本文主要是介绍一篇短小精悍的文章让你彻底明白KMP算法中next数组的原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
以后保持每日一更,由于兴趣较多,更新内容不限于数据结构,计算机组成原理,数论,拓扑学......,所谓:深度围绕职业发展,广度围绕兴趣爱好。往下看今日内容
一.什么是KMP算法
KMP(Knuth-Morris-Pratt)算法是一种字符串匹配算法,用于在一个较长的文本串中查找一个模式串的出现位置。
二.KMP算法的应用
这个算法在很多应用中都有重要的作用:
-
字符串搜索:KMP算法可以快速在一个长文本中查找一个关键词或者子串的出现位置。因为KMP算法在匹配失败时利用了先前已经匹配过的信息,避免了不必要的回溯,提高了搜索效率。
-
文件比较:比如两个文本文件的比较,KMP算法可以用于找到两个文件中相同的部分或者相似的部分,从而进行比较或者合并。
-
DNA序列匹配:在生物信息学中,KMP算法可以应用于DNA序列比对和DNA片段的查找,这对于基因研究和遗传工程非常重要。
-
编辑器中的查找和替换:很多文本编辑器在实现查找和替换功能时会使用KMP算法,用于快速定位和匹配模式串。
三.KMP算法next数组原理(非常重要)
在字符串匹配的KMP算法中,求模式串的next数组值的定义如下:
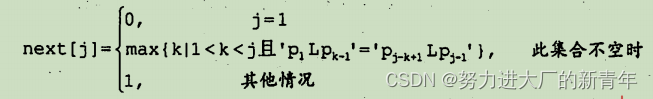
问:
1)当 j=1时,为什么要取next[1]=0 ?
2)为什么要取max{k},k的最大值为多少?
3)其他情况是什么情况,为什么next取next[j]=1?
解:
1)当模式串中的第一个字符与主串中的第一个字符不匹配时,next[1]=0,表示模式串应该右移一位,主串当前指针往后移动一位,再和模式串的第一个字符进行比较。
2)当主串的第i个字符与模式串的第j个字符不匹配时,主串i不回溯,也就是不向前移动,则假定模式串的第k个字符与主串的第i个字符比较,k值应满足条件1<k<j,并且’p1 p2 ......p(k-1)'='p(j-k+1)p(j-k+2)......p(j-1),即k为模式串的下次比较的位置。k的取值可能有多个,为了不使右移丢失可能的匹配,右移的距离应该取最小,由于j-k表示右移的距离,所以取max{k}。k的最大值为j-1。
3)除了上面两种情况外,发生不匹配时,主串指针i不回溯,在最坏的情况下,模式串从第1个字符开始与主串的第i个字符比较。
四.总结
KMP算法与朴素匹配最明显的一个特点就是,KMP算法很绝,它觉得,过去的事情就让它过去,不必回头,简称“一往无前”。然而,朴素匹配算法很委婉,很想回头挽留,可是最终受伤的总是自己,简称“不堪回首”。
可见,KMP算法是一个高效率,代码简洁,逻辑性巧妙的算法。
这篇关于一篇短小精悍的文章让你彻底明白KMP算法中next数组的原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







