第6节介绍了 Copyset Replication的其他应用,第7节分析了相关工作。
2. THE PROBLEM
在本节中,我们将研究三个数据中心存储系统(RAMCloud、默认HDFS和Facebook的HDFS)的复制方案,并分析它们在相关故障下的数据丢失漏洞。
2.1 Definitions
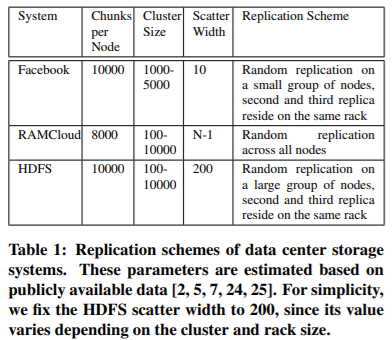
这些系统的复制方案由几个参数定义。R定义为每个块的副本数。在这些系统中,R的默认值是3。N是系统中的节点数。我们调查的三个系统通常有数百到数千个节点。我们假设节点的索引从1到N。S定义为 scatter width 。如果系统的 scatter width 为S,则每一个节点的数据将均匀地分布在一组其他节点上。也就是说,每当某个特定节点出现故障时,其他S个节点都可以参与恢复丢失的副本。表1列出了这三个系统的参数。
我们将一个 set 定义为一组R个不同的节点。copyset 是存储块的所有副本的 set。例如,如果在节点{7、12、15}上复制块,则这些节点形成一个 copyset。我们将展示大量不同的 copysets 增加了在大规模相关故障下丢失数据的概率。在整个论文中,我们将研究 copysets 的数量和系统 scatter width 之间的关系。
我们将 permutation 定义为集群中所有节点的有序列表。例如,{4,1,3,6,2,7,5}是具有N=7个节点的集群的一种排列。
最后,将随机复制定义为以下算法。第一个或主副本放置在整个集群的任意节点上。假设主副本放置在节点i上,则剩余的R− 1次副本放置在从节点{i+1,i+2,…,i+S}中选择的随机机器上。如果S=N− 1,从集群1中的所有节点中选择相同的 secondary 副本的节点。
2.2 Random Replication
大多数大型存储系统使用随机复制的主要原因是,它是一种简单的复制技术,可针对不相关的故障(如单个服务器或磁盘故障)提供强大的保护[13,25]2。这些故障经常发生(在一个大型集群上每年发生数千次[7、10、13]),并由多种原因引起,包括软件、硬件和磁盘故障。跨故障域的随机复制(例如,将块的副本放在不同的机架上)可防止在节点的特定域(例如机架或网段)内发生并发故障。这种故障非常常见,通常一年发生几十次[7,10,13]。
然而,包括雅虎研究人员在内的多个组织!LinkedIn发现,当具有随机复制的集群失去动力(笔者:lose power可能翻译为出现某些故障导致不可用好一些?)时,一些数据块将变得不可用[7,25],也就是说,这些数据块的所有三个副本都将丢失。在这些事件中,整个集群都会断电,通常0.5-1%的节点无法重新启动[7,25]。这种失败并不少见;它们每年在给定的数据中心发生一到两次[7]。
图1显示了这三个系统在断电时丢失数据的概率。该图显示,一旦集群大小超过几百个节点,RAMCloud和HDFS几乎肯定会丢失数据。对于5000个节点的集群,Facebook的数据丢失概率较低,约为20%。
多个团体都表示有兴趣降低数据丢失的发生率,代价是每次事件都会丢失大量数据[3,8,22]。例如,Facebook HDFS团队修改了默认的HDFS实现,以限制其部署中的复制,从而显著降低数据丢失的概率,但代价是在每次事件中丢失更多数据[2,5]。Facebook的HBase工程团队技术负责人证实了这一点,如上所述[22]。Linkedin Hadoop基础设施高级经理Robert Chansler也证实了解决这一问题的重要性:“HDFS节点的通电重启是一个真正的问题,因为它会带来节点相关故障的时刻,以及随之而来的数据变得不可用的威胁。由于这个问题,我们的策略是不关闭Hadoop集群。管理员必须了解如何尽可能快地恢复文件系统的完整性,并且在数据不可用时减少实例数的选项(以增加在这种情况下恢复时的块的数量为代价)可能是一个有用的工具,因为它可以减少总的停机时间“[8]
( and an option to reduce the number of instances when data is unavailable–at the cost of increasing the number of blocks recovered at such instances–can be a useful tool since it lowers the overall total down time")。(笔者:我的理解是把数据分片划小一点,而且存储在更多的机器上,也就是S更大,这句话需要再斟酌斟酌)
一些数据中心运营商倾向于将数据丢失事件的频率降至最低的主要原因是,每次数据丢失事件都有一个固定的成本,该成本与每次事件中丢失的数据量不成正比。从辅助存储中定位和检索数据的成本可能会导致整个数据中心运营团队花费大量与数据丢失量不成正比的时间[22]。还有其他与数据丢失事件相关的固定成本。用罗伯特·钱斯勒的话说:“在数据丢失的情况下[经常]数据可以重新计算。对于重新计算,应用程序通常会在任何数据丢失时重新计算其整个数据集。这会导致固定的计算成本,与丢失的数据量不成正比”[8]
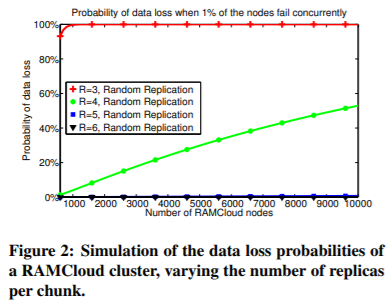
降低数据丢失概率的一个简单的替代方法是增加R。在图2中,我们计算了RAMCloud中不同复制因子下的数据丢失概率。正如我们所期望的,增加复制因子可以提高系统对相关故障的持久性。但是,在这种情况下,将复制因子从3增加到4似乎不能提供足够的可靠性(笔者,因为宕机两个节点还是会使得set失效,这与R=3一致)。为了在当前系统中可靠地支持数千个节点,复制因子必须至少为5。使用R=5会严重影响系统的性能,并几乎使存储成本增加一倍。
本文的目标是在不改变系统基本参数的情况下,降低停电时数据丢失的概率。
3. INTUITION
如果我们单独考虑每个块,那么即使在断电的情况下,随机复制也能提供很高的持久性。例如,假设我们试图将一个块复制三次。我们随机选择三台不同的机器来作为我们的副本。如果停电导致数据中心中1%的节点发生故障,那么崩溃导致存储我们数据块的三台机器发生故障的概率只有0.0001%。
但是,现在假设系统不只是复制一个chunk,而是复制数百万个chunk(每个节点有10000个或更多chunk),并且需要确保这些chunk中的每一个都能在故障中幸存下来。尽管每个块都非常安全,但在整个集群中,一些块可能会丢失。图1演示了这种效果:在实际的数据中心配置中,如果三个节点的任意组合同时发生故障,数据丢失几乎是必然的。
我们将Copyset定义为一组不同的节点,其中包含给定块的所有副本。每个Copyset都是一个单一的失败单元,也就是说,当一个Copyset失败时,至少有一个数据块不可挽回的丢失了。增加Copyset的数量将增加相关故障下的数据丢失概率,因为故障节点至少包含一个拷贝集的概率更高(笔者:这里我的想法是一个新的chunk需要三个节点来存储数据。这三个节点在这个chunk之前可能并不包含一个copyset,但是现在有了一个新的copyset)。使用随机复制,几乎每个新复制的chunk都会创建一个不同的copyset,直到某个特定点(up to a certain point)。
3.1 Minimizing the Number of Copysets
我们面临的挑战是设计复制方案,在给定系统 designer 设置的所需 scatter width 的情况下,使copyset的数量最小化。
要了解如何生成这样的方案,请考虑以下示例。假设我们的存储系统具有以下参数:R=3、N=9和S=4。如果我们使用随机复制,则每个区块将被复制到从第一个节点之后的一组S节点中随机选择的另一个节点上。例如,如果主副本放置在节点1上,则次副本将随机放置在节点2、3、4或5上。
因此,如果我们的系统有大量的chunk,它将创建54个不同的复制集(笔者:猜测是9*( C 4 2 C_{4}^{2} C42))。
在三个节点同时发生故障的情况下,数据丢失的概率是拷贝数除以最大拷贝数(54 / C 9 3 C_{9}^{3} C93)。
现在,检查使用相同参数的替代方案。假设我们只允许系统在以下copyset上复制其数据:{1, 2, 3}, {4, 5, 6}, {7, 8, 9}{1, 4, 7}, {2, 5, 8}, {3, 6, 9}
也就是说,如果主副本放在节点3上,那么两个次副本只能随机地放在节点1和2或6和9上。请注意,使用此方案,每个节点的数据将在其他四个节点上均匀分割。新方案只创建了6个副本。现在,如果三个节点失败,数据丢失的概率是:(6 / 84)
随着N的增加,创建最少拷贝数的相对优势显著增加。例如,如果我们选择一个N=5000,R=3,S=10的系统(比如Facebook的HDFS部署),我们可以设计一个复制方案,创建大约8300个拷贝集,而随机复制将创建大约275000个拷贝集。
上述方案有两个重要特性,构成了Copyset Replication设计的基础。首先,每个Copyset 最多通过一个节点与另一个Copyset 重叠(例如,Copyset {4,5,6}和{3,6,9}的唯一重叠节点是节点6)。这样可以确保每个副本将其节点的scatter width精确地增加R−1,其次,该方案保证了Copyset平均覆盖所有节点。
我们的方案创建了两个permutations,并将它们划分为Copyset。因为每个permutations都会使scatter width增加R− 1,总scatter width为:
S = P ( R − 1 ) S = P(R − 1) S=P(R−1)
其中P是排列的数目。此方案将创建 P N R P \frac {N} {R} PRN副本集,该副本集等于: S R − 1 N R \frac {S} {R-1}\frac {N} {R} R−1SRN。
对于S< N 2 \frac {N} {2} 2N的值,通过随机复制创建的拷贝集数为: N ∗ C S R − 1 N*C_{S}^{R-1} N∗CSR−1。此数字等于主副本节点数乘以从一组S节点中选择出R-1个辅助副本节点的组合。当S接近N时,Copyset的数量接近总set数,即等于 C N R − 1 C_{N}^{R-1} CNR−1。
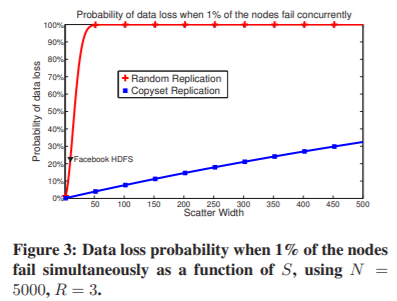
总之,在最小复制方案中,Copyset的数量随S线性增长,而随机复制以 S R − 1 S^{R-1} SR−1的趋势创建Copyset。图3展示了随机复制和拷贝集复制(我们在本文中开发的方案)之间的数据丢失概率随时间的变化。
4. DESIGN
在本节中,我们将介绍一种新的复制技术的设计,即Copyset Replication,它在scatter width和Copysets数量之间提供了一种近乎最佳的平衡。
正如我们在前面的部分中看到的,存在复制方案,它们可以在S的线性增长中实现对Copysets的线性增加。然而,设计覆盖所有节点的non-overlapping copysets最佳方案并不总是简单的。在某些情况下,特定值为N、R和S,甚至表明不存在这种非重叠方案[18,19]。有关更详细的理论讨论,请参阅第7.1节。
因此,我们不使用最优方案,而是提出了一种在实际环境中接近最优且易于实现的复制方案。Copyset Replication随机生成排列,并将每个permutation拆分为copysets。我们将证明,只要S比系统中的节点数小得多,这个方案就有可能生成最多有一个重叠节点的副本集。
复制有两个阶段: Permutation 和 Replication。 Permutation 阶段离线执行,而 Replication阶段在每次需要复制chunk时执行。
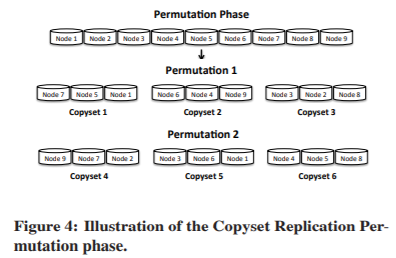
图4说明了Permutation 阶段。在这个阶段,我们通过随机排列系统中的节点来创建几个Permutation 。我们创建的Permutation数量依赖于S,并且等于 P = S R − 1 P=\frac {S} {R-1} P=R−1S 。如果这个数字不是整数,我们选择向上取整。如图所示,每个 Permutation 都被连续地拆分为多个Copyset。Permutation 可以完全随机生成,或者我们可以添加额外的约束,比如将同一机架中的节点限制在同一 Copyset 中,或者添加网络和容量约束。在我们的实现中,我们通过简单地重新排列Permutation 直到满足所有约束条件,来防止来自同一机架的节点被放置在同一 Copyset 中。
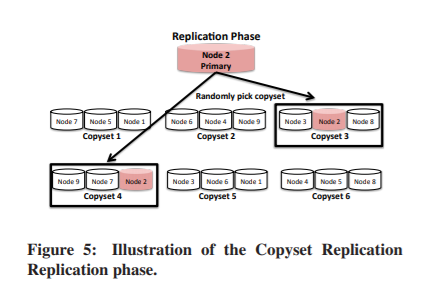
在 Replication 阶段(如图5所示),系统将副本放在 Permutation 阶段生成的一个copyset上。主要(primary)副本可以放置在系统的任何节点上,而其他(secondary )副本则放置在随机选择的包含第一个节点的副本集的节点上。(笔者:其实就是比如一个数据可以随机选择在哪个节点中,然后再随机选择一个包含此节点的copyset放置secondary副本)
Copyset Replication与第一个复制副本的数据放置策略无关。不同的存储系统在选择其主副本节点时有一定的限制。例如,在HDFS中,如果本地机器有足够的容量,它会在本地存储主副本,而RAMCloud使用一种基于Mitzenmacher随机负载平衡的算法来选择其主副本[23]。Copyset Replication的唯一要求是,块的secondary副本始终放置在包含主副本节点的其中一个拷贝集上。这限制了通过Copyset Replication创建的Copyset 的数量。
4.1 Durability of Copyset Replication
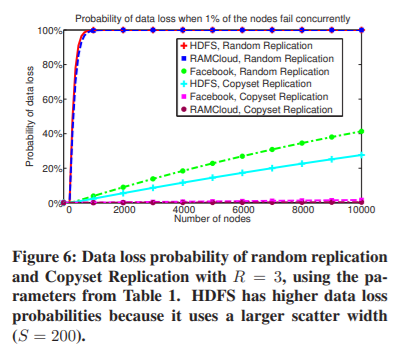
图6是本文的中心图。用RAMCloud、HDFS和Facebook(Facebook改进的HDFS)三个副本比较了Copyset Replication和随机复制的数据丢失概率。对于HDFS和Facebook,我们为copyset Replication和随机复制绘制了相同的S值。在RAMCloud的特殊情况下,由于磁盘节点是从集群中所有节点的内存中恢复的,而不是从其他磁盘中恢复的,因此在我们的方案中,节点的恢复时间与排列数无关。因此,具有最小 S = R − 1 S=R-1 S=R−1的Copyset Replication(使用P=1)实际提供的节点恢复时间与使用较大的S值相同(笔者:这里的原因是一般数据恢复的过程与S有关,而P与S有关。数据恢复的过程与S有关是因为S越大某个节点宕机时并行数据恢复的速度就越快)。因此,我们使用P=1绘制Copyset Replication的数据概率。
我们可以做一些有趣的观察。Copyset Replication 将RAMCloud和Facebook在断电情况下的数据丢失概率降至接近零,但并没有显著改善HDFS。对于断电的5000节点集群,Copyset Replication 将RAMCloud的数据丢失概率从99.99%降低到0.15%。对于Facebook来说,这一概率从22.8%降至0.78%。在HDFS的情况下,由于分散宽度大(S=200),所以Copyset Replication 显著地改善了数据丢失的概率,但这还不足以使数据丢失的概率接近于零。
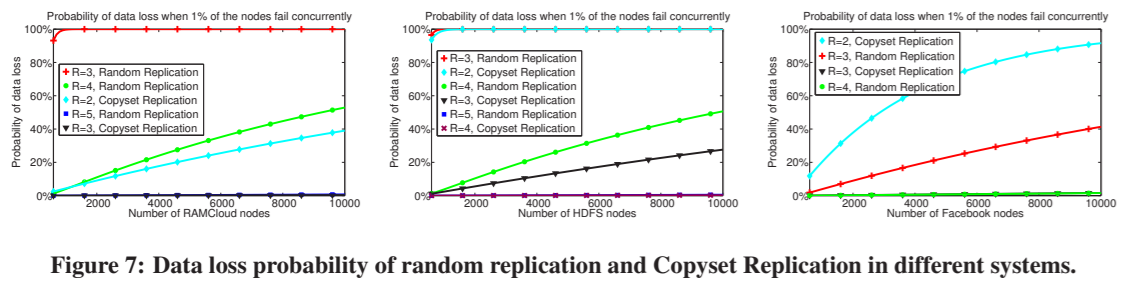
图7描述了5000节点RAMCloud、HDFS和Facebook集群的数据丢失概率。我们可以观察到,Copyset Replication 导致的数据丢失概率的降低相当于增加了副本的数量。例如,在RAMCloud的情况下,如果系统使用具有3个副本的Copyset Replication,则与具有5个副本的随机复制相比,它具有更低的数据丢失概率。类似地,在Facebook集群中,使用3个副本的Copyset Replication与使用4个副本的随机复制具有相同的数据丢失概率。
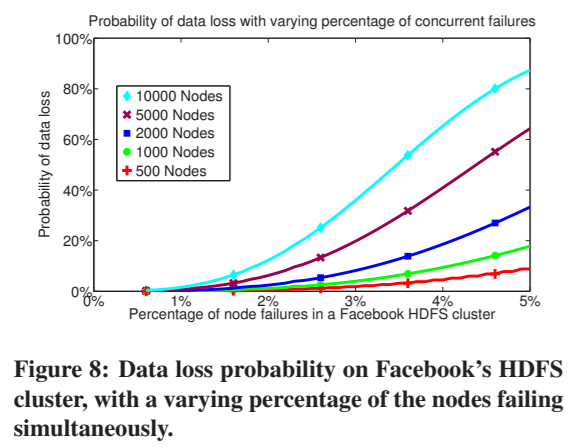
在数据中心观察到的同时发生故障的典型数量是集群中节点的0.5-1%[25]。图8描述了Facebook的HDFS系统中数据丢失的概率,因为我们将同时发生的故障的百分比增加到远远超过报告的1%。请注意,Facebook通常在每个集群1000-5000个节点的范围内运行(例如,见表1)。对于这些集群大小,即使在2%的节点同时发生故障的情况下,Copyset Replication也很有可能防止数据丢失。
4.2 Optimality of Copyset Replication
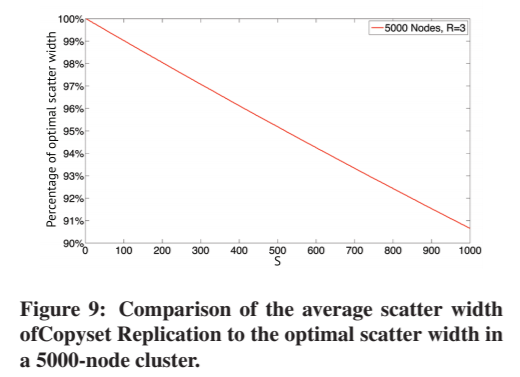
Copyset Replication 不是最佳的,因为它不能保证所有的Copyset 最多有一个重叠节点。换句话说,它不能保证每个节点的数据将被精确的复制到其他S个节点上。图9描述了一个monte-carlo模拟,该模拟比较了在5000个节点的集群中,如果所有Copyset都不重叠,则Copyset实现的平均scatter width与最优S的函数关系。
该图表明,当S远小于N时,Copyset Replication 的优化率超过90%。对于分别使用S=2和S=10的RAMCloud和Facebook,Copyset 几乎是最优的。对于HDFS,我们使用S=200,在本例中,Copyset Replication 为每个节点提供了平均98%的最佳带宽,也就是S=192。
4.3 Expected Amount of Data Lost
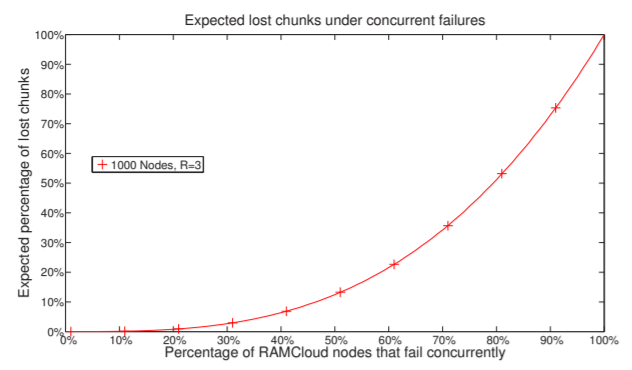
Copyset Replication 会将数据丢失的概率与每次事件中丢失的数据量进行权衡。无论复制策略如何,预期的数据丢失量都保持不变。图10显示了丢失的数据量占集群中数据的百分比。
因此,部署Copyset Replication 的系统设计人员应该期望经历更少的数据丢失事件。但是,这些事件中的每一个都会丢失大量数据。在极端情况下,如果我们像RAMCloud那样使用S=2的Copyset复制,那么每次数据丢失事件都会丢失整个节点的数据。
5. EVALUATION
Copyset Replication 是一种通用的,可伸缩的复制方案,可以在各种数据中心存储系统上实施,并且可以调整为任意 scatter width。 在本节中,我们将介绍在HDFS和RAMCloud中实现 Copyset Replication 的方法。 我们还提供了有关“Copyset Replication ”对两个系统性能的影响的实验结果。
5.1 HDFS Implementation
由于现有的HDFS复制代码非常抽象,因此在HDFS上实施Copyset Replication相对简单。 Copyset Replication完全在HDFS NameNode上实现,该HDFS NameNode充当中央目录并管理整个集群的复制。
集群创建阶段将会运行 Copyset Replication 的 permutation阶段,用户指定scatter width和系统中的节点数。 将所有节点添加到群集后,NameNode通过随机排列节点列表来创建copyset。 如果生成的排列违反任何机架或网络约束,则该算法将随机重新组合新permutation。
在 Replication 阶段,使用默认的HDFS复制选择主副本。
5.1.1 Nodes Joining and Failing
在我们的实现中节点可以自发的加入集群或者宕机,我们的实现需要处理这两种情况。
当新节点加入集群时,NameNode会随机创建 S R − 1 \frac {S} {R-1} R−1S个包含它的新Copyset。只要scatter width远小于系统中节点的数量,此方案仍将接近最佳状态(几乎所有copyset都不重叠)。 不利的一面是,有一些节点的实际scatter width可能比所需scatter width的稍高,这会产生比必要的更多的Copyset。
当节点发生故障时,对于每个copyset,我们将其替换为随机选择的节点。 例如,如果原始副本集包含节点{1、2、3},并且节点1发生故障,我们将原始copyset中的数据副本重新复制到一个新的随机选择的节点。 和以前一样,只要scatter width显著小于节点数,此方法就会创建不重叠的copyset。
5.2 HDFS Evaluation
我们在39个HDFS节点的群集上评估了Copyset Replication的实现,这些群集具有100 GB的SSD存储和1 GB的以太网网络。 表2比较了使用“Copyset Replication”和“随机复制”的单个节点的恢复时间。 我们每次恢复运行了五次。
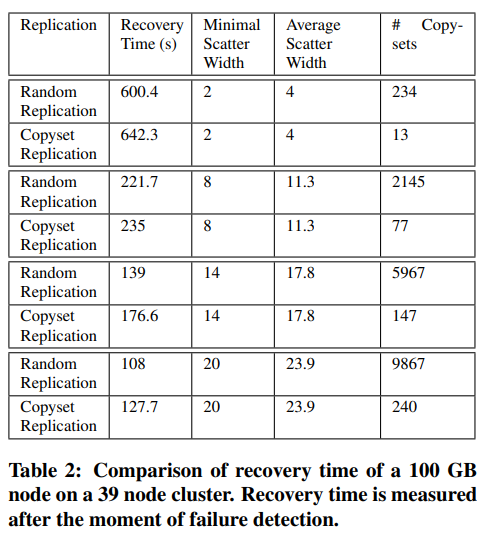
如前几节所述,只要S明显小于N,Copyset Replication就会有很少的重叠Copyset。但是,由于我们的实验使用了较小的N值,大量重叠的Copyset导致部分节点没有足够的scatter width。 为了解决此问题,我们的“Copyset Replication”实现会生成其他permutation,直到系统达到其所有节点的最小scatter width为止。 这些排列创建了更多的copyset。 我们计算了不同副本的平均数量。 结果表明,即使存在额外的排列,“Copyset Replication”的副本集仍比随机复制少几个数量级。
为了规范Copyset复制和随机复制之间的scatter width,当我们使用随机复制恢复数据时,我们使用了Copyset Replication获得的平均分散宽度。
结果表明,与随机复制相比,Copyset Replication 的恢复时间开销约比随机复制高5-20%。 这是我们集群较小时的数据。 群集的小尺寸导致某些节点比其他节点成为更多副本集的成员,这意味着它们有更多数据要恢复并延迟了总体恢复时间。 如果我们使用实际的大规模HDFS群集(数百到数千个节点),则不会发生此问题。
5.2.1 Hot Spots
随机复制的主要优点之一是,它可以通过在随机的一组节点上均匀分散其数据来防止特定节点成为“热点”。 如果主节点被读取请求所淹没,则客户端可以从存储辅助副本的节点读取其数据。(笔者,即写请求会被分发到不同的copyset,读请求就被散开到scatter width个节点上读取数据了)
我们将负载 L ( i , j ) L(i,j) L(i,j)定义为存储为节点 j j j 中的辅助副本的节点 i i i 数据的百分比(as the percentage of node i’s data that is stored as a secondary replica in node j)。 例如,如果S = 2并且节点1将其所有数据复制到节点2和3,则 L ( 1 , 2 ) = L ( 1 , 3 ) = 0.5 L(1,2)= L(1,3)= 0.5 L(1,2)=L(1,3)=0.5,即,节点1的数据在节点2和3之间平均分配。
我们将负载平均分配到系统中的节点上的次数越多,系统对热点的免疫力就越大。 注意,负载是scatter width的函数。 如果我们增加scatter width,则负载将更均匀地分布。 我们期望属于节点 i i i 的副本集的节点的负载为 d f r a c 1 S dfrac1S dfrac1S。 由于“副本集复制”保证了与随机复制的scatter width相同,因此它也应均匀分散负载,并且不受scatter width足够大的热点的影响。
为了测试Copyset Replication负载,我们在R = 3的5000个节点的HDFS集群中运行了数据复制的蒙特卡洛模拟。
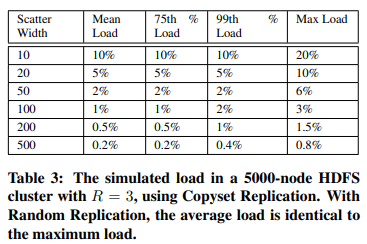
表3列出了我们在蒙特卡洛实验中测得的负载。 由于我们有大量带有随机复制的块,因此平均负载几乎与最坏情况的负载相同(Since we have a very large number of chunks with random replication,不是测Copyset Replication吗??)。 通过Copyset Replication,仿真显示百分之99的负载是平均负载的1-2倍,最大负载是平均负载的1.5-4倍。Copyset Replication会产生更高的最坏情况负载,因为 permutation 阶段可能会产生一些具有重叠的副本集(笔者:可以看出scatter width越高,平均负载就越低)。
因此,如果系统的目标是即使在最坏的情况下使用Copyset Replication来防止热点,系统设计人员也应相应地增加系统的scatter width。
5.3 Implementation of Copyset Replication in RAMCloud
(笔者:其实我并不太了解RAMCloud的架构,所以并不清楚这里所谓的并行恢复到底时怎么实现的,所以这里的翻译可能会没有感情)
RAMCloud上的Copyset Replication的实现与HDFS相似,但有一些小差异。 与HDFS实施相似,大多数代码在RAMCloud的协调器上实施,该协调器既充当主目录节点,又将节点分配给副本。
在RAMCloud中,数据的主副本保存在主服务器中,该服务器将数据保存在内存中。 每个主服务器在三个不同的备份服务器上复制其块,这些备份服务器将数据永久存储在磁盘上。
RAMCloud上的Copyset Replication实现仅支持最小scatter width(S = R − 1 = 2)。 我们选择了最小的分散宽度,因为它不会影响RAMCloud的节点恢复时间,因为备份数据是从主节点中恢复的,这些数据分散在整个群集中。
RAMCloud和HDFS实施之间的另一个区别是,我们如何处理加入群集的新备份以及备份失败。 由于每个节点都是单个copyset的成员,因此如果协调器找不到三个节点来形成完整的copyset,则新节点将保持空闲状态,直到有足够的节点来形成copyset为止。
当新备份加入集群时,协调器将检查是否有三个未分配给copyset的备份。 如果存在,则协调器将这三个备份分配给一个copyset。
为了保留S = 2,每次备份节点发生故障时,我们都会重新复制其整个copyset。 由于备份不支持正常的读写,因此不会影响系统的延迟。 此外,由于实际上是从主数据库中并行恢复备份,因此重新复制整个组不会显着影响恢复延迟。 但是,此方法确实会在恢复过程中增加磁盘和网络带宽。
5.4 Evaluation of Copyset Replication on RAMCloud
我们将三种情况下的Copyset Replication与随机复制的性能进行了比较:正常RAMCloud客户端操作,单个主恢复和单个备份恢复
不出所料,我们无法衡量在正常的RAMCloud操作上使用Copyset Replication的任何开销。 我们还发现它不会影响主恢复,而备份恢复的开销却比我们预期的要高。 我们提供如下结果:
5.4.1 Master Recovery
RAMCloud的主要目标之一是在大约1-2秒内完全恢复主数据库,以使应用程序受到的干扰最小。 为了测试主恢复,我们运行了一个包含39个备份节点和5个主节点的集群。 我们手动使其中一台主服务器崩溃,并测量了RAMCloud恢复数据所需的时间。 我们使用“副本集复制”和“随机复制”运行了该测试100次。 不出所料,在两种方案中,恢复主节点所花费的时间都没有发现任何差异。
但是,当我们使用10个备份而不是39个备份再次运行基准测试时,我们发现Copyset Replication花费的时间比随机复制方案多11%来恢复主节点。 由于Copyset Replication将备份分成三个一组的事实,因此只能利用群集中10个节点中的9个。 仅当我们在非常小的群集上使用的备份数量不是三个备份的倍数时,才会发生这种开销。 由于我们假设RAMCloud通常部署在大型集群上,因此主恢复开销可以忽略不计。
5.4.2 Backup Recovery
为了评估副本集复制在备份恢复上的开销,我们进行了一个实验,其中一个备份在具有39个主数据库和72个备份的RAMCloud群集上崩溃,总共存储了33 GB的数据。 表4给出了结果。 由于主服务器以并行方式复制数据,因此与随机复制相比,使用 Copyset Replication 从备份故障中恢复仅花费51%的时间。 如预期的那样,我们的实施大约使恢复期间重新复制的数据量增加了三倍。 请注意,此额外开销不是Copyset Replication所固有的,它是由我们的设计选择导致的,即严格保留最小的分散宽度,但以更高的备份恢复开销为代价。
6. DISCUSSION
本节讨论编码方案如何与副本集数量相关,以及 Copyset Replication 如何优雅的简化存储集群的正常断电情况。
6.1 Copysets and Coding
某些存储系统(例如GFS,Azure和HDFS)使用编码技术来降低存储成本。 这些技术通常不会影响由于同时发生故障而导致数据丢失的可能性。
代码通常被设计为压缩数据而不是增加其可用性(durability)。 如果编码数据分布在非常多的副本集上,则多个同时发生的故障仍将导致数据丢失。
实际上,现有的存储系统奇偶校验代码实现不会显着减少副本集的数量,因此不会影响数据丢失的状况。 例如,HDFS-RAID [1,11]实现在RAID 5和镜像方案中对5个块的组进行编码,这将不同副本集的数量减少了5倍,而将副本集的数量减少了5倍。 降低了数据丢失的可能性, Copyset Replication 创建的 Copyset 仍比此方案少两个数量级。 因此,在断电的情况下,具有随机复制功能的HDFSRAID仍然很可能丢失数据。
6.2 Graceful Power Downs
数据中心运营商需要定期关闭集群的一部分电源[4、10、13]。 掉电用于节省非高峰时间的电力资源,或进行受控的软件和硬件升级。
当部分存储集群断电时,预期中每个chunk的至少一个副本将保持在线状态。 但是,随机复制会大大增加断电的复杂性,因为如果我们关闭大量计算机的电源,则给定chunk的所有副本很有可能会宕机。 实际上,这些概率与我们用来计算数据丢失的概率完全相同。 先前的几项研究已深入探讨了数据中心的功耗下降情况[17、21、27]。
如果我们限制Copyset Replication以使用最少数量的Copyset (即使用S = R − 1的Copyset Replication),则执行受控的集群掉电很简单。 由于此版本的 Copyset Replication 为每个节点分配一个Copyset ,因此,只要每个Copyset 的一个成员保持在线状态,我们就可以安全地关闭其余节点的电源。 例如,在此版本的 Copyset Replication 中使用三个副本的集群可以有效地关闭三分之二的节点。
(笔者:可是在S较大的时候,copyset还是很难做到优雅关闭,因为很难找到使得数据全部保存的待删除数据集,这里我的想法如下:建立一个有向图,a指向b代表b为a 的副本,这样利用已有copyset的数据可以建图,我们的目标就是删除最多的节点,目前想到比较暴力的方法就是以copyset为单位进行删除,第一次删除R-1个节点,后面每一次遍历剩余的copyset,找到删除哪个节点不会使得任意一组数据丢失,设N为copyset总数,时间复杂度为O( N 2 N^2 N2),当然如果不遍历的话记录每个节点关联的所有copyset就可以,时间复杂度为 S R − 1 ∗ N \frac {S} {R-1}*N R−1S∗N。
7. RELATED WORK
相关工作分为三类。 首先,实现最佳scatter width的复制方案与数学领域相关,该领域称为组合设计理论,该理论可以追溯到19世纪。 我们将简要概述并提供此类设计的一些示例。 其次,已经在DHT系统的背景下研究了副本放置。 第三,几个数据中心存储系统已采用各种解决方案来减轻由于并发节点故障而导致的数据丢失。
7.1 Combinatorial Design Theory
(笔者:感兴趣的同学可以查阅原文,不过我想很少有人可以看到这句话,就把这句话当个彩蛋,第一个找到这个彩蛋的同学可以留言,一杯奶茶送上~~)
7.2 DHT Systems
有几种先前的系统在DHT系统的背景下探索数据放置对数据可用性的影响。
Chun等人发现跨大型“节点”随机复制数据会增加多个节点同时失败时数据丢失的可能性,他们使用DHT复制方案Carbonite来研究不同范围大小的影响,Yu等人分析当客户端从服务器请求多个可能同时失败的对象时,不同复制策略的性能。他们提出了一种称为“Group”的DHT复制方案,该方案通过根据主副本的密钥按特定顺序放置次副本来限制副本在某些组上的放置,类似地,Glacier限制了副本的随机散布。 通过将每个副本限制为键的哈希空间中的等距点来实现副本。
这些研究都没有关注数据丢失概率与scatter width之间的关系,也没有针对不同的分散宽度约束提供最佳方案。
7.3 Data Center Storage Systems
Facebook专有的HDFS实现将副本放置在较小的组中,以防止并发故障[2,5]。 同样,Sierra将块随机放置在受约束的组中,以支持灵活的节点断电和数据中心功率比例[27]。 正如我们之前讨论的,这两种方案都在受约束的节点组中使用随机复制,与具有相同分散宽度的“复制集复制”相比,它们生成的复制集数量级要高得多,因此在相关故障下数据丢失的可能性要高得多。
来自Google的文章分析了GFS集群上的各种故障丢失情况,并提出了地理复制作为防止大规模并发节点故障下数据丢失的有效技术。 在地理位置分散的站点之间进行地理复制是一种确保在断电情况下数据持久性的故障保护方法。 但是,并非所有存储提供商都具有支持地理复制的功能。 此外,即使对于具有地理复制功能的数据中心运营商(如Facebook和LinkedIn),由于需要查找或重新计算数据,在单个站点上丢失数据仍然会产生较高的固定成本。 此固定成本与丢失的数据量不成比例[8,22]。
8. ACKNOWLEDGEMENTS
我们要感谢David Gal,Diego Ongaro,Israel Cidon,K.V.Rashmi和Shankar Pasupathy提出了宝贵的反馈意见。 我们还要感谢我们的shepherd, Bernard Wong和匿名审阅者的评论。 Asaf Cidon得到了Leonard J. Shustek Stanford研究生奖学金的支持。 这项工作得到了美国国家科学基金会的资助(第0963859号)和STARnet(由MARCO和DARPA赞助的半导体研究公司计划)的支持。
这篇关于Copysets: Reducing the Frequency of Data Loss in Cloud Storage的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








