本文主要是介绍基于 TiDB v6.0 部署两地三中心,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者: 边城元元 原文来源: https://tidb.net/blog/91a8cbdf
一、背景
项目需要做两地三中心的架构,目前只考虑数据存储层的两地三中心,对 TiDB 了解的比较多一点,就尝试着使用 TiDB 做两地三中心的方案;主要用到的 Placement Rules in SQL 特性。Placement Rules in SQL 用于通过 SQL 接口配置数据在 TiKV 集群中的放置位置。通过该功能,用户可以将表和分区指定部署至不同的地域、机房、机柜、主机。适用场景包括低成本优化数据高可用策略、保证本地的数据副本可用于本地 Stale Read 读取、遵守数据本地要求等。因为要考虑到全球化的因素,正好 TiDB 也可以开启 Follower Read,很期待这次的尝试!
二、准备知识
2.1 两地三中心
通常的两地三中心是 2 个城市 3 个中心是指生产中心、同城容灾中心、异地容灾中心
2.2 全球化思路
在全球目标地数据中心增加对应的 Region 副本,采用 Follower Read 从就近的副本读数据。
2.3 架构详解
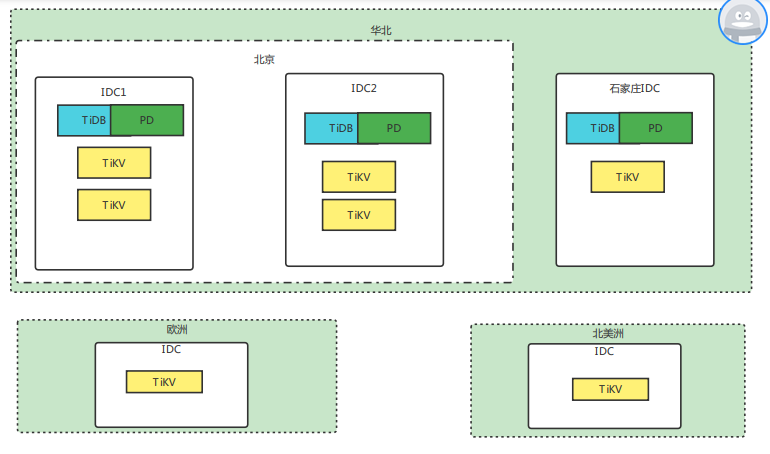
2.3.1 架构图
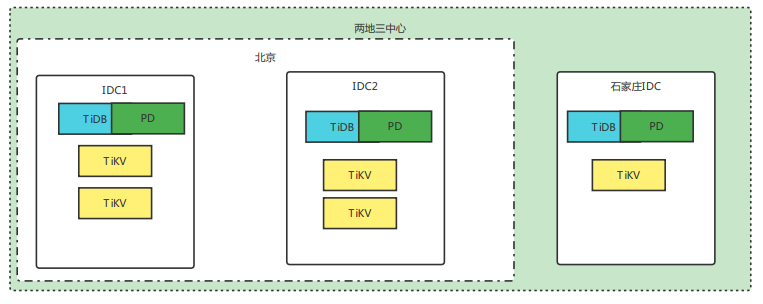
这里是 5 个 TiKV 副本的集群节点说明参考下表:
全部 TiKV 节点放置规划表
2.3.2 Labels 设计
area:northern,southern,europe,america
dc:bj1,bj2,sjz,hk1,hk2,shzh
rack:ssd,hhd
host:host编号
replication.location-labels: ["area","dc","rack","host"]
2.3.3 参数配置优化
- 启用 TiKV gRPC 消息压缩。server.grpc-compression-type: gzip
<!---->
-
调整 PD balance 缓冲区大小,提高 PD 容忍度 schedule.tolerant-size-ratio: 20.0
调整 PD balance 缓冲区大小,提高 PD 容忍度,因为 PD 会根据节点情况计算出各个对象的 score 作为调度的依据,当两个 store 的 leader 或 Region 的得分差距小于指定倍数的 Region size 时,PD 会认为此时 balance 达到均衡状态。 参考: https://docs.pingcap.com/zh/tidb/v6.0/three-data-centers-in-two-cities-deployment# 两地三中心部署
2.4 安装集群
2.4.1 集群拓扑
cluster115.yaml
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:user: "tidb"ssh_port: 22deploy_dir: "/tidb-deploy"data_dir: "/tidb-data"
# # Monitored variables are applied to all the machines.
monitored:node_exporter_port: 9100blackbox_exporter_port: 9115server_configs:tidb:log.slow-threshold: 300binlog.enable: falsebinlog.ignore-error: falsetikv:# server.grpc-concurrency: 4# raftstore.apply-pool-size: 2# raftstore.store-pool-size: 2# rocksdb.max-sub-compactions: 1# storage.block-cache.capacity: "16GB"# readpool.unified.max-thread-count: 12server.grpc-compression-type: gzipreadpool.storage.use-unified-pool: falsereadpool.coprocessor.use-unified-pool: truepd:schedule.leader-schedule-limit: 4schedule.region-schedule-limit: 2048schedule.replica-schedule-limit: schedule.tolerant-size-ratio: 20.0replication.location-labels: ["area","dc","rack","host"]
pd_servers:- host: 10.0.2.15# ssh_port: 22# name: "pd-1"client_port: 2379# peer_port: 2380
tidb_servers:- host: 10.0.2.15
tikv_servers:- host: 10.0.2.15port: 20160status_port: 20180config:server.labels: area: northerndc: bj1rack: r1host: host100
- host: 10.0.2.15port: 20161status_port: 20181config:server.labels: area: northerndc: bj1rack: r2host: host101- host: 10.0.2.15port: 20162status_port: 20182config:server.labels: area: northerndc: bj2rack: r1host: host102- host: 10.0.2.15port: 20163status_port: 20183config:server.labels: area: northerndc: bj2rack: r2host: host103- host: 10.0.2.15port: 20164status_port: 20184config:server.labels: area: northerndc: sjzrack: r1host: host104monitoring_servers:- host: 10.0.2.15
grafana_servers:- host: 10.0.2.15
alertmanager_servers:- host: 10.0.2.15
2.4.2 离线安装 TiDB v6.0
参考 https://tidb.net/blog/87a38392# 离线安装TiDBV6.0 https://tidb.net/blog/af8080f7#Cluster111
#离线安装: https://pingcap.com/zh/product-community/#TiDB 6.0.0-DMR
#1)下载安装包 tidb-community-server-v6.0.0-linux-amd64.tar.gz 2)下载tookit tidb-community-toolkit-v6.0.0-linux-amd64.tar.gz
mkdir -p /usr/local0/webserver/tidb/
cd /usr/local0/webserver/tidb/
tar -zxvf tidb-community-toolkit-v6.0.0-linux-amd64.tar.gz
tar -zxvf tidb-community-server-v6.0.0-linux-amd64.tar.gz
cd ./tidb-community-server-v6.0.0-linux-amd64/
sh local_install.sh
source /root/.bash_profile
tiup update cluster
tiup cluster list
# 检测环境配置并尝试修正
tiup cluster check ./cluster115.yml --user root -p --apply
# 安装cluster115
tiup cluster deploy cluster115 v6.0.0 ./cluster115.yml --user root -p
# 启动集群
tiup cluster start cluster115
tiup cluster display cluster115
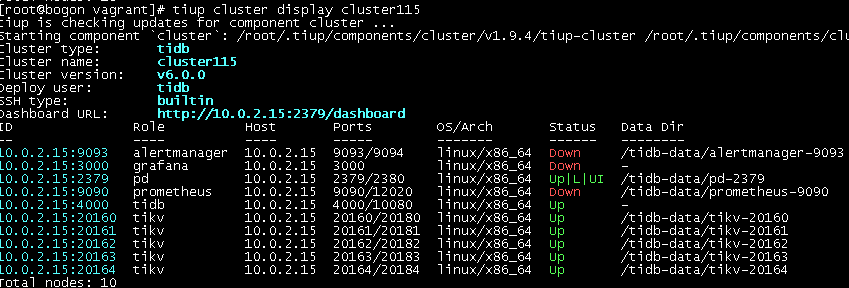
2.4.3 连接 TiDB
use test;
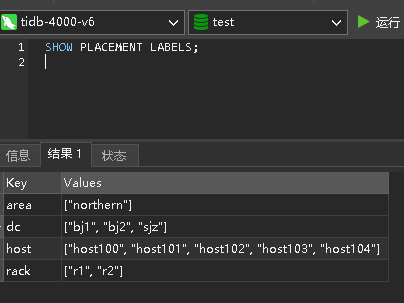
SHOW PLACEMENT LABELS;
三、设置规则
3.1 单库两地三中心
3.1.1 架构图
场景说明:
-
某比赛历史数据排名相关( 通常是本赛季之前的要较大时间跨度的数据需求场景)
-
数据要求全球化全量数据
3.1.2 设置策略
策略描述:
- leader 节点在北京的 2 个IDC中的一个;
- 一共 5 个副本 其中有 4 个副本(包括 leader )在北京的 2 个 IDC 中;
- 异地数据中心石家庄 IDC 有一个副本
-- 创建规则 使用高级放置选项时 label 标签不需要必须设置 region 层级标签。
CREATE PLACEMENT POLICY northernpolicy LEADER_CONSTRAINTS='[+area=northern,-dc=sjz]' FOLLOWER_CONSTRAINTS='{"+area=northern,-dc=sjz": 4,+dc=sjz: 1}';
3.1.3 建立库表
CREATE DATABASE `crm` /*!40100 DEFAULT CHARACTER SET utf8mb4 */ ;-- 注意:更改默认的放置规则,但更改不影响已有的表。
ALTER DATABASE crm PLACEMENT POLICY=northernpolicy;
use crm;
CREATE TABLE `m_cust_org` (`cust_id` char(30) not null, `org_id` varchar(10) default null, `org_name` varchar(100) default null, `org_ii_id` varchar(10) default null, `org_ii_name` varchar(100) default null, `org_i_id` varchar(10) default null , `org_i_name` varchar(100) default null, `org_level` varchar(2) default null ,`pici` bigint(20) not null default '0',PRIMARY KEY (`cust_id`) /*T![clustered_index] CLUSTERED */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='条件筛选表';
CREATE TABLE `m_cust_main` (`cust_id` char(30) not null , `cust_name` varchar(200) default null, `cert_type` varchar(13) default null, `cert_num` varchar(40) default null , `cust_type` varchar(2) default null , `sex` varchar(13) default null, `age` int(11) default null , `birth_dt` varchar(13) default null , `marriage` varchar(13) default null , `city_code` varchar(100) default null , `nation_code` varchar(100) default null ,`edu` varchar(13) default null , `ocup` varchar(100) default null , `post` varchar(20) default null , `copy_name` varchar(200) default null , `contact_addr` varchar(200) default null ,`card_level` varchar(2) default null , `service_level` varchar(2) default null ,`estimate_level` varchar(2) default null ,`mark_id` varchar(50) default null , `mark_name` varchar(255) default null , primary key (`cust_id`) /*t![clustered_index] clustered */,key `idx_m_cust_main_desc1` (`cert_type`,`cert_num`),key `idx_m_cust_main_desc_3` (`cust_name`)
) engine=innodb default charset=utf8mb4 collate=utf8mb4_bin comment='客户主表';
CREATE TABLE `m_cust_data` (`cust_id` char(30) not null , `asset` decimal(18,2) default null , `asset_mon_avg` decimal(18,2) default null ,`asset_sea_avg` decimal(18,2) default null ,`asset_yea_avg` decimal(18,2) default null ,`asset_roll_avg` decimal(18,2) default null ,`debt` decimal(18,2) default null , `dep_bal` decimal(18,2) default null , `dep_mon_avg` decimal(18,2) default null ,`dep_sea_avg` decimal(18,2) default null ,`dep_yea_avg` decimal(18,2) default null ,`nd_bal` decimal(18,2) default null , `mf_bal` decimal(18,2) default null , `fund_bal` decimal(18,2) default null , `ccard_out_amt` decimal(18,2) default null ,`ccard_bal` decimal(18,2) default null ,`ins_bal` decimal(18,2) default null , `loan_bal` decimal(18,2) default null , `loan_amt` decimal(18,2) default null , `etl_date` char(8) default null , `qszg_bal` decimal(24,2) default null , `dx_fnc_bal` decimal(24,2) default null ,`cur_dep_bal` decimal(18,2) default null ,`rep_bal` decimal(18,2) default null , `rep_avg` decimal(18,2) default null , `is_rep_beyond` char(2) default null , Primary Key (`cust_id`) /*t![clustered_index] clustered */,Key `idx_m_cust_query_desc_4` (`asset_sea_avg`,`cust_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='客户频繁更新数据表';
CREATE TABLE `m_cust_label` (
`cust_id` char(30) NOT NULL,
`cat1` int not null default 0 ,
`cat2` int not null default 0 ,
`cat3` int not null default 0 ,
`cat4` int not null default 0 ,
`cat5` int not null default 0 ,
`cat6` int not null default 0 ,
`cat7` int not null default 0 ,
`cat8` int not null default 0 ,
`cat9` int not null default 0 ,
`cat10` int not null default 0 ,
`cat11` int not null default 0 ,
`cat12` int not null default 0 ,
`cat13` int not null default 0 ,
`cat14` int not null default 0 ,
`cat15` int not null default 0 ,
`cat16` int not null default 0 ,
`cat17` int not null default 0 ,
`cat18` int not null default 0 ,
`cat19` int not null default 0 ,
`cat20` int not null default 0 ,
`cat21` int not null default 0 ,
`cat22` int not null default 0 ,
`cat23` int not null default 0 ,
`cat24` int not null default 0 ,
`cat25` int not null default 0 ,
`cat26` int not null default 0 ,
`cat27` int not null default 0 ,
`cat28` int not null default 0 ,
`cat29` int not null default 0 ,
`cat30` int not null default 0 , PRIMARY KEY (`CUST_ID`) /*T![clustered_index] CLUSTERED */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='客户检索标签';-- m_seed
drop table if exists `m_seed`;
CREATE TABLE `m_seed` (`id` int(11) NOT NULL AUTO_INCREMENT,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
truncate table m_seed;
SELECT * from m_seed;
insert into m_seed values();
-- 不连续的id 每次 【执行完后,auto_inccreaid 造成不连续】
insert into m_seed select null from m_seed;
insert into m_seed select null from m_seed;
insert into m_seed select null from m_seed;
insert into m_seed select null from m_seed;
insert into m_seed select null from m_seed;
insert into m_seed select null from m_seed;
--
insert into m_seed values();
3.1.4 验证副本分布
-- 若要查看当前 TiKV 集群中所有可用的标签,可执行
SHOW PLACEMENT LABELS;
show placement;
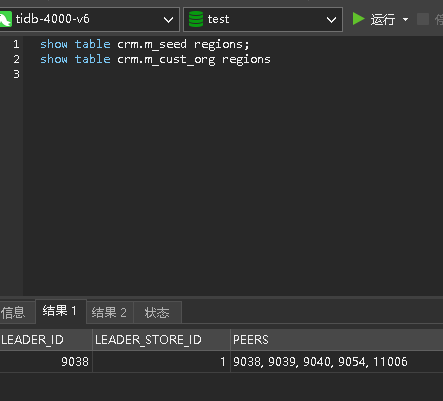
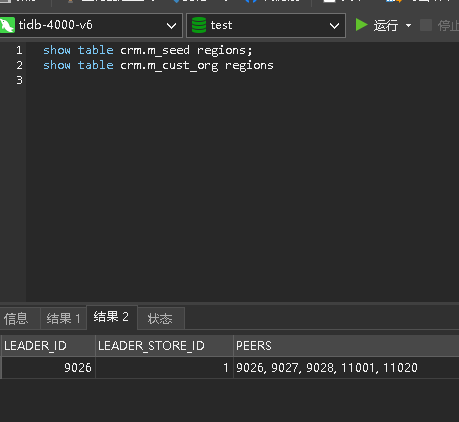
show table crm.m_seed regions;
select * from information_schema.placement_policies;
-- 1)找一个 region 进行查看 找到 regionid=9037 的记录
show table crm.m_seed regions;
-- 2)查看 region 副本的分布情况
-- 5个副本 放置规则约定sjz石家庄中心只能有一个非leader的副本
select a.region_id,a.peer_id,a.store_id,a.is_leader,b.address,b.label from INFORMATION_SCHEMA.TIKV_REGION_PEERS a
left join INFORMATION_SCHEMA.TIKV_STORE_STATUS b on a.store_id =b.store_id
where a.region_id =9037;
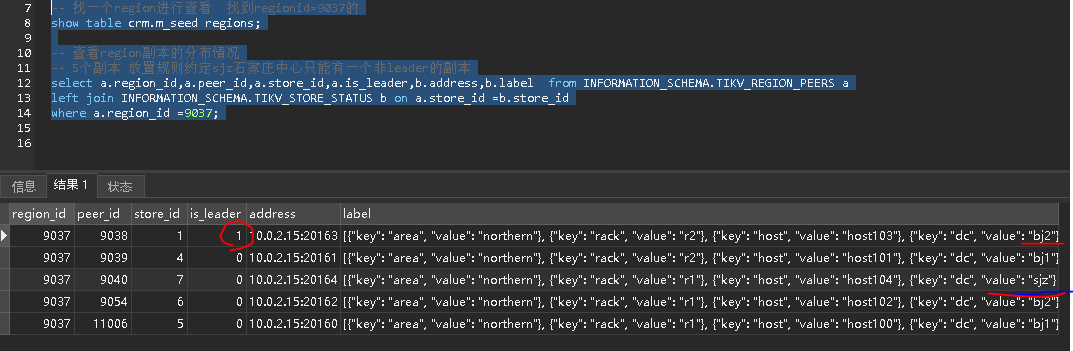
从图中看出 5 个副本,北京的 2 个数据中心有 4 个副本(包括 leader ),石家庄数据中心有一个 follow 副本,符合预期!
3.1.5 下线 leader 查看 leader 漂移情况
下线 10.0.2.15:20163 华北区 bj2(数据中心的)一个节点。
tiup cluster stop cluster115 -N 10.0.2.15:20163
-- 查看 漂移
select a.region_id,a.peer_id,a.store_id,a.is_leader,b.address,b.label from INFORMATION_SCHEMA.TIKV_REGION_PEERS a
left join INFORMATION_SCHEMA.TIKV_STORE_STATUS b on a.store_id =b.store_id
where a.region_id =9037;
注意 :这里有个问题,就是中间下线北京数据中心的一个节点的时候,这个时候执行了上面的 sql 语句,查到了把 sjz 的副作为 leader 的时刻点 ( 规则中`-dc=sjz` 即 leader 节点能不放在 sjz 数据中心 ) ,节点下线完毕后,过一会 又重新选举 bj 的数据中心的副本为 leader。这里的逻辑是不是需要优化一下。

3.1.6 增加副本放置在指定 IDC
3.1.6.1 扩容国外 TiKV 节点 拓扑如下
global:user: "tidb"ssh_port: 22deploy_dir: "/tidb-deploy"data_dir: "/tidb-data"
tikv_servers:- host: 10.0.2.15port: 20165status_port: 20185config:server.labels: area: europedc: germanyrack: r1host: host105- host: 10.0.2.15port: 20166status_port: 20186config:server.labels: area: americadc: usarack: r1host: host1063.1.5.2 扩容 TiKV
cd /usr/local0/webserver/tidb/tidb-community-server-v6.0.0-linux-amd64/
tiup cluster scale-out cluster115 /data0/webserver/tidbv6.0/cluster115-scale-out.yaml --user root -p
tiup cluster display cluster115
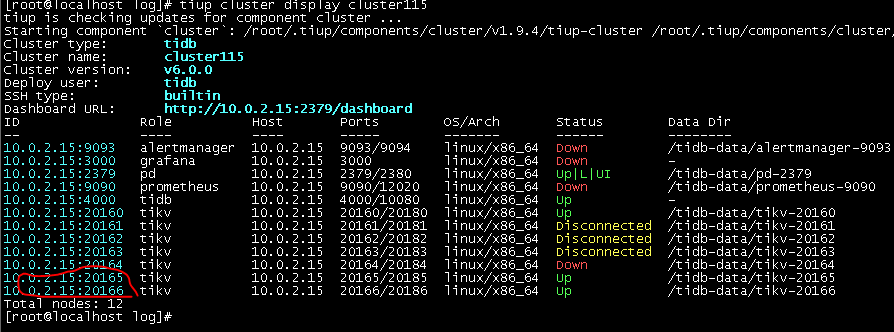
虚拟机把其他的几个 store 停掉,才起来扩容的节点
3.1.7 修改副本放置策略
- 如果修改数据库使用的新的规则,则仅对新增表使用新的规则
- 如果修改数据库原绑定的策略,则会适用已有的表
-- 在europe增加1个副本 +dc=europe: 1
-- 在america增加一个副本 +dc=america: 1
ALTER PLACEMENT POLICY northernpolicy LEADER_CONSTRAINTS="[+area=northern,-dc=sjz]" FOLLOWER_CONSTRAINTS='{"+area=northern,-dc=sjz": 4,+dc=sjz: 1,+dc=europe: 1,+dc=america: 1}';
3.1.8 增加副本放置在指定 IDC 后的验证副本数
-- 若要查看当前 TiKV 集群中所有可用的标签,可执行
SHOW PLACEMENT LABELS;
show placement;
show table crm.m_seed regions;
select * from information_schema.placement_policies;
-- 1)找一个region进行查看 找到regionid=9037的
show table crm.m_seed regions;
-- 2)查看region副本的分布情况
-- 5个副本 放置规则约定sjz石家庄中心只能有一个非leader的副本
select a.region_id,a.peer_id,a.store_id,a.is_leader,b.address,b.label from INFORMATION_SCHEMA.TIKV_REGION_PEERS a
left join INFORMATION_SCHEMA.TIKV_STORE_STATUS b on a.store_id =b.store_id
where a.region_id =9037;
3.1.9 开启 Follower read
show VARIABLES like '%tidb_replica_read%';
set tidb_replica_read = 'leader-and-follower';
set global tidb_replica_read = 'leader-and-follower';
show VARIABLES like '%tidb_replica_read%';
注意:开启 tidb_replica_read = 'leader-and-follower'; 原则上将可以实现就近读!
要想实现真正的就近读,需要使用就近的 TiDB 结合 Follower read。
3.2 多库两地三中心
crm(华北),mall(华南)
3.2.1 架构图
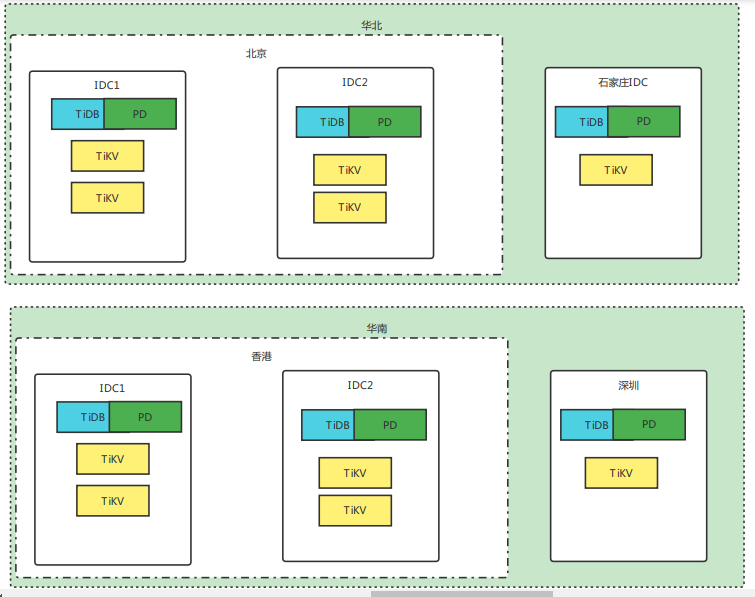
3.2.2 扩容 TiKV 节点
3.2.2.1 拓扑
global:user: "tidb"ssh_port: 22deploy_dir: "/tidb-deploy"data_dir: "/tidb-data"
tikv_servers:- host: 10.0.2.15port: 20167status_port: 20187config:server.labels: area: southerndc: hk1rack: r1host: host107- host: 10.0.2.15port: 20168status_port: 20188config:server.labels: area: southerndc: hk1rack: r2host: host108- host: 10.0.2.15port: 20169status_port: 20189config:server.labels:area: southerndc: hk2rack: r1host: host109- host: 10.0.2.15port: 20170status_port: 20190config:server.labels:area: southerndc: hk2rack: r2host: host110- host: 10.0.2.15port: 20171status_port: 20191config:server.labels:area: southerndc: shzhrack: r1host: host111
3.2.2.2 扩容
cd /usr/local0/webserver/tidb/tidb-community-server-v6.0.0-linux-amd64/
tiup cluster scale-out cluster115 /data0/webserver/tidbv6.0/cluster115-scale-out-mall.yaml --user root -p
tiup cluster display cluster115
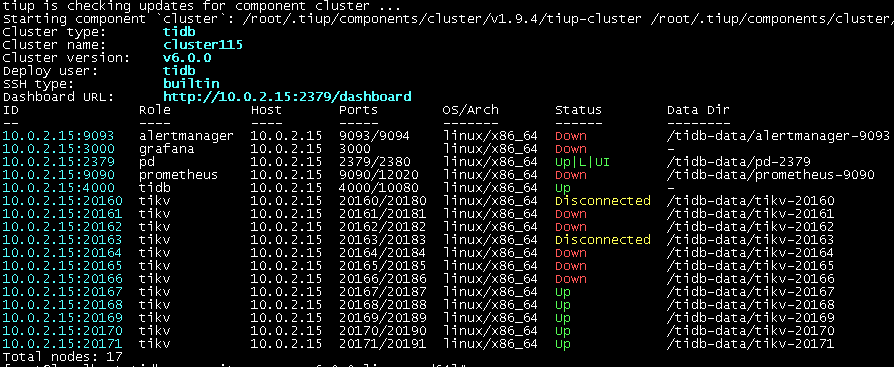
3.2.3 设置策略
策略描述:
- leader 节点在香港的 2 个IDC中的一个;
- 一共 5 个副本 其中有 4 个副本(包括 leader )在香港的 2 个 IDC 中;
- 异地数据中心深圳 IDC 有一个副本
-- 创建规则 使用高级放置选项时 label 标签不需要必须设置 region 层级标签。
CREATE PLACEMENT POLICY southernpolicy LEADER_CONSTRAINTS='[+area=southern,-dc=shzh]' FOLLOWER_CONSTRAINTS='{"+area=southern,-dc=shzh": 4,+dc=shzh: 1}';
3.2.3 建立库表
CREATE DATABASE `mall` /*!40100 DEFAULT CHARACTER SET utf8mb4 */ ;-- 注意:更改默认的放置规则,但更改不影响已有的表。
ALTER DATABASE mall PLACEMENT POLICY=southernpolicy;
use mall;
CREATE TABLE `user` (`id` int(11) NOT NULL AUTO_INCREMENT,`username` varchar(100) COLLATE utf8mb4_bin NOT NULL COMMENT '用户帐号',`name` varchar(100) COLLATE utf8mb4_bin NOT NULL COMMENT '用户姓名',`password` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '密码',`status` tinyint(1) NOT NULL COMMENT '1:启用 0: 停用',`is_deleted` tinyint(1) NOT NULL DEFAULT '0' COMMENT '1:删除 0: 未删除',`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',`edit_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',`creator` varchar(32) COLLATE utf8mb4_bin DEFAULT 'sys',`editor` varchar(32) COLLATE utf8mb4_bin DEFAULT 'sys',PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */,UNIQUE KEY `index_uk` (`username`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
3.2.4 验证策略应用情况
SHOW PLACEMENT LABELS;
show placement;
show table crm.m_seed;
select * from information_schema.placement_policies;
-- 华北 region 分布
-- 1)找一个 region 进行查看 找到regionid=9037的
show table crm.m_seed regions;
-- 2)查看 region副本的分布情况
select a.region_id,a.peer_id,a.store_id,a.is_leader,b.address,b.label from INFORMATION_SCHEMA.TIKV_REGION_PEERS a
left join INFORMATION_SCHEMA.TIKV_STORE_STATUS b on a.store_id =b.store_id
where a.region_id =9037;
-- mall 库的 region 分布
-- 注意替换这里的regionid
-- 3 查找一个mall.user的region
show table mall.user regions;
-- 4 查看 region 的分布
select a.region_id,a.peer_id,a.store_id,a.is_leader,b.address,b.label from INFORMATION_SCHEMA.TIKV_REGION_PEERS a
left join INFORMATION_SCHEMA.TIKV_STORE_STATUS b on a.store_id =b.store_id
where a.region_id =9037;
3.3 目前已知 Placement Rules in SQL 特性存在以下限制
- 临时表不支持放置规则。
- 设置
PRIMARY_REGION和REGIONS时允许存在语法糖。但在未来版本中,我们计划为PRIMARY_RACK、PRIMARY_ZONE和PRIMARY_HOST添加变体支持,见 issue #18030 。 - 不能通过放置规则语法配置 TiFlash 副本。
- 放置规则仅保证静态数据被放置在正确的 TiKV 节点上。该规则不保证传输中的数据(通过用户查询或内部操作)只出现在特定区域内。
四、总结
这次实践了 TiDB 两地三中心的部署及其全球化策略,为后面真实场景的使用 TiDB 做了预演,若如真实环境使用前需要做更多的准备如真实环境,数据模拟,压测等。
还需要考虑 PD 部署会不会成为瓶颈,TiDB-server 的部署方案等更多因素!
v6.0 以前的版本部署两地三中心需要使用 pd-ctl 比较麻烦,并且对指定位置放置指定数量的副本也无法做到。由此可见,Placement Rules in SQL 是很好的礼物!
谢谢 TiDB 产研的小伙伴们!
谢谢 TiDB 社区!
这篇关于基于 TiDB v6.0 部署两地三中心的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








