本文主要是介绍How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources翻译,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
在这项工作中,我们探索在一系列开源指令遵循数据集上进行指令微调的语言模型的最新进展。尽管最近声称开源模型可以与SOTA的私有模型相当,但这些观点通常伴随着有限的评估,因此很难全面比较模型并确定各种资源的实用性。我们提供大量包括从6.7B到65B参数的指令微调模型,这些模型在12个指令数据集中进行了训练,这些数据集通过手动设计(例如,OpenAssistant),合成或蒸馏(例如,Alpaca)获得,并通过自动,基于模型和基于人类的评估指标,系统性地评估这些模型在事实类知识,推理,多语种,代码和开放领域指令遵循的能力。我们进一步介绍了TÜLU,这是我们具有最优性能的指令微调模型,其结合了各种高质量的开源资源。
我们的实验表明,不同的指令数据集可以修复或增强特定技能,而没有单个数据集(或其组合)可以在所有评估中都提供最优性能。有趣的是,我们发现基于模型和基于人类偏好的评估无法反映基准测试评估中表现出的模型能力的差异,这表明在本工作中需要执行系统化的评估类型。我们的评估表明,任何给定评估中的最优模型达到了ChatGPT平均性能的83%以及GPT-4平均性能的68%,这表明需要进一步投资更好的基础模型和指令数据来缩小差距。我们发布了我们的指令微调模型(https://github.com/allenai/open-instruct),包括全参数微调的65B TÜLU,以及我们的代码,数据和评估框架,以促进未来的研究。
1.介绍
最新的生成式大语言模型引起了对语言技术潜力的前所未有的关注。为了和用户请求和聊天范式相对齐,这些模型经常进行指令微调步骤,该步骤涉及在有监督输入-输出对上进行训练。指令微调语料库通常是通过众包(Dolly,Open Assistant)或通过其他模型的蒸馏(Alpaca,Vicuna)来收集。但是,尽管某些公开的指令微调模型被宣传为可与强大的私有模型相当,例如ChatGPT,但大多数支持此类主张的实验仅涵盖一小部分任务,并且主要依赖于基于模型的评估指标。我们认为,除了测试可能更开放和主观的模型或人类标注的生成质量外,评估设置应包括测试模型核心推理和事实召回技能的任务。
本文提供了对指令微调资源的全面评估:具体来说,我们进行了大量的指令微调实验,涵盖了十二个公开语料库,并且模型规模从6.7B到65B。我们评估了特定的模型功能(即事实类知识,推理,多语种,代码)和开放领域的指令遵循能力。我们的报告基于自动化,模型和人类的评估指标。
我们的评估表明,通过不同数据集进行的指令微调似乎可以促进特定的技能,并且没有任意一个数据集在所有评估中都提供最优性能。我们还发现,基础模型至关重要,具有更好的基础模型(无论是在更长的token还是更大尺寸上训练的模型),可以在各方面都表现的更好。令人惊讶的是,我们还发现,基于模型的评估中最优模型与基于基准自动评估的模型不匹配,这可能部分是由于GPT-4对长的,多样化的生成具有较强偏好。
在我们发现的基础上,我们介绍了TÜLU,这是一个基于7B至65B LLAMA模型,在各种数据组合上微调的模型。TÜLU 65B是在编写本论文为止最大的开源的全指令微调的LLAMA变体,据作者所知。它在7个流行的数据集中接受了训练,并产生了最好的平均性能,同时与每个任务上最优模型的性能差距不超过15%。总而言之,我们的主要发现包括:
- 针对特定领域和/或功能的指令数据集在改善这些方面的模型性能方面非常有效。
- 具有更大或更长序列预训练的基本模型在指令微调后会表现地更好。
- 我们的模型TÜLU(基于现有指令数据集的结合对LLaMa进行微调)在基准中实现了最佳的平均性能,尽管在独立考虑不同的任务时,这并不是总体上最好的。
- 即使是在大量的指令数据集中对非常大的(65B)模型进行微调也无法超越ChatGPT,尽管它的性能确实比相似的较小尺寸的模型要好得多。
- 在开放领域指令遵循中,基于模型的偏好评估与模型生成的不同token的平均数量密切相关,这表明基于模型的偏好评估具有可能隐藏模型功能差异的偏见。
我们为训练和评估这些大型语言模型开源了代码。我们还发布了在包括TÜLU在内的不同指令数据集及其混合语料中训练的checkpoints。我们希望这有助于进一步开发和调查指令微调的模型。
2.Background: Instruction Tuning and Resources
2.1 Instruction Tuning
通常,指令微调是指对预训练的语言模型进行微调,以更好地理解和响应用自然语言表达的各种人类要求。它已成为将模型泛化到新场景的关键步骤,而无需专门的训练,并且可以让非专家用于自然与这些模型进行交互。指令微调的训练框架可以是使用演示的有监督训练,或者基于反馈数据的强化学习。在这项工作中,考虑到基于RL的方法的当前开源资源仍然很少见,因此主要关注有监督学习,我们将RL探索作为将来的工作。
指令微调的成功至少需要两个关键组成部分:1)一个强大的预训练语言模型,从网络爬取的数据中进行预训练从而掌握大量知识,以及2)指令数据集,该数据集具有多样化和代表性,足以使LM适应潜在的下游用法。我们在这项工作中研究了这两个因素,并在下面介绍了我们研究的开放资源。
2.2 Instruction Datasets
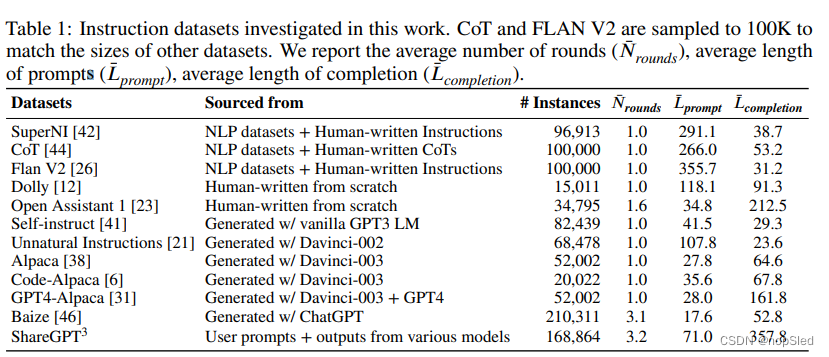
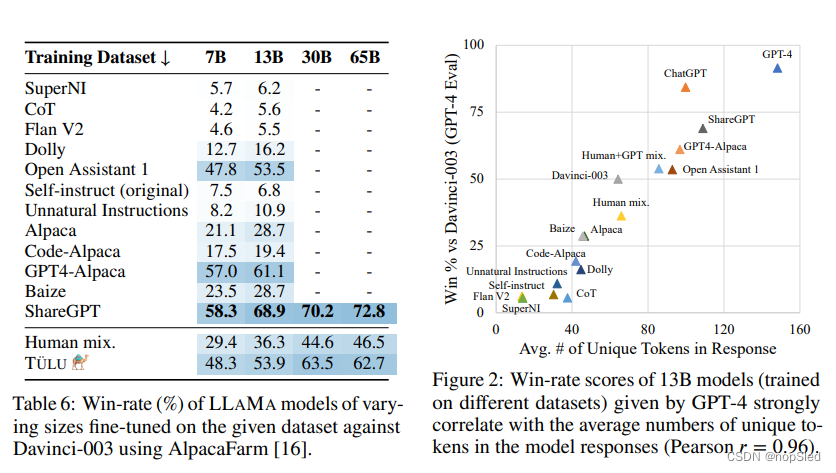
我们试图收集不同类型数据集的代表性样例(表1中列出),其包括了如下数据集:(1)从现有NLP数据集中由研究人员创建(SuperNI,Flan V2);(2)由人类从头开始编写,以进行指令微调(Dolly,Open Assistant 1);(3)由私有模型生成(Self-Instruct,Unnatural Instructions,Alpaca,Baize,GPT4-Alpaca);(4)以用户共享的提示输入,并通过模型生成答案(ShareGPT);(5)专为特定技能而建立的(用于思维链的CoT,用于代码生成的Code-Alpaca)。有关更多详细信息,请参见附录A。
2.3 Pretrained Models
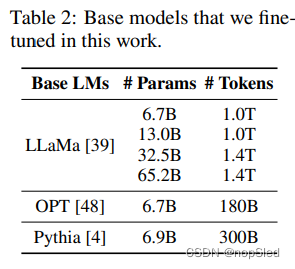
我们主要使用LLAMA,这是一系列预训练模型,参数大小从6.7B到65B。这些模型代表了开源社区目前可用的最大,最优质的预训练模型(尽管受到限制性许可)。我们还考虑具有与LLAMA 6.7b模型相当的尺寸的OPT和Pythia模型,以检查不基础模型的效果。为了简单起见,我们将把所有尺寸都舍入到最近的整数。我们注意到了一些正在进行的努力,以预训练相似或更好质量的模型。我们认为,我们的发现应该能为这些模型和未来更强大的开放基础模型提供支撑。
3. Training Models with Various Datasets
3.1 Unifying the Format

我们格式化所有数据集以遵循聊天机器人风格的模式,以统一指令数据集的各种样式和格式,如图1所示。这使我们能够适应用户与语言模型(也称为“assistant”)之间的任意交互轮数,并将其分为一个输入序列,以将它们与因果语言模型一起编码。我们分别在用户语句和目标助手响应之前添加特殊令牌<|user|>和<|assistant|>,以及在每个助手输出结束的结尾添加一个文本结束标识</s>,该标识将阻止每轮模型继续输出响应。
3.2 Model Training Details
在训练期间,我们仅对<|assistant|>之后和下一个<|user|>之前的token计算损失。更正式地,我们将一个指令数据集视为具有 i i i轮对话的 N N N元组的组合 { ( x 1 j , y 1 j , x 2 j , y 2 j , . . . , x i j , y i j ) } j = 1 N \{(x^j_1,y^j_1,x^j_2,y^j_2,...,x^j_i,y^j_i)\}^N_{j=1} {(x1j,y1j,x2j,y2j,...,xij,yij)}j=1N,其中 x i x_i xi是用户提示, y i y_i yi是所需的输出。对于大多数情况, i = 1 i=1 i=1,我们将模型训练为在给定 x j x^j xj情况下输出 y j y^j yj。但是,在对话数据集的情况下,当给定对话历史 x 1 j , y 1 j , x 2 j , y 2 j , . . . , x i j x^j_1,y^j_1,x^j_2,y^j_2,...,x^j_i x1j,y1j,x2j,y2j,...,xij,我们训练模型来预测 y i j y^j_i yij。我们训练纯解码器的模型,并使用具有loss mask的teacher-forcing对模型进行训练,在该模型中,我们屏蔽了属于输入序列的所有字符。给定 X \textbf X X作为属于输入的字符序列,而 Y \textbf Y Y作为目标令牌,损失函数为:
L = − ∑ j l o g p θ ( t j ∣ t < j ) × { 1 i f t j ∈ Y 0 o h t e r w i s e L=-\sum_jlog~p_{\theta}(t_j|t_{\lt j})\times \begin{cases} 1 & if~t_j\in \textbf Y\\ 0 & ohterwise \end{cases} L=−j∑log pθ(tj∣t<j)×{10if tj∈Yohterwise
其中 t j t_j tj是第 j j j个输入token,其要么属于 X \textbf X X,要么属于 Y \textbf Y Y。训练细节请看附录B。
3.3 TÜLU : a Better Instruction-Tuned Model by Combining Resources
现有的研究(以及下面的评估)表明,增加指令的多样性可以有效地改善指令微调的性能。在此动机之后,我们创建了两个混合数据集:
Human data mixture。该数据集包括最好的人类标注的数据集,包括FLAN V2,CoT,Dolly和Open Assistant 1(我们将SuperNI排除在外,因为FLAN V2已经包含了SuperNI中的大多数任务);
Human+GPT data mixture。该数据集包括人类混合数据和其他三个由OpenAI GPT模型生成的数据集,包括GPT4-Alpaca,Code-Alpaca和ShareGPT。
对于这两个混合数据集,我们都会加入数据集,并将探索更复杂的抽样混合留给未来的工作。我们将在Human+GPT数据混合上训练的LLAMA模型称为TÜLU。
4.Evaluation Setup
由于巨大的通用范围及其开放的特性,对指令遵循模型的评估仍然是一个具有挑战性的问题。但是,我们认为,通用模型在能够泛化到各种实际需求场景之前,其应该能够执行一些核心任务。因此,我们设置了一个多方面的评估,以涵盖核心能力和开放指令遵循能力的几个关键方面。我们的评估仔细遵循了评估指令遵循模型的先前工作,但是第一个将它们编译在一起进行系统评估的工作。
4.1 Facets of Evaluation
4.2 Model-Based Evaluation using GPT-4
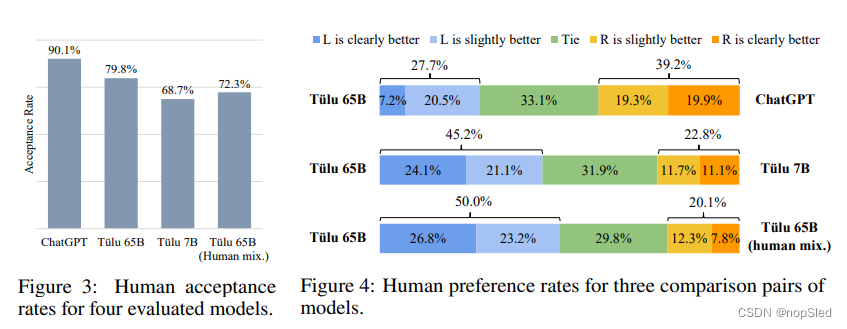
4.3 Human Evaluation
5.Results
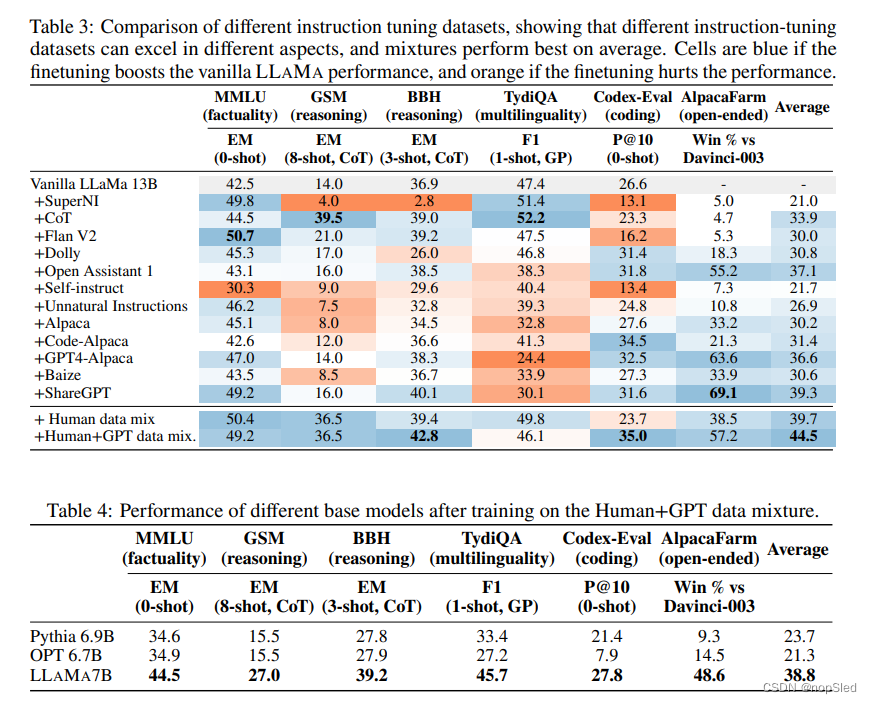
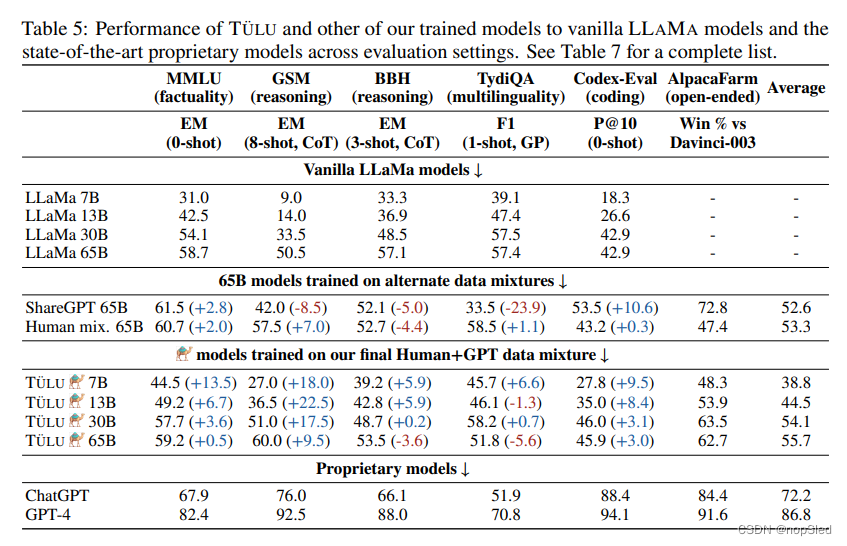
Supplementary Material



这篇关于How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources翻译的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





