simhash专题

【java 走进NLP】simhash 算法计算两篇文章相似度
python 计算两篇文章的相似度算法simhash见: https://blog.csdn.net/u013421629/article/details/85052915 对长文本 是比较合适的(超过500字以上) 下面贴上java 版本实现: pom.xml 加入依赖 <dependency><groupId>org.jsoup</groupId><artifactId>jsoup</a

【python 走进NLP】simhash 算法计算两篇文章相似度
互联网网页存在大量的重复内容网页,无论对于搜索引擎的网页去重和过滤、新闻小说等内容网站的内容反盗版和追踪,还是社交媒体等文本去重和聚类,都需要对网页或者文本进行去重和过滤。最简单的文本相似性计算方法可以利用空间向量模型,计算分词后的文本的特征向量的相似性,这种方法存在效率的严重弊端,无法针对海量的文本进行两两的相似性判断。模仿生物学指纹的特点,对每个文本构造一个指纹,来作为该文本的标识,从形式上来

文本相似度计算——Simhash算法(python实现)
互联网网页存在着大量重复内容,必须有一套高效的去重算法,否则爬虫将做非常多的无用功,工作时效性无法得到保证,更重要的是用户体验也不好。业界关于文本指纹去重的算法众多,如 k-shingle 算法、google 提出的simhash 算法、Minhash 算法、百度top k 最长句子签名算法等等,本文主要介绍simhash算法以及python应用. simhash 与传统hash 的区别 传统

simHash 简介以及 java 实现
转自: simHash 简介以及 java 实现 传统的 hash 算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上相当于伪随机数产生算法。产生的两个签名,如果相等,说明原始内容在一定概 率 下是相等的;如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别极大。从这个意义 上来 说,要设计一个 hash 算法,对相
海量数据文本相似度解决方式SimHash+分词方法+基于内容推荐算法
之前找实习的时候被问到海量数据文本相似度怎么解决,当时很懵,在面试官的引导下说出了hash table+排序的方法(是的,我总能智障出新花样),当时想的是先做分词再做哈希,然后对标记哈希后的词(这时已是数字)进行排序通过共同的数字来度量它们的好坏。 在翻之前的面试笔记突然看到这个,就来网上找找解决方案,发觉hash没有问题,但后面的确是跑偏了。 常规的解法是SimHash,通过对分好的词进行h
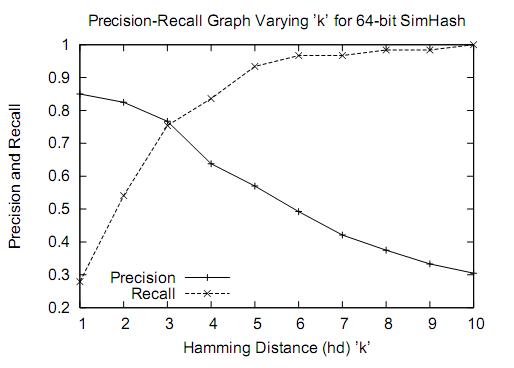
simhash进行文本查重
http://blog.csdn.net/lgnlgn/article/details/6008498 有1亿个不重复的64位的01字符串,任意给出一个64位的01字符串f,如何快速从中找出与f汉明距离小于3的字符串? 大规模网页的近似查重 主要翻译自WWW07的Detecting Near-Duplicates for Web Crawling WWW上存在大量内容近
![集成多元算法,打造高效字面文本相似度计算与匹配搜索解决方案,助力文本匹配冷启动[BM25、词向量、SimHash、Tfidf、SequenceMatcher]](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)
集成多元算法,打造高效字面文本相似度计算与匹配搜索解决方案,助力文本匹配冷启动[BM25、词向量、SimHash、Tfidf、SequenceMatcher]
搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源) 专栏详细介绍:搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源) 前人栽树后人乘凉,本专栏提供资料: 推荐系统算法库,包含推荐系统经典及最新算法讲解,以及涉及后续业务落地
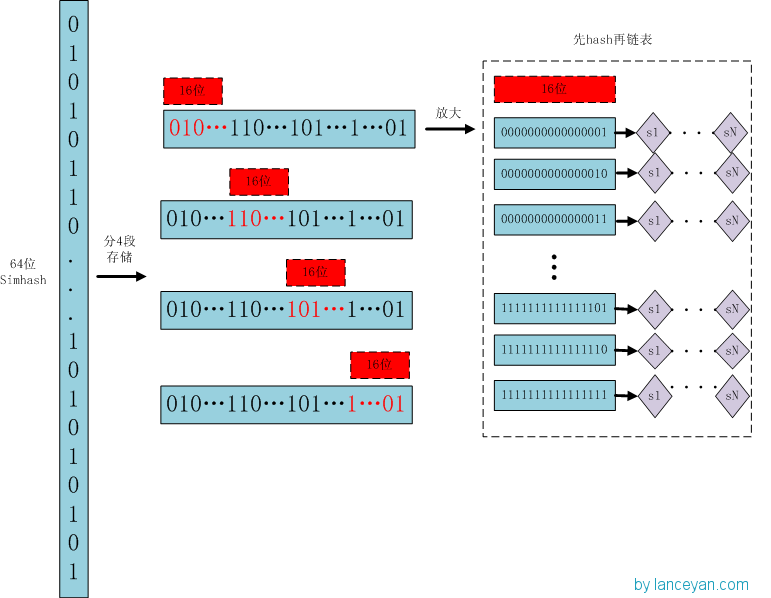
关于SimHash去重原理的理解(能力工场小马哥)
阅读目录 1. SimHash与传统hash函数的区别2. SimHash算法思想3. SimHash流程实现4. SimHash签名距离计算5. SimHash存储和索引6. SimHash存储和索引7. 参考内容 在之前的两篇博文分别介绍了常用的hash方法([Data Structure & Algorithm] Hash那点事儿)以及局部敏感hash算法([Algorithm]

文本相似性算法:Simhash算法原理及实践
simhash(局部敏感哈希)的原理 simhash的背景 simhash广泛的用于搜索领域中,也许在面试时你会经常遇到这样的问题,如果对抓取的网页进行排重,如何对搜索结果进行排重等等。随着信息膨胀时代的来临,算法也在不断的精进,相似算法同样在不断的发展,接触过lucene的同学想必都会了解相似夹角的概念,那就是一种相似算法,通过计算两个向量的余弦值来判断两个向量的相似性,但这种方式需

simhash文章排重
原文链接:https://www.cnblogs.com/baochuan/p/9089244.html 背景 提升产品体验,节省用户感知度。——想想,如果看到一堆相似性很高的新闻,对于用户的留存会有很大的影响。 技术方案1、信息指纹算法 思路:为每个网页计算出一组信息指纹(Fingerprint)。比较两个网页相同信息指纹数量,从而判断内容的重叠性。 步骤: 1)