原文链接:https://www.cnblogs.com/baochuan/p/9089244.html
背景
提升产品体验,节省用户感知度。——想想,如果看到一堆相似性很高的新闻,对于用户的留存会有很大的影响。
技术方案1、信息指纹算法
思路:为每个网页计算出一组信息指纹(Fingerprint)。比较两个网页相同信息指纹数量,从而判断内容的重叠性。
步骤:
1)提取网页正文信息特征(通常是一组词),并进行向量化处理(权重算法:如nf/df)。
2)取前N个信息特征,进行MD5哈希,得到信息指纹。 优点:算法简单、工程好落地,不会受大数量问题影响。
技术方案2、分段签名算法
算法思路:按规则把网页切成N段,为每一段生成信息指纹。如果这N个信息指纹里面,有M个(阈值)相同, 则认为两者是复制网页。
缺点:小规模比较是很好的算法,对于大规模数据来说,算法复杂度相当高。
方案3、基于关键词的复制网页算法
方案4、基于句子的方式 算法思路:获取标点符号左右两边各2个汉子或英文作为特征,来进行文本表示。
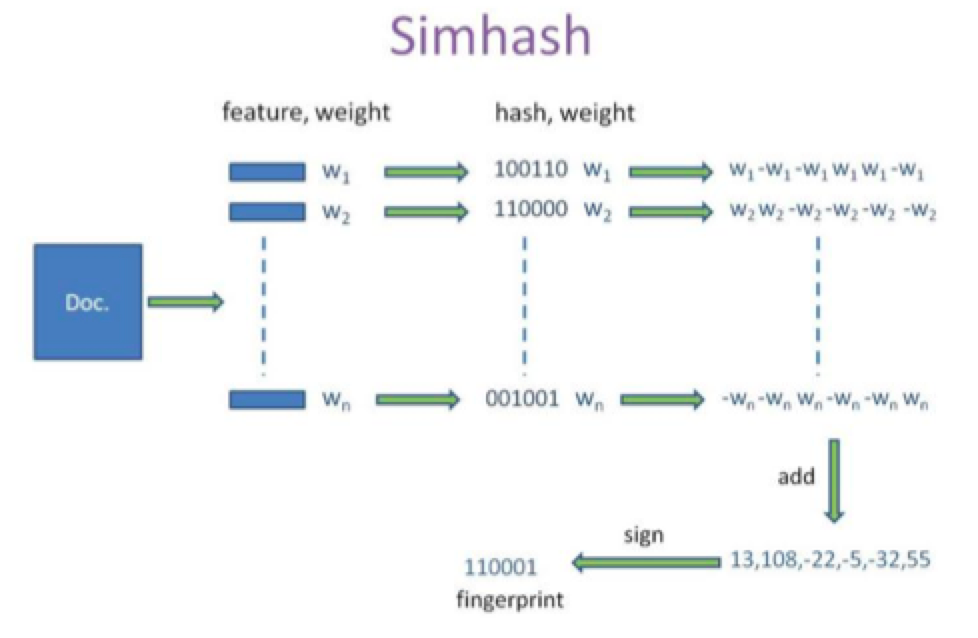
SimHash:局部敏感哈希(locality sensitive hash)
背景介绍:simhash是由 Charikar 在2002年提出来的!
算法思路:主要思想是降维,为每个文档通过hash的方式,生成一个指纹(fingerprint)。
核心思想是将文本相似性问题转换为集合的相似性问题!
设计的目的:是让整个分布尽可能地均匀,形似的内容生成相近的hashcode。——即,hashcode的相似程度要 能直接反应输入内容的相似程度(所以md5等传统hash无法满足需求)。
使用方:Google基于此算法实现网页文件查重。
优点:相对传统文本相似性方法(欧氏距离、海明距离、余弦角度),解决计算量庞大等问题。
缺点:500字以上效果比较明显500字以内,效果不是很理想,可以调整海明距离的n值来调整(3升级为10)
1)分词:提取网页正文信息特征词,形成去掉噪音词(助词、语气词、人称代词)的单词序列,并为每个词加上权重(词出现次数)。
抽取方式:
1.1. 剔除所有英文、数字、标点字符
1.2.分词,并标注词性,仅保留实体词性,如名词、动词;(技巧一!)
1.3.过滤掉常用实体词(常用实体词是通过对历史锐推训练而得,即建立自己的停止词表);(技巧二!)
1.4.计算保留实体词的词频,并以此为权重,选择权重大的词语作为标签;
1.5.标签数组长度大于一个阈值(如3),才认为是有信息量的锐推,否则忽略。(技巧三!)
—其他简单方案:
百度大搜的去重算法比较简单,就是直接找出此文章的最长的n句话,做一遍hash签名。n一般取3。
工程实现巨简单,据说准确率和召回率都能到达80%以上。
2)hash及加权:
对于提取的信息特征词进行hash值运算,转变成bit值,根据每个位是否为1,进行权重加减处理。
权重设定:词频+词位置
3)合并及降维:每个单词的序列值累加,变成只有一个序列串。大于0 记为1,小于0记为0.
1、海明距离阈值选择
模型效果:标题阈值、内容阈值
距离选择,考虑因素:除考虑数据效果之外,还得考虑工程查询效率。
2、提高性能的方式:
把64为simHash码均分为汉明距离n+1块,方便后续查找所有临近simHash码。
SimHash 海明 (Hamming)距离(一)
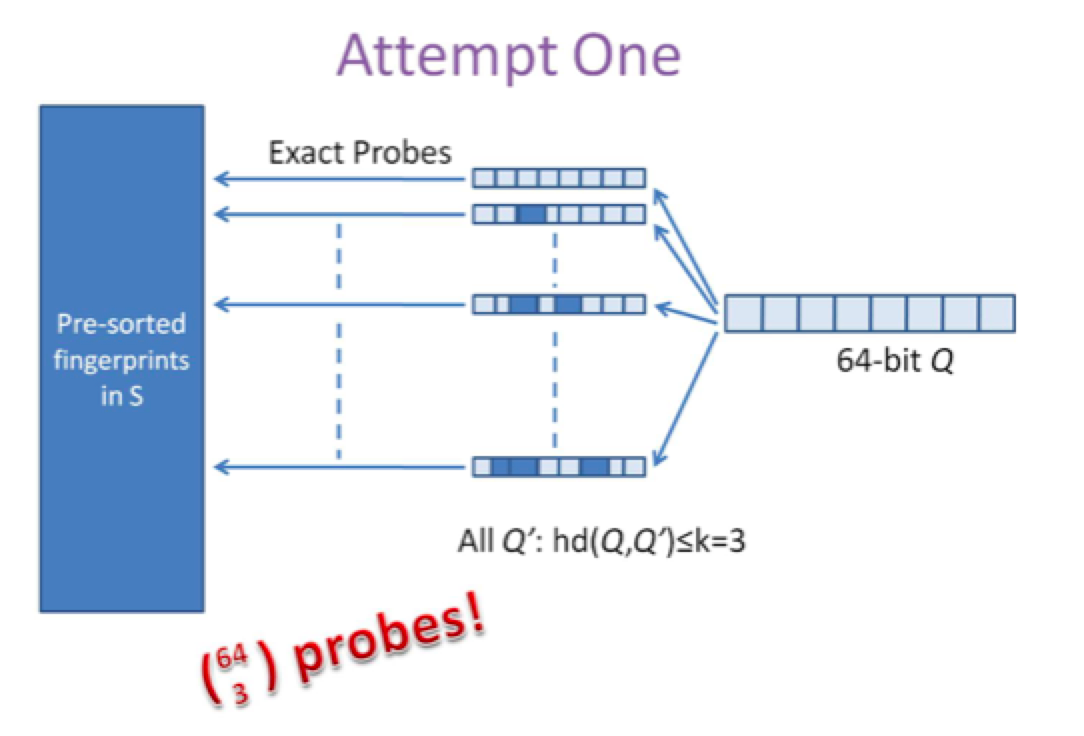
第一种是方案是查找待查询文本的64位simhash code的所有3位以内变化的组合,大约需要四万多次的查询,参考下图:
SimHash 海明 (Hamming)距离(二)
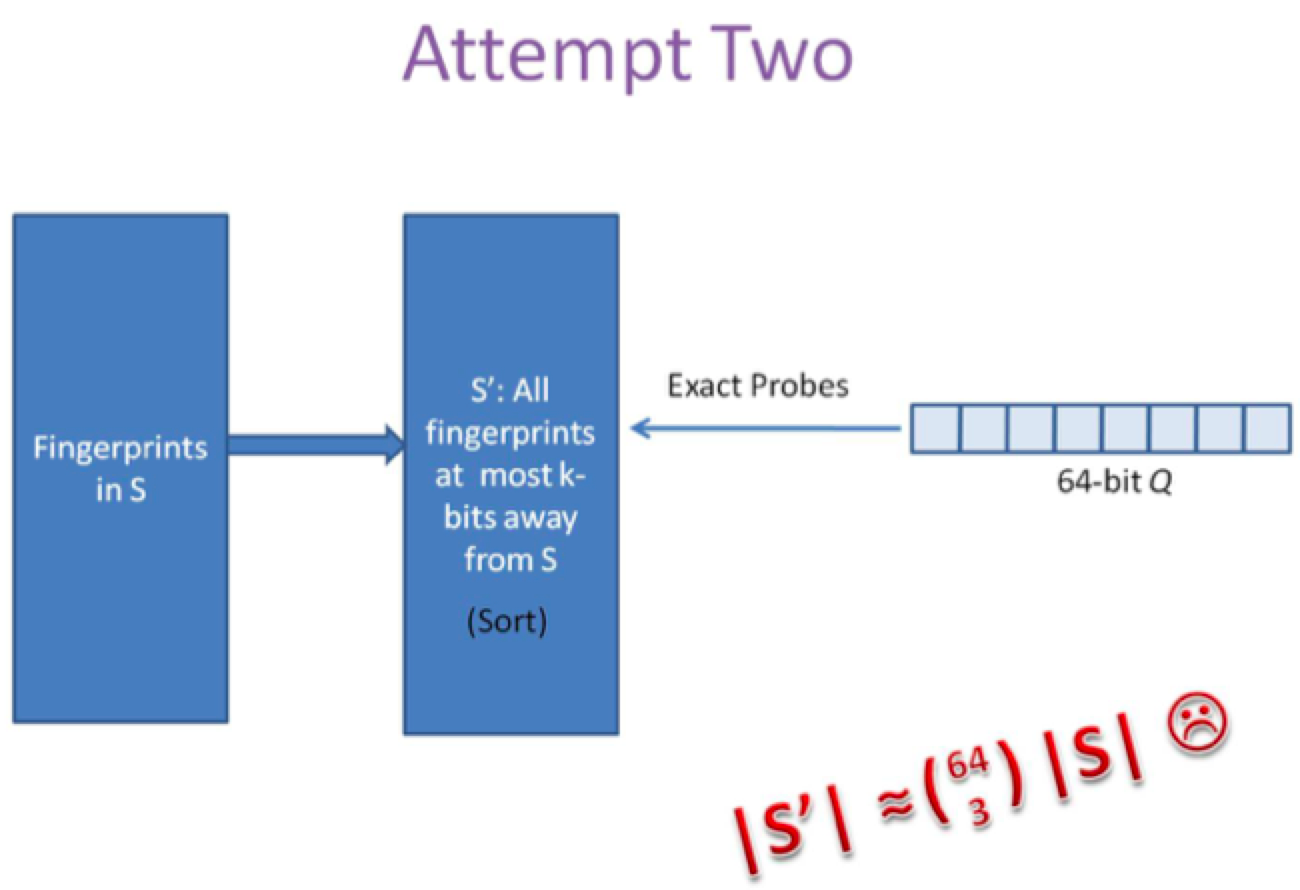
第二种方案是预生成库中所有样本simhash code的3位变化以内的组合,大约需要占据4万多倍的原始空间,参考下图
SimHash 海明 (Hamming)距离一、二方案分析
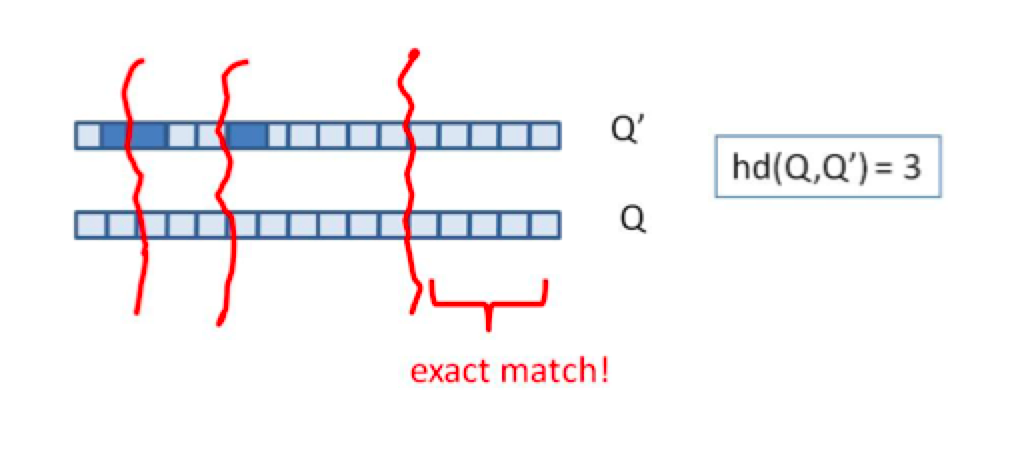
上述两种方法,或者时间复杂度,或者空间复杂度,其一无法满足实际的需求。我们需要一种方法,其时间复杂度优于前者,空间复杂度优于后者。 假设我们要寻找海明距离3以内的数值,根据抽屉原理,只要我们将整个64位的二进制串划分为4块,无论如何,匹配的两个simhash code之间至少有一块区域是完全相同的,如图所示
SimHash 海明 (Hamming)距离(三)
由于我们无法事先得知完全相同的是哪一块区域,因此我们必须采用存储多份table的方式。在本例的情况下,我们需要存储4份table,并将64位的simhash code等分成4份;对于每一个输入的code,我们通过精确匹配的方式,查找前16位相同的记录作为候选记录,如图所示:
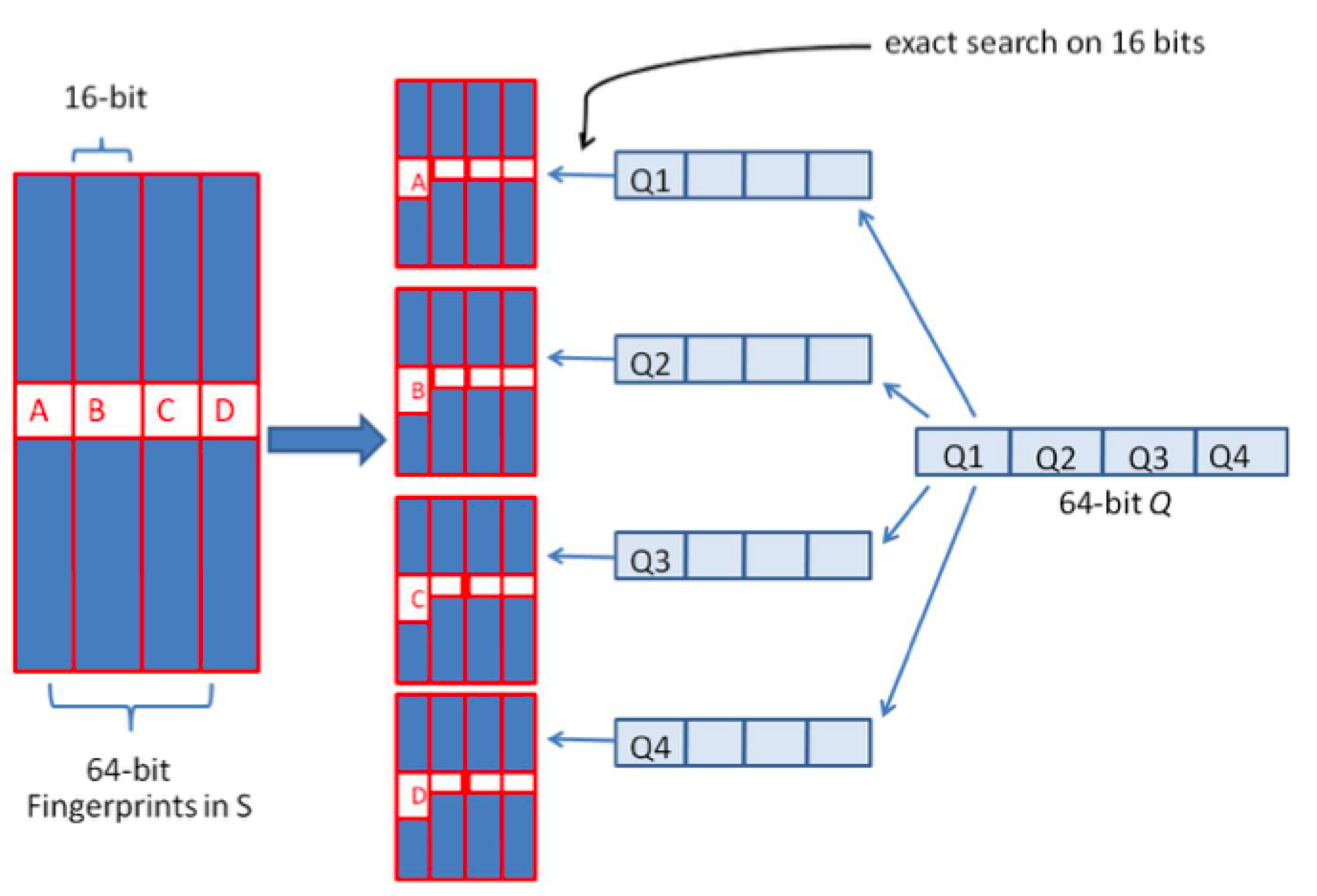
让我们来总结一下上述算法的实质:
1、将64位的二进制串等分成四块
2、调整上述64位二进制,将任意一块作为前16位,总共有四种组合,生成四份table
3、采用精确匹配的方式查找前16位
4、如果样本库中存有2^34(差不多10亿)的哈希指纹,则每个table返回2^(34-16)=262144个候选结果,大大减少了海明距离的计算成本
我们可以将这种方法拓展成多种配置,不过,请记住,table的数量与每个table返回的结果呈此消彼长的关系,也就是说,时间效率与空间效率不可兼得! 这就是Google每天所做的,用来识别获取的网页是否与它庞大的、数以十亿计的网页库是否重复。另外,simhash还可以用于信息聚类、文件压缩等。

SimHash 算法原理
simhash用于比较大文本,比如500字以上效果都还蛮好,距离小于3的基本都是相似,误判率也比较低。但是如果我们处理的是微博信息,最多也就140个字,使用simhash的效果并不那么理想。看如下图,在距离为3时是一个比较折中的点,在距离为10时效果已经很差了,不过我们测试短文本很多看起来相似的距离确实为10。如果使用距离为3,短文本大量重复信息不会被过滤,如果使用距离为10,长文本的错误率也非常高,如何解决?——采用分段函数!
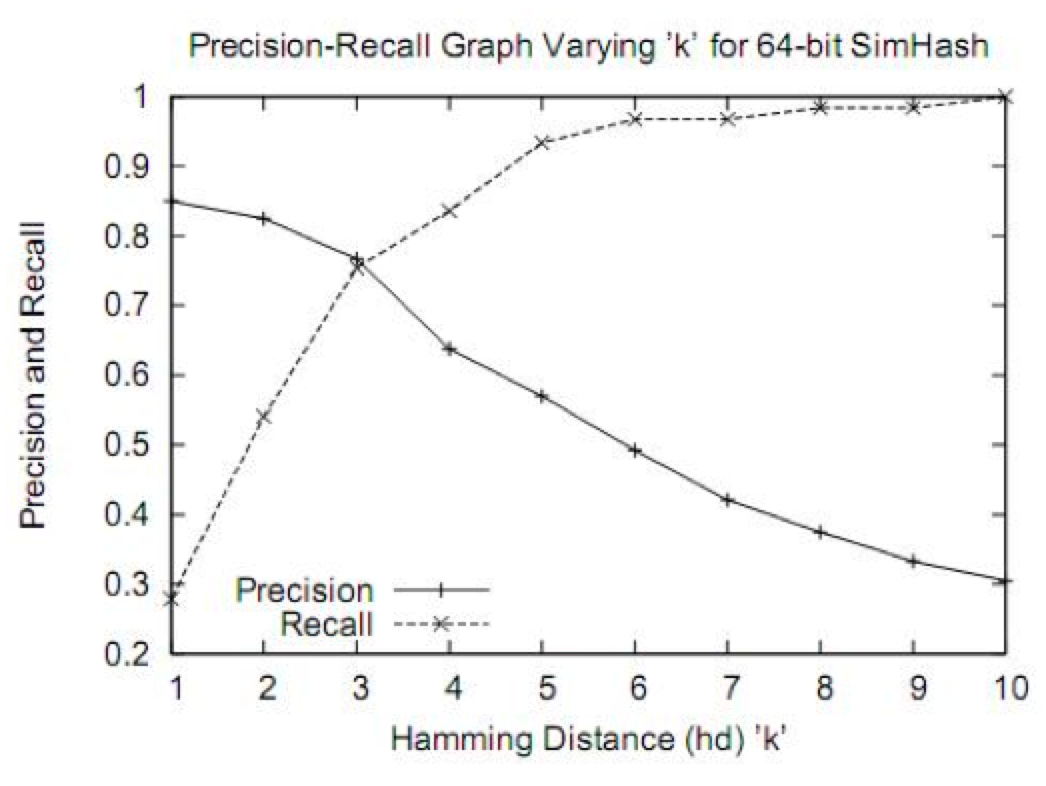
SimHash 算法原理——评估结果
1、dump 一天的新闻数据:
数据项要求:标题、内容、新闻原始地址。
2、评估指标
排重准确率(97%): 数据集:排重新闻集
方式:人工(研发先评估、产品评估)
召回率(75%):
数据集:训练数据集-排重新闻集
方式:扩大海明距离,再进行人工评估
SimHash 算法原理——代码片段
高效计算二进制序列中1的个数:这个函数来计算的话,时间复杂度是 O(n); 这里的n默认取值为3。由此可见还是蛮高效的。

参考资料
中文文档simhash值计算
网页文本的排重算法介绍
海量数据相似度计算之simhash和海明距离
短文本合并重复(去重)的简单有效做法
海明距离查询方案