本文主要是介绍【论文阅读】NIPS2022 || Enhance the Visual Representation via DiscreteAdversarial Training,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文地址:https://arxiv.org/abs/2209.07735
开源地址:https://github.com/alibaba/easyrobust
本文发表于NIPS2022,用离散对抗训练提高视觉模型的表现,它的作者是来自阿里的科研团队
Abstract
对抗训练(A T)是目前公认的对抗范例防御最有效的方法之一,但其对标准性能的影响很大,在工业生产和应用上的实用性有限。令人惊讶的是,在自然语言处理(NLP)任务中,这种现象完全相反,在NLP任务中,T甚至可以受益于泛化。
我们注意到AT在NLP任务中的优点可能来自于离散和符号输入空间。为了借鉴nlp风格AT的优点,我们提出了离散对抗训练(DA T)。DA T利用VQGAN将图像数据转换为离散的文本类输入,即视觉单词。然后,它最小化了这些离散图像的最大风险与符号对抗扰动。我们进一步从分布的角度进行了解释,证明了DA T的有效性,作为一种即插即用的增强视觉表示的技术,DA T在图像分类、目标检测和自监督学习等多项任务上都取得了显著的改善。特别地,使用蒙面自动编码(MAE)预训练的模型,在没有额外数据的情况下,通过我们的DAT进行微调,可以在ImageNet-C上获得31.40 mCE,在程式化的imagenet上获得32.77%的top-1精度,建立了新的技术水平。
Motivation
目前对抗训练还难以大规模应用,主要原因在于两点:
对抗训练会成倍数的增加模型的训练代价
对抗训练在提升鲁棒性的同时,也显著降低了模型在正常数据上的准确率。这个现象,被称作“Accuracy vs. Robustness Trade-Off(准确性与鲁棒性的权衡)”
而这第二点就是造成对抗训练技术难以落地应用的根本因素。本文旨在解决对抗训练中的“Accuracy vs. Robustness Trade-off”问题。
但在自然语言处理的对抗训练中,通过自动寻找对抗文本输入,AT 不仅不会降低准确性,甚至有利于语言模型的泛化和鲁棒性。这是因为在图像领域对抗样本通常通过像素上的改动产生难数据,而实际中遇到的难数据不会是改动像素导致的,更多反而是物体级别的旋转形变,外部环境光照等因素。因此,我们需要产生更加“贴近自然”的对抗样本,来作为数据增强。相反,文本空间是离散的和象征性的,当人类打错字时,对抗文本实际上存在。学习这样的对抗文本显然会提高对其他更多拼写错误文本的泛化能力。
作者注意到,这种优点可以从语言模型独特的数据组织形式中获得。这种现象促使作者考虑是否可以将 NLP 式 AT 的优点转移到视觉任务中,借用语言的符号本质,通过将连续图像离散化为更有意义的符号空间,将其应用于 CV 任务。
contributions
本文是第一个将NLPstyle对抗性训练的优点转移到视觉模型,来同时提高鲁棒性和泛化的。
我们提出了离散对抗训练(DAT),其中图像以离散视觉词的形式呈现,模型在具有对抗性改变的离散视觉表示的示例上进行训练。
DAT在图像分类、目标检测和自监督学习等多项任务上取得了显著改进。
Method
这篇论文提出的方法就是这个离散对抗训练,将连续图像离散化。
离散对抗训练(DAT) 利用VQ-GAN 学习视觉词汇表,也称为图像代码本(image codebook)。对于连续的图像输入,每个编码的补丁嵌入被码本中最接近的视觉词(visual word)替换,并表示为相应的索引。然后将图像转换为类似于语言输入的一系列符号索引。
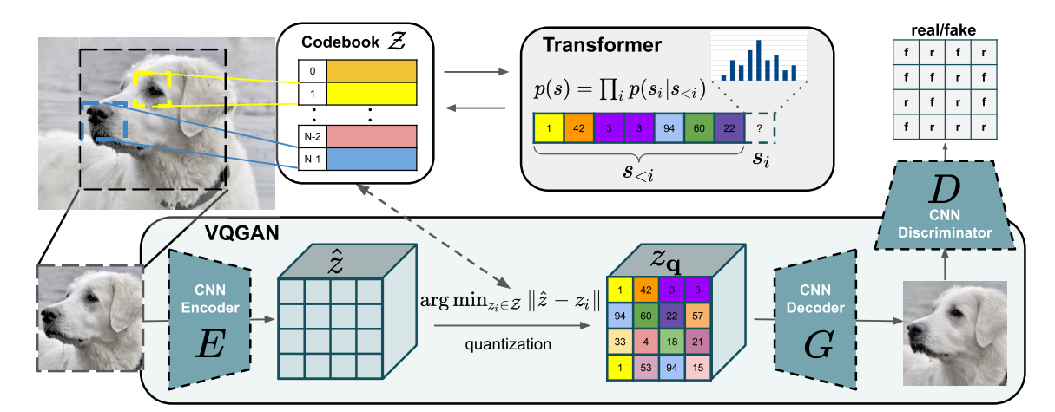
首先回忆一下VQ-GAN。
输入一张图片x ,其通过CNN Encoder编码后得到中间特征变量 z^。普通的AutoEncoder会将z^ 直接送入解码器中进行图像重建。
而在VQGAN中,会将z^进行进一步的离散化编码,具体做法为:预先生成一个离散数值的codebook Z ,在z^的每一个编码位置都去Z中去寻找其距离最近的code,生成具有相同维度的变量 zq。
然后在已经数值离散化的zq 基础上使用CNN Decoder进行解码得到新的图像。
除了这个重建过程使用的自监督损失外,还加入了GAN中的对抗loss。
VQ-GAN
Image Discretization by Visual Codebook
离散对抗训练的过程
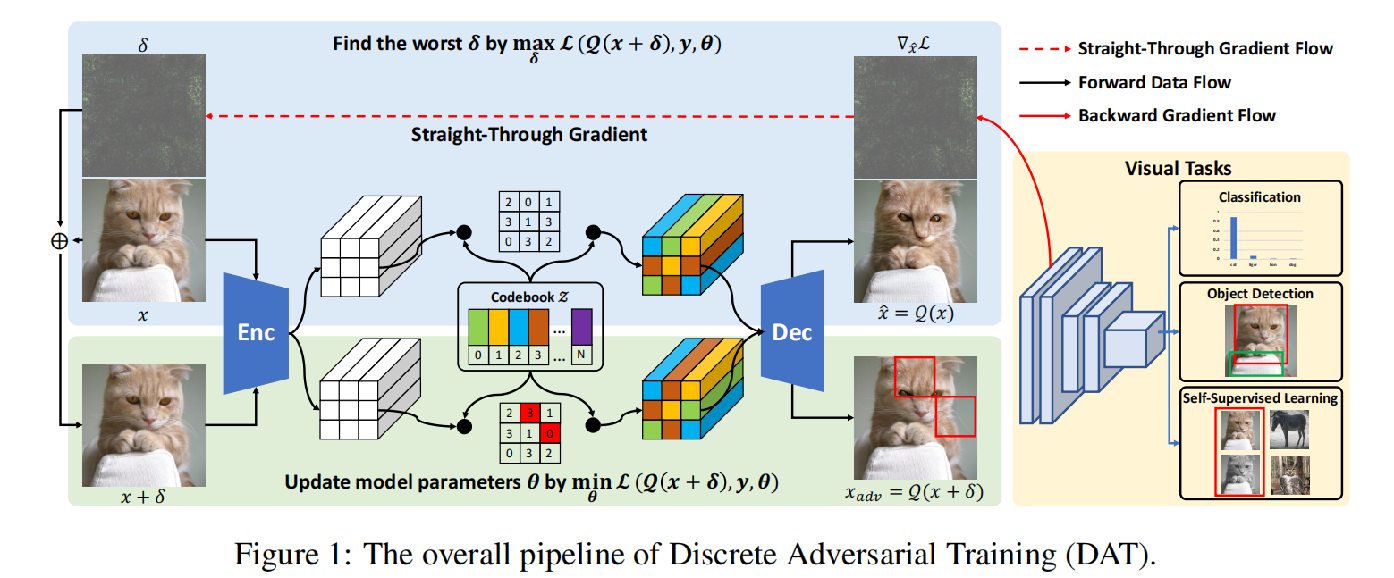
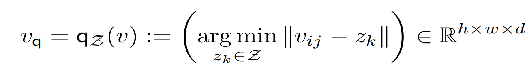
我们首先利用VQGAN的码本将输入图像转化为一串离散的编码并解码成离散图,这个离散化过程我们用Q表示。在这个离散化过程中我们利用梯度求出对抗扰动。
将扰动加到原始图像上得到对抗样本x+δ。扰动后的图像经过再一次离散化即可得到离散对抗样本。将作为“自然对抗样本”数据增强训练不同的CV任务
这样就可以实现在尽可能不影响模型准确率的情况下,提升视觉表征的迁移性和鲁棒性。
Discrete Adversarial Training
离散对抗训练

为了基于这种符号序列生成对抗样本,它在 NLP 中可以直接使用优化方法(如组合优化或同义词替换),但在图像方面就比较困难,原因在于:
1)图像的大搜索空间和。
2)视觉代码本中不存在同义词。
那么本文就还是使用了一个比较传统的方法,用梯度来计算扰动。扰动计算公式如下:
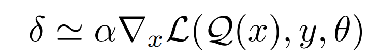
由式δ可以推出偏导数为:
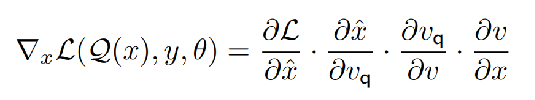
Eq.1
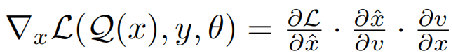
Eq.2
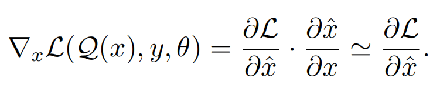
Eq.3
(由前边Vq的式子)由于Vq 是不可微的,所以∂Vq/∂v是不可微的。因此作者将 来取代,使用了直通梯度估计器straight-through gradient estimator,所以Eq.1可以简化为Eq.2。简单地说,就是忽视隐变量选择的过程,直接将解码器的梯度传给编码器,近似一下。
尽管该解决方案在理论上似乎可行,但巨大的成本使其在大规模视觉任务中不切实际。瓶颈主要在于∂x^/∂v和∂v/∂x需要反向到Enc和dec的对抗梯度。实际上,一个能够生成高质量图像的生成器总是有大量的参数。与原来只需要F进行梯度计算的对抗性训练相比,它需要3倍以上的GPU内存和计算成本。
为了解决这个问题,我们提出了一个有效的替代方案。由于对于理想的离散器Q,在经验上观察到x ' ≌ x,我们也可以使用x和x之间的直通梯度估计器,所以Eq.2可以简化为Eq.3。
Code

DAT 的总体流程是:
对于每个训练图像 x,DAT 首先使用 VQGAN 得到离散重建图像x^ 。
通过将x^ 馈送到分类器F,可以通过计算x^的梯度以最大化分类损失来计算扰动 。
在原始 x上添加扰动来得到对抗样本,对抗样本Xadv 再次被 VQGAN 离散化并作为对抗输入。
最后,通过最小化分类损失来训练 。
Experiments
Explaining the Effectiveness of DAT from the Perspective of Distribution
从分布的角度解释为什么 DAT 会有效:
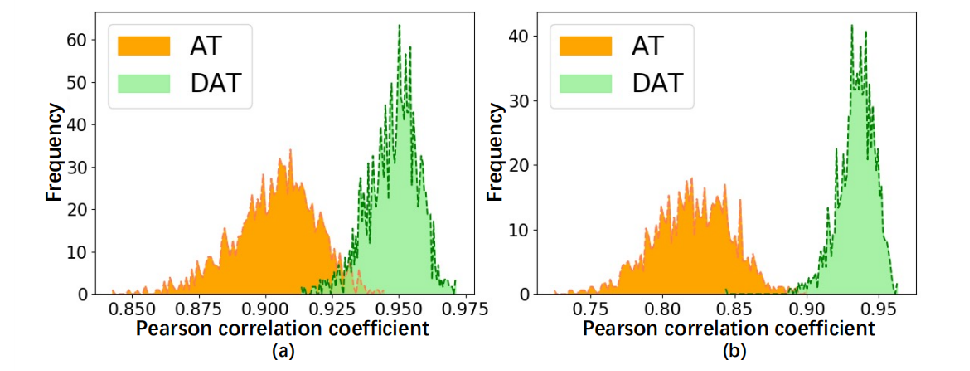
The frequency histogram of the Pearson correlation coefficient (PCC) between BN statistics on clean and adversarial images. Larger PCC value means smaller distributional difference with clean images. (a), (b) present the difference on mean and variance statistics respectively.
之前有的工作已经指出,对抗样本的底层分布与正常图像不同,所以才会导致模型在正常数据上的准确率降低。
于是作者分别用 AT 和 DAT来生成对抗样本。统计干净样本和对抗样本之间的Pearson相关系数(PCC)的频率直方图。PCC值越大,与干净的分布差异越小。(a), (b)分别表示均值统计和方差统计的差异。 可以看出 DAT 生成的离散对抗样本更接近正常分布。
因此,使用本论文提出的离散对抗训练不会导致模型对干净样本的准确率降低。
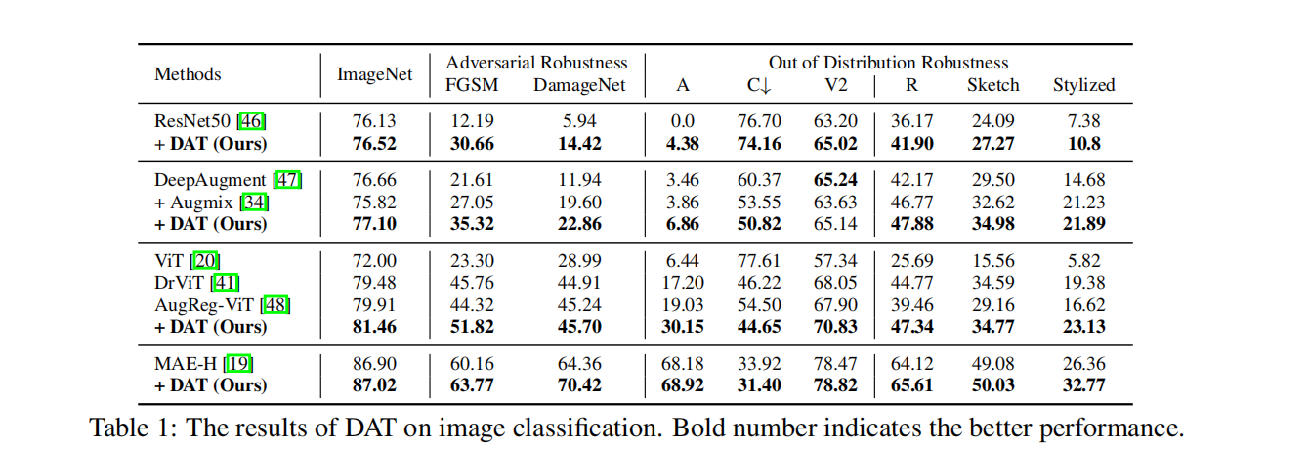
离散对抗训练(DAT)在分类任务上的实验对比
我们采用这些作为基础模型,与本文的方法DAT相结合,可以看到,加入本文的方法后,不管是在原始ImageNet数据集上的分类,还是面对FGSM和DamageNet的攻击,在这些测试集上的鲁棒性都有所提升。
在面对这些分布之外的场景时,除了在C这个数据集场景下鲁棒性有所降低,其他的都是有提升。
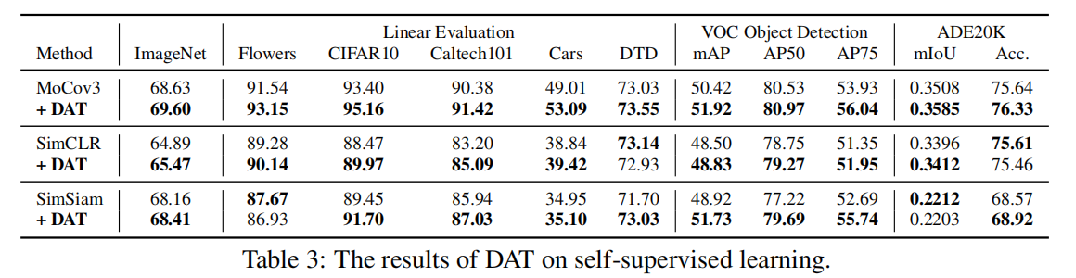
离散对抗训练(DAT)在自监督任务上的实验对比
我们在这三种(MoCov3、simCLR、Simsiam)自监督方法上实验DAT。离散对抗训练仅在预训练阶段进行。线性评估在五个分类数据集上报告了top-1的准确性,为了排除DAT不只是在ImageNet上过拟合,我们转移了下游任务目标检测和语义分割任务的表示。
结果表明加上DAT后结果都有所提升。
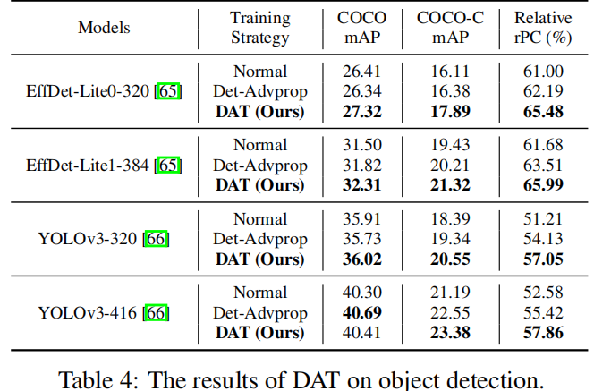
离散对抗训练(DAT)在目标检测任务上的实验对比
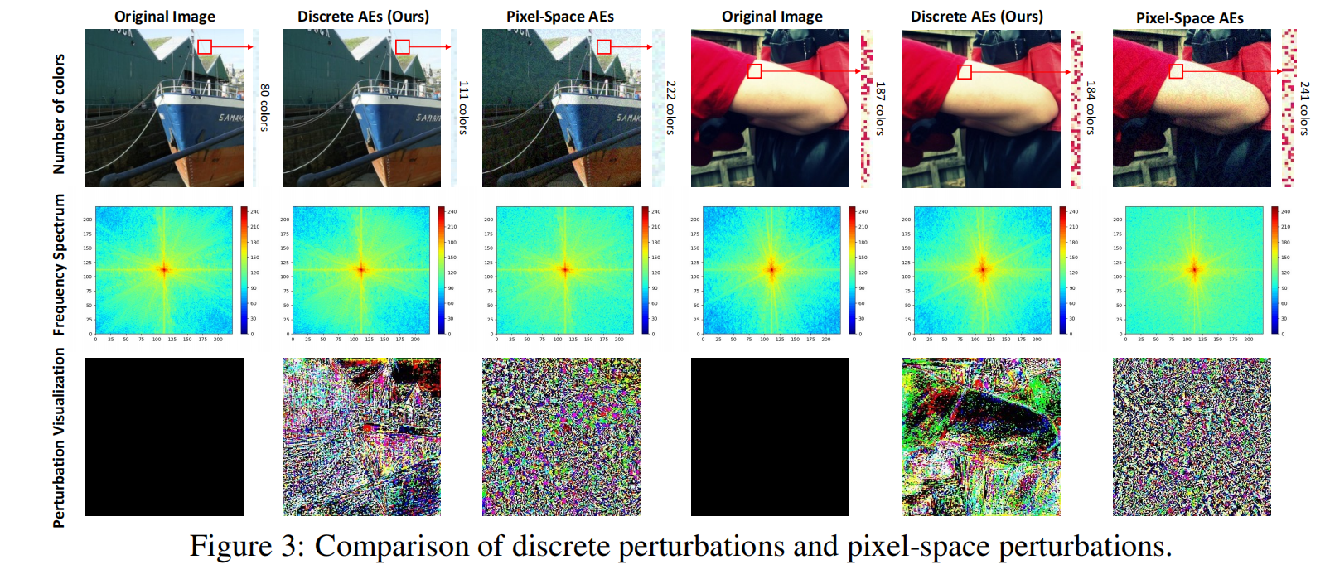
上图的消融实验中比较了所提出的离散对抗样本(DAEs)与传统的像素空间对抗样本(PAEs),结果如下:
1) DAE 更真实。 通过计算颜色数量,发现 PAE 添加了更多无效颜色,导致图像出现噪声。
2) 在频率分析中,dae的高频分量比AEs少,更接近原图像。
3)离散扰动更具结构性,表明它关注更重要的物体位置。
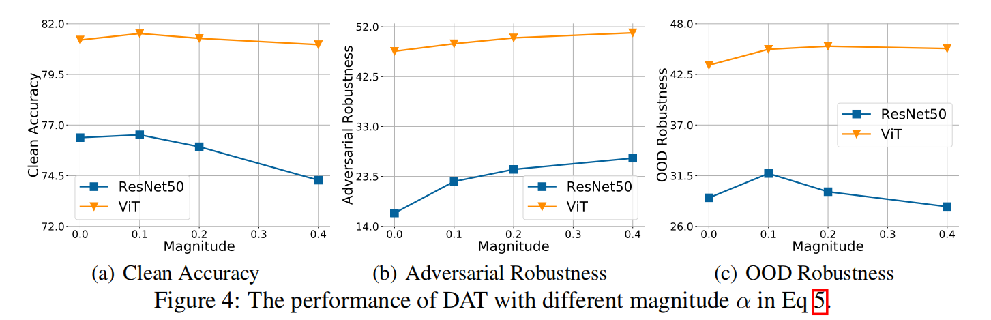
公式中不同幅度α的DAT的表现
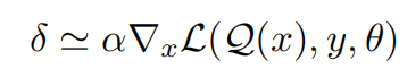
在ResNet50和ViT中不同α的DAT结果。α = 0表示模型只在VQGAN增强的图像上训练,没有对抗性训练过程。
α = 0时的DAT使模型具有较高的干净精度,但鲁棒性最低。随着α的增加,仍然存在鲁棒性和准确性的权衡。
ResNet50(蓝)上α = 0.4的DA T获得了最好的对抗鲁棒性,但OOD泛化变差。而在α = 0.4的DAT上训练ViT,干净样本精度和OOD精度仍然没有太大的下降。
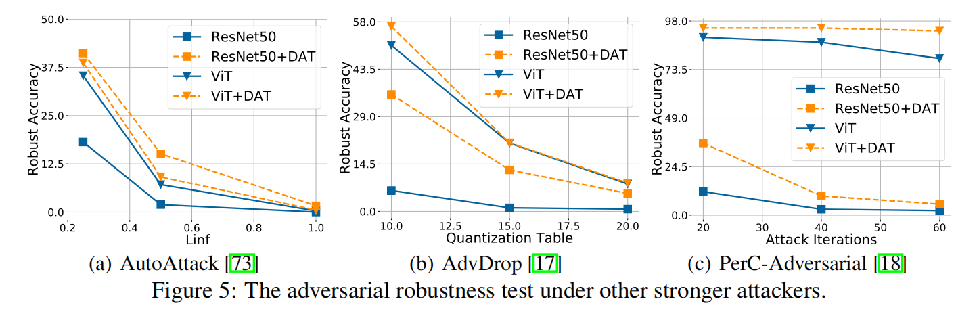
在其他更强攻击下的对抗鲁棒性测试
在前面实验中,只使用了FGSM来检验鲁棒性。为了进行更全面的评估,我们还在更强的三种攻击下测试了DAT。结果如图所示。DAT在这三种攻击下都提高了鲁棒性。
这篇关于【论文阅读】NIPS2022 || Enhance the Visual Representation via DiscreteAdversarial Training的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







