本文主要是介绍【mmdetection代码解读 3.x版本】以Fcos+FasterRcnn为例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- RPN部分的代码
- 1. loss函数(two_stage.py)
- 1.1 loss_and_predict函数(base_dense_head.py)
- 1.1.1 loss_by_feat函数(fcos_head.py)
- 1.1.1.1 get_targets函数
- 1.1.2 predict_by_feat函数(base_dense_head.py)
- 1.1.2.1 _predict_by_feat_single函数(base_dense_head.py)
- 1.1.2.2 _bbox_post_process函数(base_dense_head.py)
前言
因为之前一直在搞DOTA数据集的旋转框检测,所以一直在用mmrotate作为主要工具。现在回来重新搞mmdetection框架发现有了不小的变化,出了3.x版本的新内容。相比于之前的版本变化比较大,因此正好做一个代码解读与之前发布的2.x版本进行对照。
新版本最让我惊喜的是可以将单阶段检测器作为 RPN进行两阶段的检测,官方文档如下
https://mmdetection.readthedocs.io/zh_CN/latest/user_guides/single_stage_as_rpn.html
按照官方文档的要求我们将Fcos作为RPN的提取网络,为ROI提取proposal,具体配置文件如下
_base_ = ['../_base_/models/faster-rcnn_r50_fpn.py','../_base_/datasets/coco_detection.py','../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
model = dict(# 从 configs/fcos/fcos_r50-caffe_fpn_gn-head_1x_coco.py 复制neck=dict(start_level=1,add_extra_convs='on_output', # 使用 P5relu_before_extra_convs=True),rpn_head=dict(_delete_=True, # 忽略未使用的旧设置type='FCOSHead',num_classes=1, # 对于 rpn, num_classes = 1,如果 num_classes > 1,它将在 TwoStageDetector 中自动设置为1in_channels=256,stacked_convs=4,feat_channels=256,strides=[8, 16, 32, 64, 128],loss_cls=dict(type='FocalLoss',use_sigmoid=True,gamma=2.0,alpha=0.25,loss_weight=1.0),loss_bbox=dict(type='IoULoss', loss_weight=1.0),loss_centerness=dict(type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),roi_head=dict( # featmap_strides 的更新取决于于颈部的步伐bbox_roi_extractor=dict(featmap_strides=[8, 16, 32, 64, 128])))
# 学习率
param_scheduler = [dict(type='LinearLR', start_factor=0.001, by_epoch=False, begin=0,end=1000), # 慢慢增加 lr,否则损失变成 NANdict(type='MultiStepLR',begin=0,end=12,by_epoch=True,milestones=[8, 11],gamma=0.1)
]
和之前2.x版本的代码分析一样,跳过Resnet和FPN的部分,我们直接从RPN开始
RPN部分的代码
我们首先找到FasterRCNN这主类,可以看到继承了TwoStageDetector,所以我们接下来的重点是TwoStageDetector这个类
1. loss函数(two_stage.py)
不知道为什么3.x版本的two_stage函数没有了forward函数反而多了几个loss,predict函数。因为不知道运行顺序所以直接每一个类都打上了断点,最后发现是进入了loss函数里。
def loss(self, batch_inputs: Tensor,batch_data_samples: SampleList) -> dict:
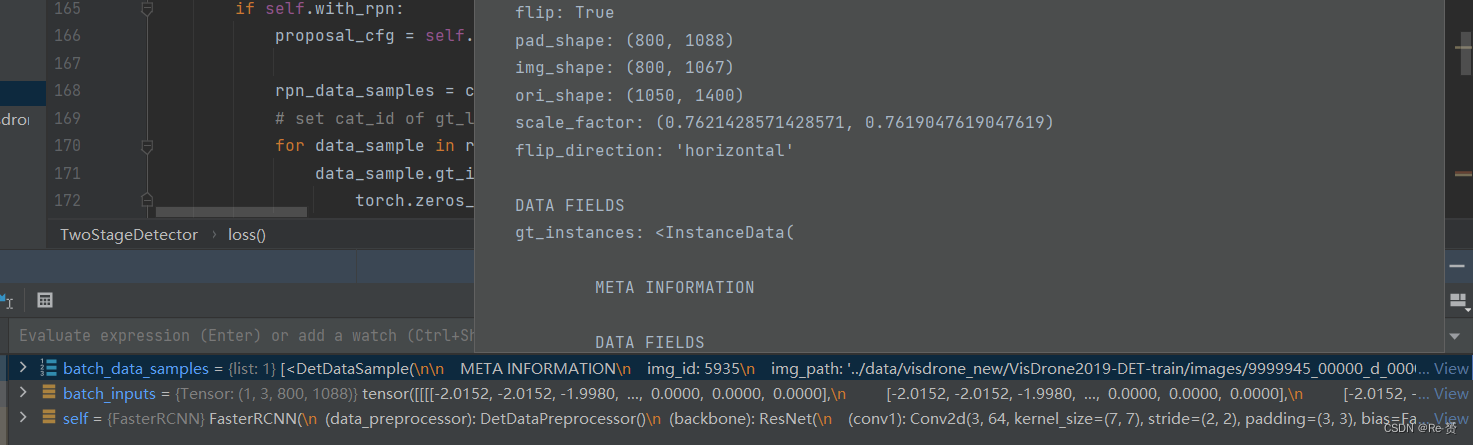
x = self.extract_feat(batch_inputs)其中extract_feat的内容是x = self.backbone(batch_inputs)if self.with_neck:x = self.neck(x)return x

losses = dict()if self.with_rpn:proposal_cfg = self.train_cfg.get('rpn_proposal',self.test_cfg.rpn)rpn_data_samples = copy.deepcopy(batch_data_samples)

for data_sample in rpn_data_samples:data_sample.gt_instances.labels = \torch.zeros_like(data_sample.gt_instances.labels)将每个 data_sample 中的目标实例的标签信息都设置为零,因为作为rpn网络只要进行二分类任务
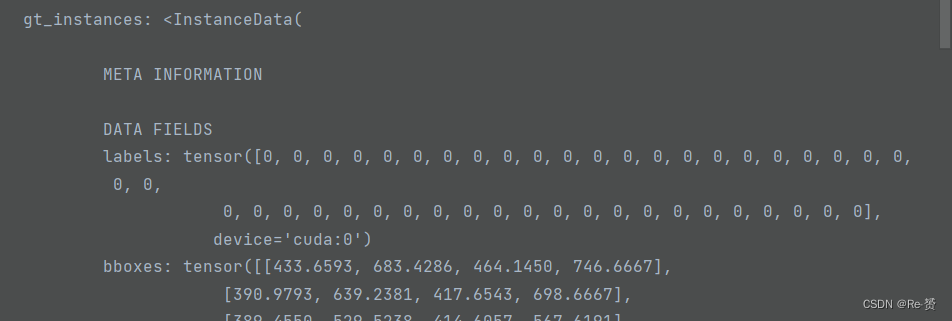
rpn_losses, rpn_results_list = self.rpn_head.loss_and_predict(x, rpn_data_samples, proposal_cfg=proposal_cfg) 详见1.1.1计算 RPN 模型的损失并生成建议框的预测结果

keys = rpn_losses.keys()
for key in list(keys):if 'loss' in key and 'rpn' not in key:rpn_losses[f'rpn_{key}'] = rpn_losses.pop(key)
losses.update(rpn_losses)

roi_losses = self.roi_head.loss(x, rpn_results_list,batch_data_samples)
losses.update(roi_losses)

1.1 loss_and_predict函数(base_dense_head.py)
def loss_and_predict(self,x: Tuple[Tensor],batch_data_samples: SampleList,proposal_cfg: Optional[ConfigDict] = None) -> Tuple[dict, InstanceList]:
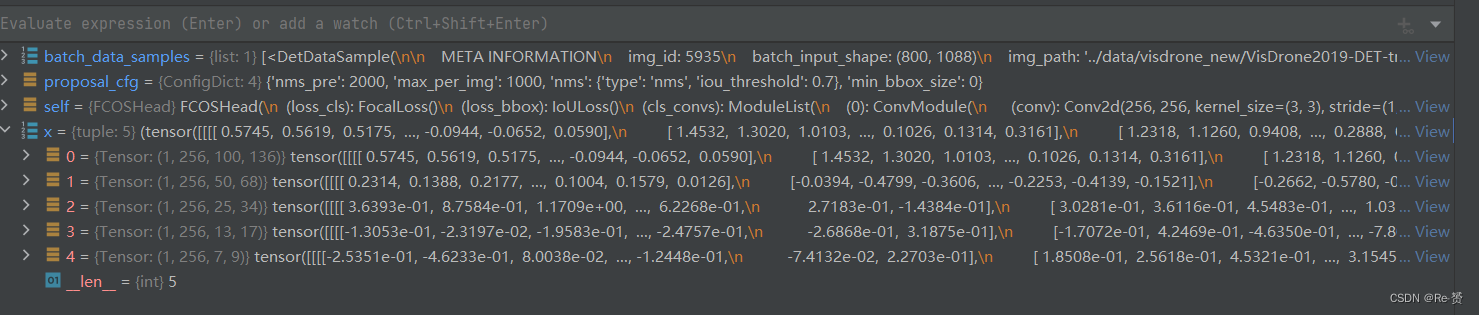
outputs = unpack_gt_instances(batch_data_samples)(batch_gt_instances, batch_gt_instances_ignore,batch_img_metas) = outputs将批量数据中的目标实例信息和图像元信息提取出来,以便后续的处理和分析

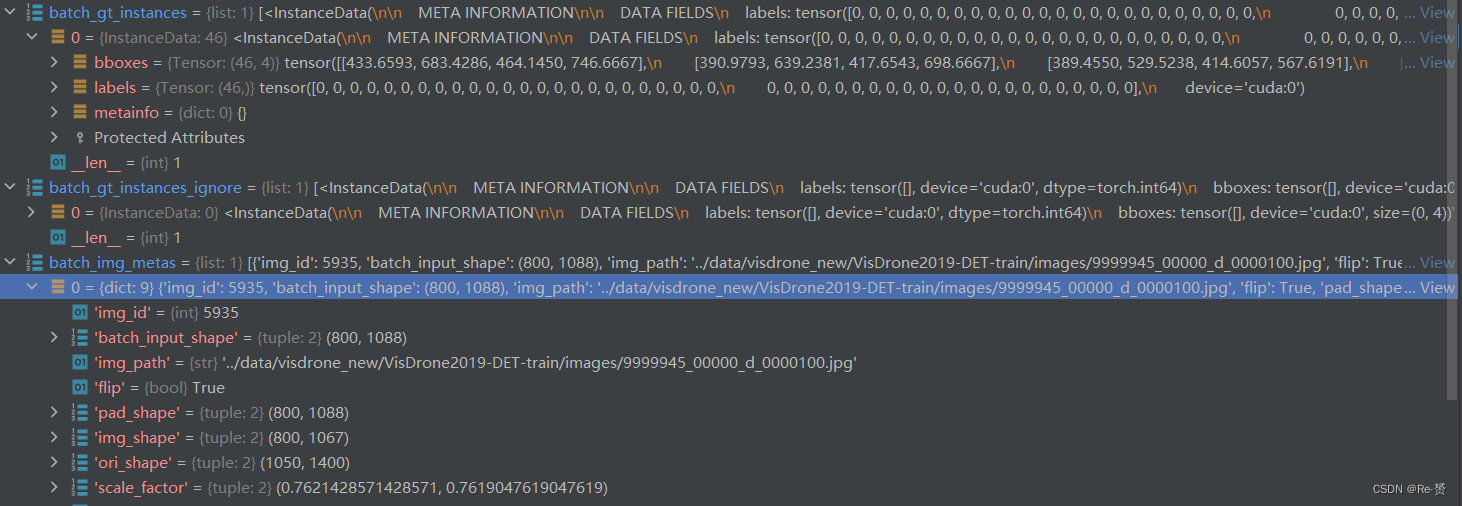
outs = self(x)输入预测网络预测cls_score, bbox_pred, centerness三个属性
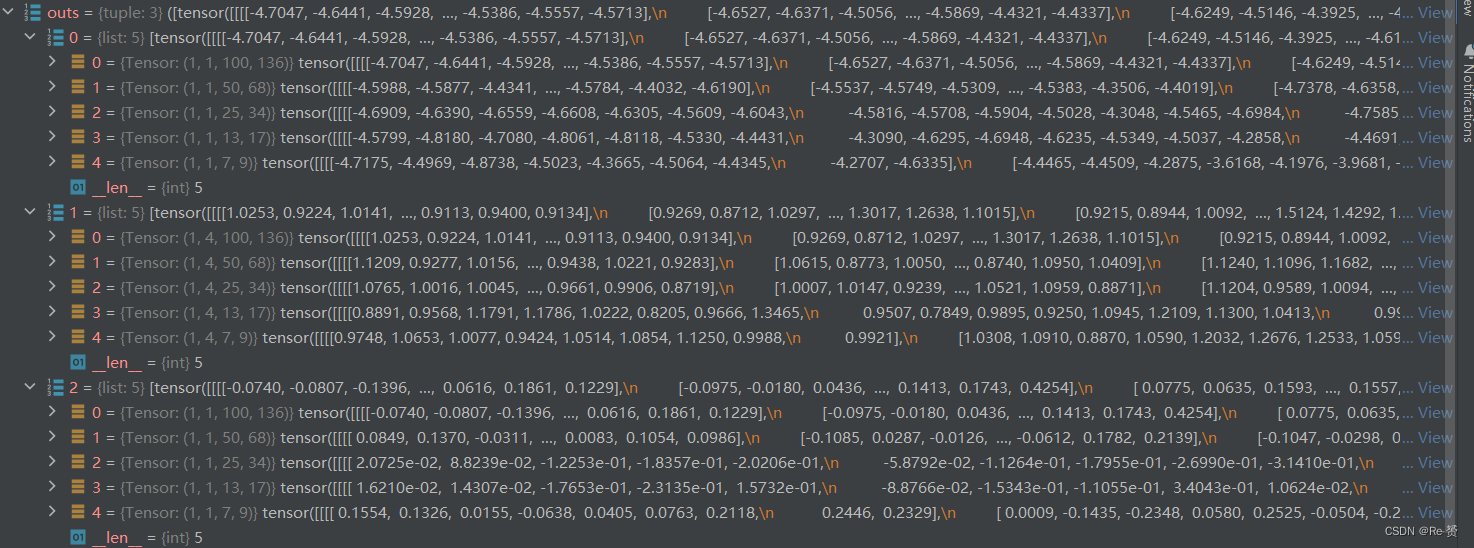
loss_inputs = outs + (batch_gt_instances, batch_img_metas,batch_gt_instances_ignore)loss_inputs 元组将用于计算损失函数,其中包括模型的输出 outs、目标实例信息 batch_gt_instances、
图像元信息 batch_img_metas 以及忽略的目标实例信息 batch_gt_instances_ignore
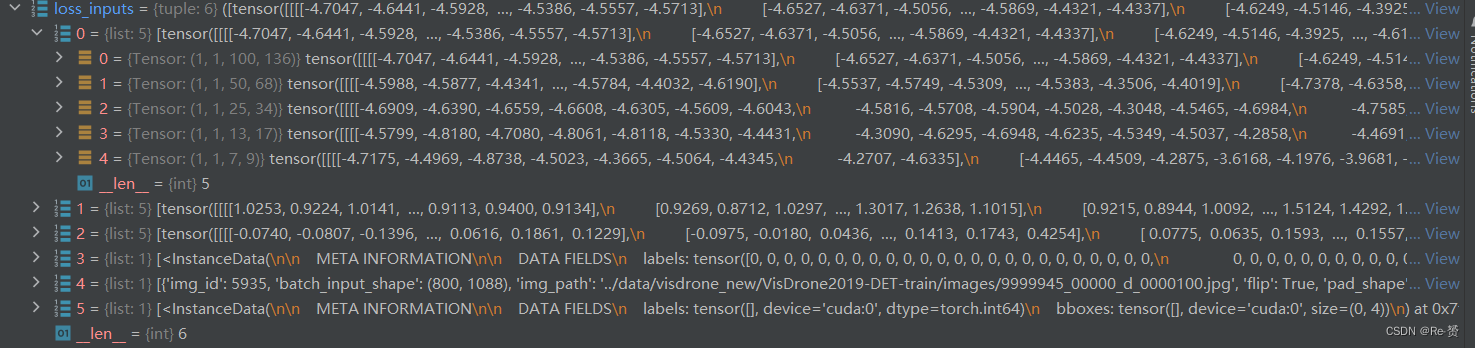
losses = self.loss_by_feat(*loss_inputs) 详见1.1.1计算损失值

predictions = self.predict_by_feat(*outs, batch_img_metas=batch_img_metas, cfg=proposal_cfg) 详见1.1.2生成目标检测的预测成果

1.1.1 loss_by_feat函数(fcos_head.py)
def loss_by_feat(self,cls_scores: List[Tensor],bbox_preds: List[Tensor],centernesses: List[Tensor],batch_gt_instances: InstanceList,batch_img_metas: List[dict],batch_gt_instances_ignore: OptInstanceList = None) -> Dict[str, Tensor]:
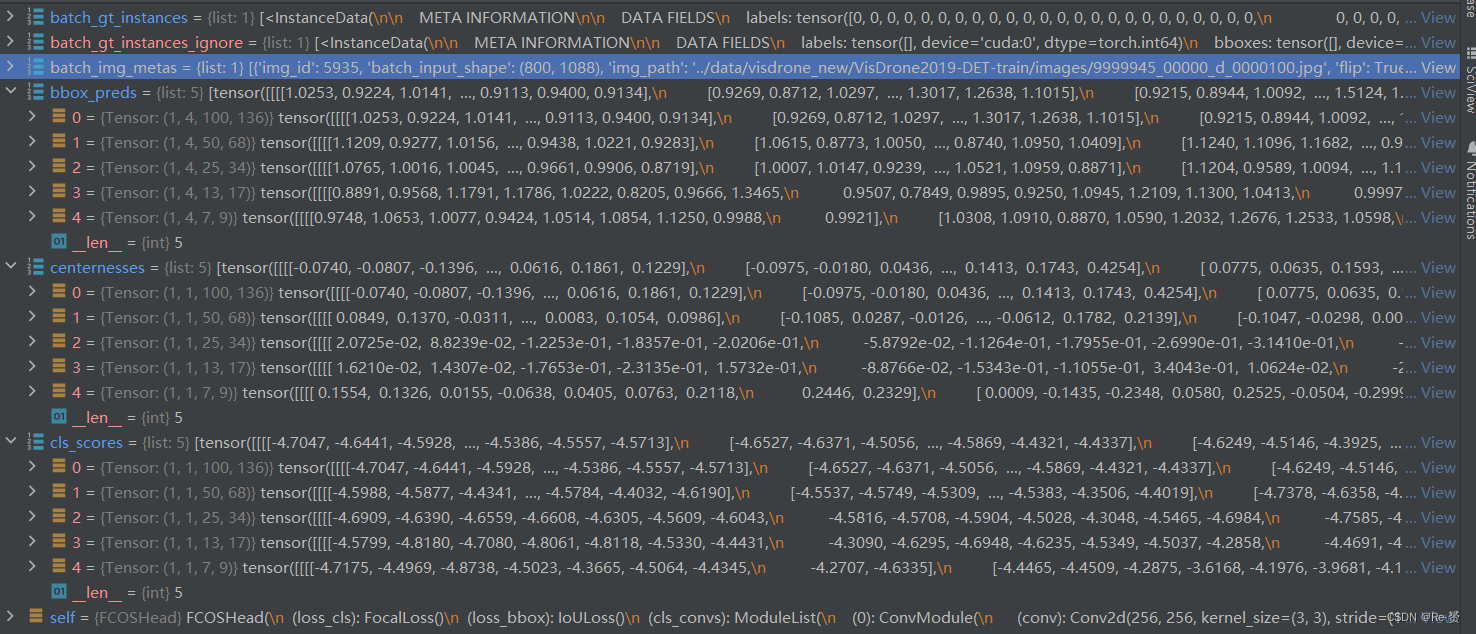
assert len(cls_scores) == len(bbox_preds) == len(centernesses)
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]获取每一个特征图的尺寸

all_level_points = self.prior_generator.grid_priors(featmap_sizes,dtype=bbox_preds[0].dtype,device=bbox_preds[0].device)组成先验框的点

labels, bbox_targets = self.get_targets(all_level_points,batch_gt_instances) 详见1.1.1.1


flatten_cls_scores = [cls_score.permute(0, 2, 3, 1).reshape(-1, self.cls_out_channels)for cls_score in cls_scores]
flatten_bbox_preds = [bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)for bbox_pred in bbox_preds
]
flatten_centerness = [centerness.permute(0, 2, 3, 1).reshape(-1)for centerness in centernesses
]
flatten_cls_scores = torch.cat(flatten_cls_scores)
flatten_bbox_preds = torch.cat(flatten_bbox_preds)
flatten_centerness = torch.cat(flatten_centerness)

flatten_labels = torch.cat(labels)
flatten_bbox_targets = torch.cat(bbox_targets)
# repeat points to align with bbox_preds
flatten_points = torch.cat([points.repeat(num_imgs, 1) for points in all_level_points])


bg_class_ind = self.num_classes
pos_inds = ((flatten_labels >= 0)& (flatten_labels < bg_class_ind)).nonzero().reshape(-1)将背景类的索引设置为 num_classes
用于获取正样本的索引

num_pos = torch.tensor(len(pos_inds), dtype=torch.float, device=bbox_preds[0].device)
num_pos = max(reduce_mean(num_pos), 1.0)计算了正样本的数量,并且将其转换为张量 num_pos,后使用 reduce_mean 函数来计算正样本数量的平均值,并使用 max 函数确保这个平均值至少为1.0。

loss_cls = self.loss_cls(flatten_cls_scores, flatten_labels, avg_factor=num_pos)使用分类损失函数 self.loss_cls 来计算分类损失
pos_bbox_preds = flatten_bbox_preds[pos_inds]
pos_centerness = flatten_centerness[pos_inds]
pos_bbox_targets = flatten_bbox_targets[pos_inds]
pos_centerness_targets = self.centerness_target(pos_bbox_targets)# centerness weighted iou loss
centerness_denorm = max(reduce_mean(pos_centerness_targets.sum().detach()), 1e-6)通过索引 pos_inds 从之前展平的张量中提取了正样本对应的边界框预测、中心度预测、边界框目标和中心度目标

if len(pos_inds) > 0:pos_points = flatten_points[pos_inds]pos_decoded_bbox_preds = self.bbox_coder.decode(pos_points, pos_bbox_preds)pos_decoded_target_preds = self.bbox_coder.decode(pos_points, pos_bbox_targets)loss_bbox = self.loss_bbox(pos_decoded_bbox_preds,pos_decoded_target_preds,weight=pos_centerness_targets,avg_factor=centerness_denorm)loss_centerness = self.loss_centerness(pos_centerness, pos_centerness_targets, avg_factor=num_pos)如果存在正样本所有点坐标中提取正样本的点坐标使用边界框编码器解码正样本的边界框预测和目标计算边界框损失,使用解码后的边界框预测和目标值计算中心度损失


return dict(loss_cls=loss_cls,loss_bbox=loss_bbox,loss_centerness=loss_centerness)
1.1.1.1 get_targets函数
def get_targets(self, points: List[Tensor], batch_gt_instances: InstanceList) -> Tuple[List[Tensor], List[Tensor]]:

assert len(points) == len(self.regress_ranges)
num_levels = len(points)
# expand regress ranges to align with points
expanded_regress_ranges = [points[i].new_tensor(self.regress_ranges[i])[None].expand_as(points[i]) for i in range(num_levels)]将回归范围扩展以与点对齐

concat_regress_ranges = torch.cat(expanded_regress_ranges, dim=0)
concat_points = torch.cat(points, dim=0)
num_points = [center.size(0) for center in points]连接所有级别的点和回归范围
存储每个级别中的点的数量


labels_list, bbox_targets_list = multi_apply(self._get_targets_single,batch_gt_instances,points=concat_points,regress_ranges=concat_regress_ranges,num_points_per_lvl=num_points)将 _get_target_single 方法应用到多个图像上,以计算每个图像中的回归、分类和角度目标


labels_list = [labels.split(num_points, 0) for labels in labels_list]
bbox_targets_list = [bbox_targets.split(num_points, 0)for bbox_targets in bbox_targets_list
]将目标分割为每个图像的每个级别


concat_lvl_labels = []
concat_lvl_bbox_targets = []
for i in range(num_levels):concat_lvl_labels.append(torch.cat([labels[i] for labels in labels_list]))bbox_targets = torch.cat([bbox_targets[i] for bbox_targets in bbox_targets_list])if self.norm_on_bbox:bbox_targets = bbox_targets / self.strides[i]concat_lvl_bbox_targets.append(bbox_targets)
return concat_lvl_labels, concat_lvl_bbox_targets连接每个级别中每个图像的目标
返回包含连接后的每个级别的分类标签、回归目标

1.1.2 predict_by_feat函数(base_dense_head.py)
def predict_by_feat(self,cls_scores: List[Tensor],bbox_preds: List[Tensor],score_factors: Optional[List[Tensor]] = None,batch_img_metas: Optional[List[dict]] = None,cfg: Optional[ConfigDict] = None,rescale: bool = False,with_nms: bool = True) -> InstanceList:
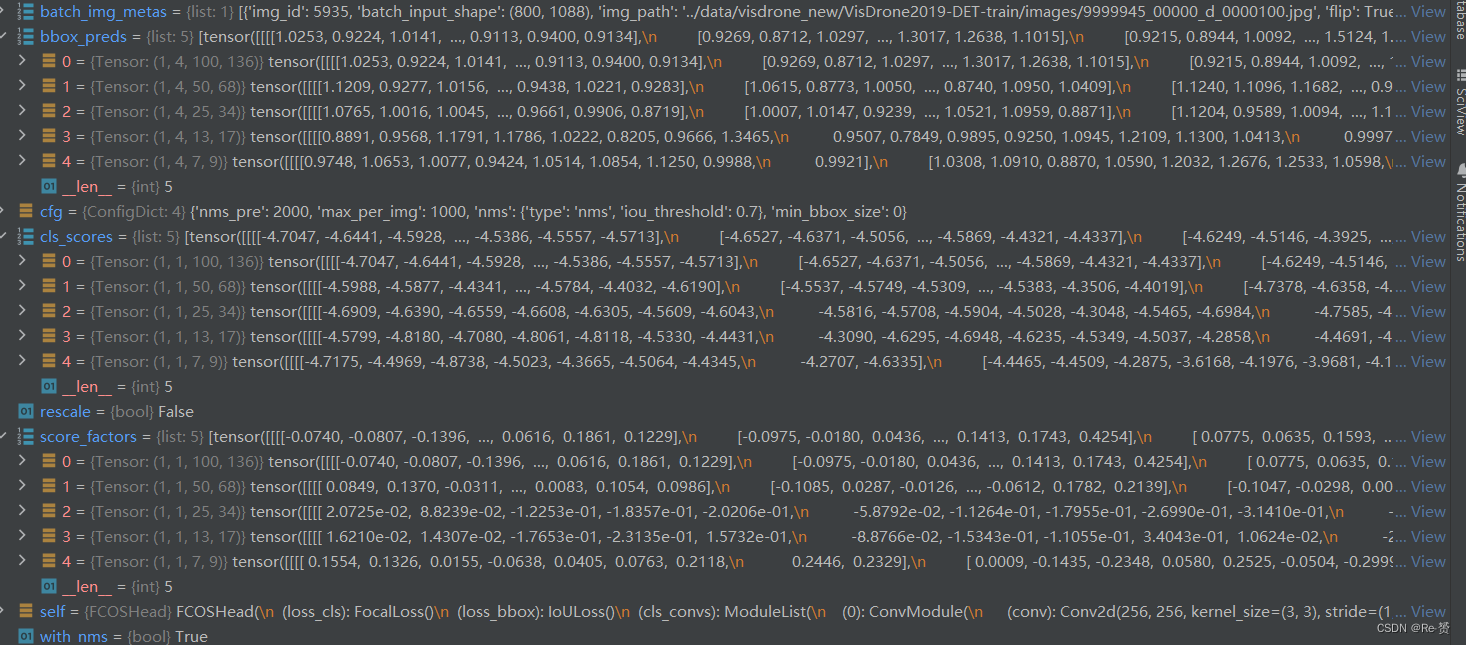
assert len(cls_scores) == len(bbox_preds)if score_factors is None:# e.g. Retina, FreeAnchor, Foveabox, etc.with_score_factors = False
else:# e.g. FCOS, PAA, ATSS, AutoAssign, etc.with_score_factors = Trueassert len(cls_scores) == len(score_factors)num_levels = len(cls_scores)

featmap_sizes = [cls_scores[i].shape[-2:] for i in range(num_levels)]mlvl_priors = self.prior_generator.grid_priors(featmap_sizes,dtype=cls_scores[0].dtype,device=cls_scores[0].device)获取每个尺度层级的特征图大小
生成每个尺度层级上的先验框坐标


result_list = []for img_id in range(len(batch_img_metas)):img_meta = batch_img_metas[img_id]cls_score_list = select_single_mlvl(cls_scores, img_id, detach=True)bbox_pred_list = select_single_mlvl(bbox_preds, img_id, detach=True)if with_score_factors:score_factor_list = select_single_mlvl(score_factors, img_id, detach=True)else:score_factor_list = [None for _ in range(num_levels)]提取当前图片的类别得分、边界框预测、和中心度预测



results = self._predict_by_feat_single(cls_score_list=cls_score_list,bbox_pred_list=bbox_pred_list,score_factor_list=score_factor_list,mlvl_priors=mlvl_priors,img_meta=img_meta,cfg=cfg,rescale=rescale,with_nms=with_nms)
result_list.append(results)通过单张图片的特征和预测,获取边界框信息 详见1.1.2.1
return result_list

1.1.2.1 _predict_by_feat_single函数(base_dense_head.py)
def _predict_by_feat_single(self,cls_score_list: List[Tensor],bbox_pred_list: List[Tensor],score_factor_list: List[Tensor],mlvl_priors: List[Tensor],img_meta: dict,cfg: ConfigDict,rescale: bool = False,with_nms: bool = True) -> InstanceData:
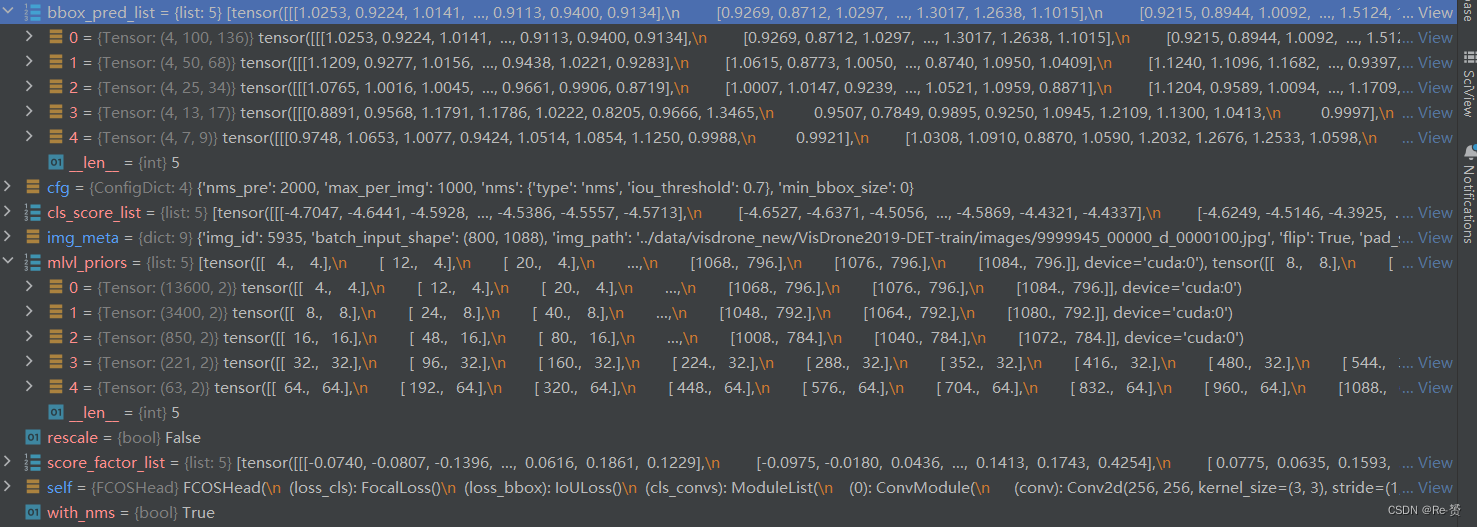
if score_factor_list[0] is None:# e.g. Retina, FreeAnchor, etc.with_score_factors = False
else:# e.g. FCOS, PAA, ATSS, etc.with_score_factors = True
cfg = self.test_cfg if cfg is None else cfg
cfg = copy.deepcopy(cfg)
img_shape = img_meta['img_shape']
nms_pre = cfg.get('nms_pre', -1)mlvl_bbox_preds = []
mlvl_valid_priors = []
mlvl_scores = []
mlvl_labels = []
if with_score_factors:mlvl_score_factors = []
else:mlvl_score_factors = None


for level_idx, (cls_score, bbox_pred, score_factor, priors) in \enumerate(zip(cls_score_list, bbox_pred_list,score_factor_list, mlvl_priors)):assert cls_score.size()[-2:] == bbox_pred.size()[-2:]dim = self.bbox_coder.encode_sizebbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, dim)if with_score_factors:score_factor = score_factor.permute(1, 2,0).reshape(-1).sigmoid()cls_score = cls_score.permute(1, 2,0).reshape(-1, self.cls_out_channels)if self.use_sigmoid_cls:scores = cls_score.sigmoid()else:# remind that we set FG labels to [0, num_class-1]# since mmdet v2.0# BG cat_id: num_classscores = cls_score.softmax(-1)[:, :-1]对每一层特征做处理,这里以第一层100 * 136 作为演示



score_thr = cfg.get('score_thr', 0)results = filter_scores_and_topk(scores, score_thr, nms_pre,dict(bbox_pred=bbox_pred, priors=priors))使用score_thr和topk过滤结果

scores, labels, keep_idxs, filtered_results = results




bbox_pred = filtered_results['bbox_pred']
priors = filtered_results['priors']


if with_score_factors:score_factor = score_factor[keep_idxs]mlvl_bbox_preds.append(bbox_pred)mlvl_valid_priors.append(priors)mlvl_scores.append(scores)mlvl_labels.append(labels)
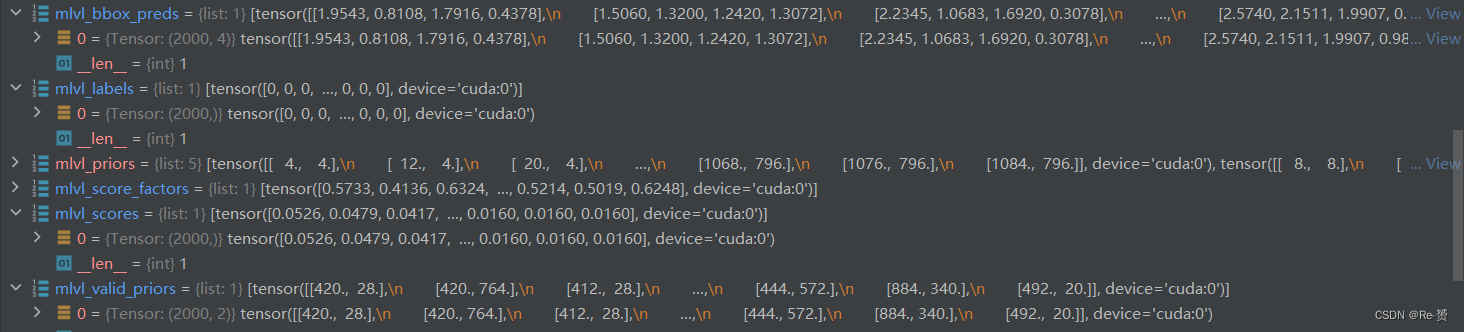
至此循环结束bbox_pred = torch.cat(mlvl_bbox_preds)
priors = cat_boxes(mlvl_valid_priors)
bboxes = self.bbox_coder.decode(priors, bbox_pred, max_shape=img_shape)


results = InstanceData()
results.bboxes = bboxes
results.scores = torch.cat(mlvl_scores)
results.labels = torch.cat(mlvl_labels)
if with_score_factors:results.score_factors = torch.cat(mlvl_score_factors)使用InstanceData类进行封装

return self._bbox_post_process(results=results,cfg=cfg,rescale=rescale,with_nms=with_nms,img_meta=img_meta) 详见1.1.2.2
1.1.2.2 _bbox_post_process函数(base_dense_head.py)
def _bbox_post_process(self,results: InstanceData,cfg: ConfigDict,rescale: bool = False,with_nms: bool = True,img_meta: Optional[dict] = None) -> InstanceData:
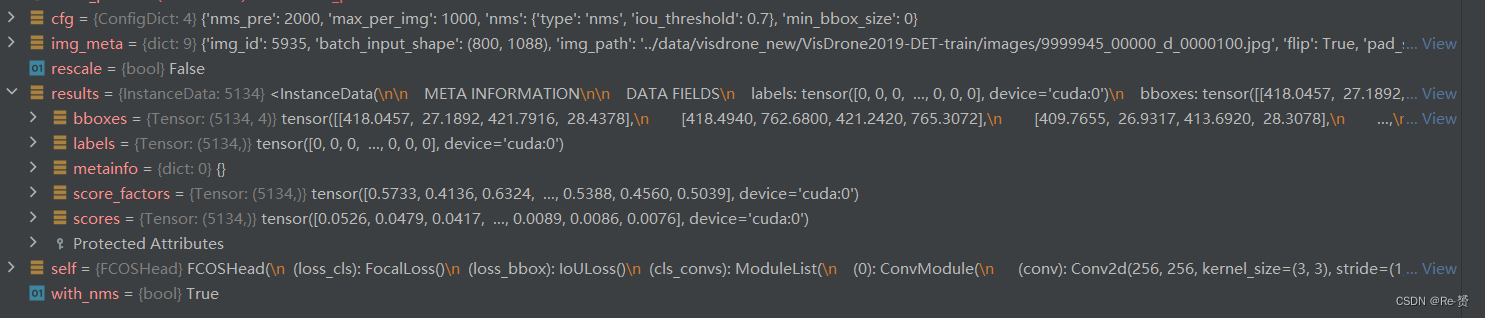
if rescale:assert img_meta.get('scale_factor') is not Nonescale_factor = [1 / s for s in img_meta['scale_factor']]results.bboxes = scale_boxes(results.bboxes, scale_factor)if hasattr(results, 'score_factors'):# TODO: Add sqrt operation in order to be consistent with# the paper.score_factors = results.pop('score_factors')results.scores = results.scores * score_factors
if cfg.get('min_bbox_size', -1) >= 0:w, h = get_box_wh(results.bboxes)valid_mask = (w > cfg.min_bbox_size) & (h > cfg.min_bbox_size)if not valid_mask.all():results = results[valid_mask]检测允许的最小边界框的尺寸


if with_nms and results.bboxes.numel() > 0:bboxes = get_box_tensor(results.bboxes)det_bboxes, keep_idxs = batched_nms(bboxes, results.scores,results.labels, cfg.nms)results = results[keep_idxs]# some nms would reweight the score, such as softnmsresults.scores = det_bboxes[:, -1]results = results[:cfg.max_per_img]return results进行NMS操作并且返回结果




这篇关于【mmdetection代码解读 3.x版本】以Fcos+FasterRcnn为例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






