本文主要是介绍如何运用R语言在生物群落生态学中的数据统计分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
R 语言作的开源、自由、免费等特点使其广泛应用于生物群落数据统计分析。生物群落数据多样而复杂,涉及众多统计分析方法。本次以生物群落数据分析中的最常用的统计方法回归和混合效应模型、多元统计分析技术及结构方程等数量分析方法为主线,通过多个来自经典研究中的实例,详细讲述各方法的R语言实现途径。主要特点为聚焦群落生态学研究领域,从R语言基础操作和作图、数据准备整理,到各种数量分析方法的应用情景分析,实现从数据整理到分析结果表达的完整的科学研究数据分析及结果展示的全过程
阅读全文点击《如何运用R语言在生物群落生态学中的数据统计分析》
专题一:统一基础:R入门及Rstudio
1) R及Rstudio介绍:背景、软件及程序包安装、基本设置等
2) R语言基本操作,包括向量、矩阵、数据框及数据列表等生成和数据提取等
3) R语言数据文件读取、整理(清洗)、结果存储等(含tidverse)
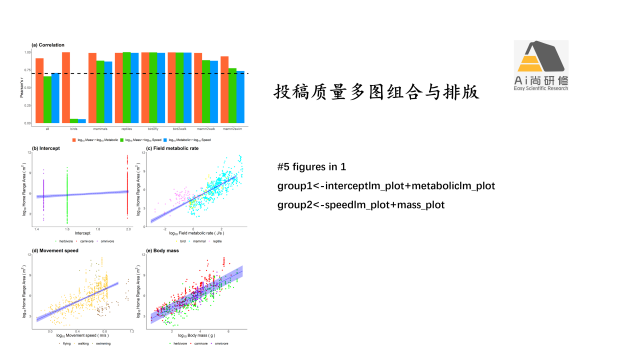
4) R语言基础绘图(含ggplot):基本绘图、排版、发表质量绘图输出存储

专题二:群落数据准备及探索分析
1) 生物群落数据准备:物种组成、环境变量、物种功能属性、系统发育树等
2) 生物群落数据检查:缺失值和离群值(outliers)等-避免模型错进错出(GIGO)
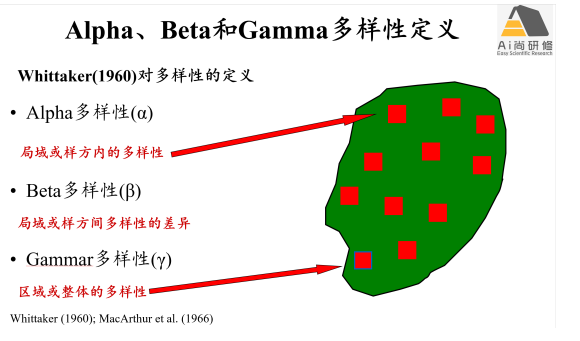
3) 物种多样性计算:物种多样性(TD)、功能多样性(FD)和系统发育多样性(PD)
4) 物种相似/相异矩阵关联测度介绍


专题三:群落数据分组分析: 等级/非等级聚类(HC/NHC)、PERMANOVA、MRPP
1) 生物群落数据的聚类及差异分析
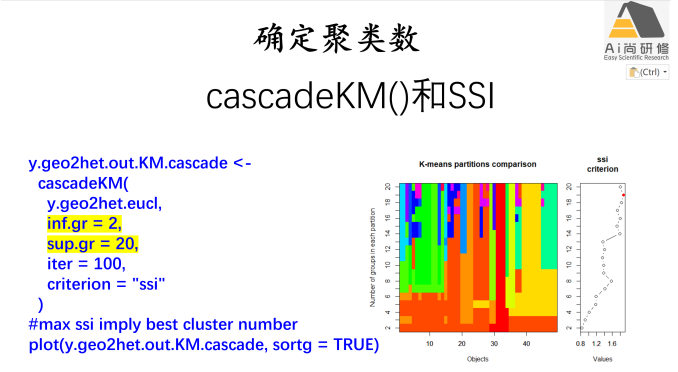
2) 案例1鸟类生境数据的等级和非等级聚类:KMEANS和HCLUST
3) 案例2乌龟适宜生境差异检验(2组比较)及解释:PERMANOVA、MRPP、ANOSIM及Dispersion test
4) 案例3环境梯度下微生物组成差异分析(多组比较)及解释:MRPP及Dispersion Test

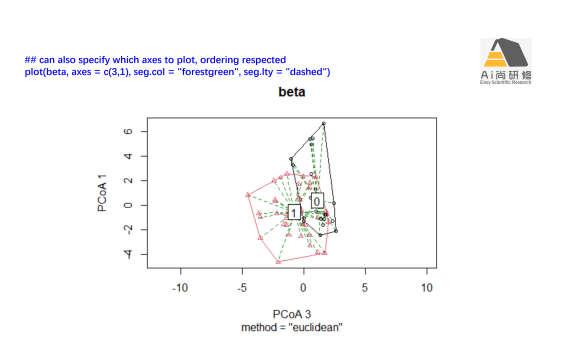
专题四:群落数据排序上:非约束排序-PCA、CA、PCoA、NMDS
1)生物群落数据非约束排序分析
2)案例1鱼类生境数据排序:PCA
3)案例2鸟类物种组成数据的排序:CA、PCoA和NMDS比较
4)案例3 药物对肠道微生物群落影响:PCoA+PERMANOVA+ggplot
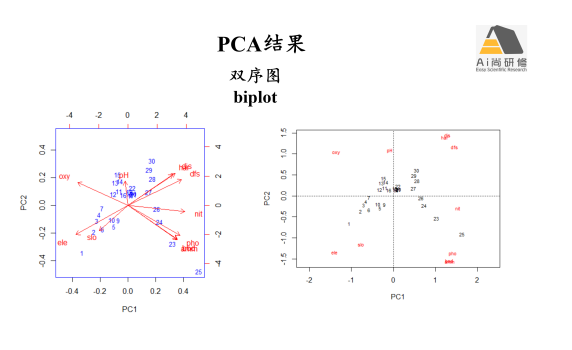
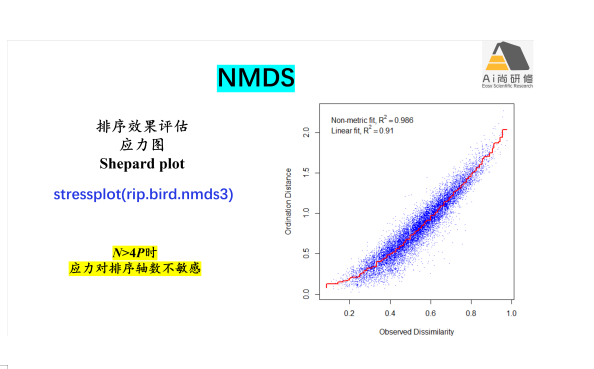
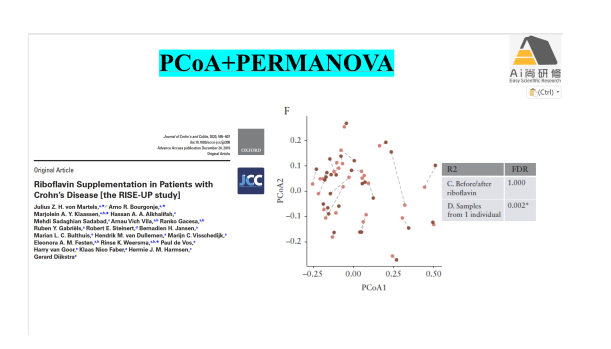
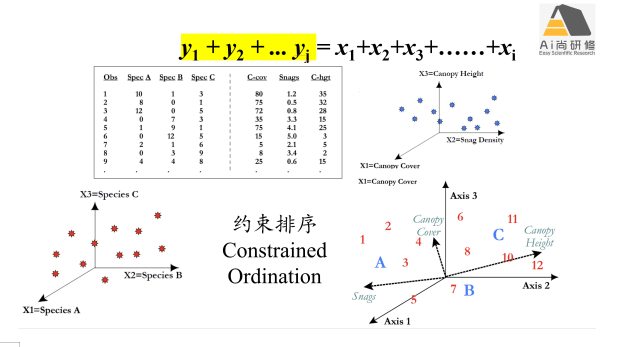
专题五:群落数据排序下:约束排序-RDA、dbRDA、CCA、第四角分析(4th Corner)
1) 生物群落数据约束排序:非对称约束排序VS对称约束排序
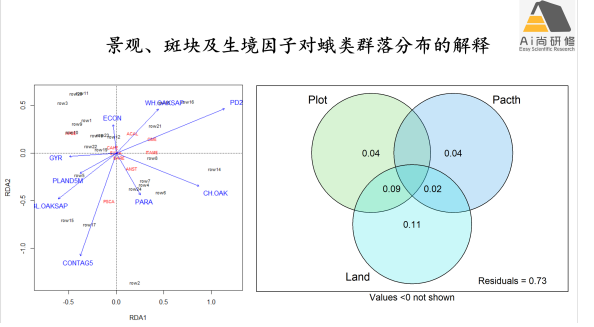
2) 案例1景观、斑块及生境因子蛾类群落分布的解释:RDA、dbRDA或CCA选择+变差分解
3) 案例2物种有无(0,1)数据约束排序:dbRDA
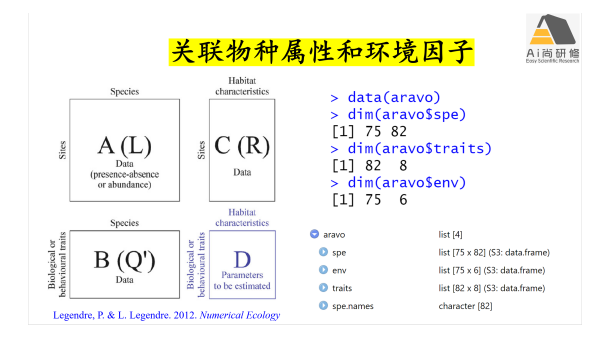
4) 案例3物种组成、物种属性及环境因子的相关分析-第四角分析(4th Corner)
专题六:一般线性模型(lm)与广义线性模型(glm)-正态与非正态数据分析
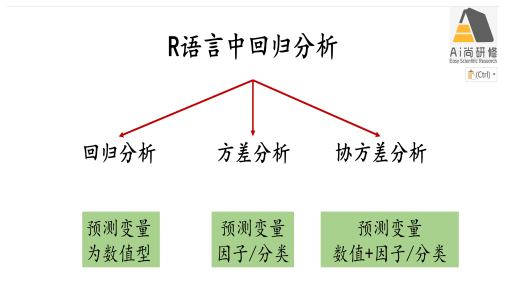
1) 一般线性模型与广义线性模型原理及比较
2) 案例1不同鱼类游速的回归、方差及协方差分析(lm)
3) 案例2有无(0,1)数据的逻辑斯蒂模型-二项分布(glm)
4) 案例3物种多度分布环境解释-计数数据泊松、负二项、零膨胀、零截断模型(glm)

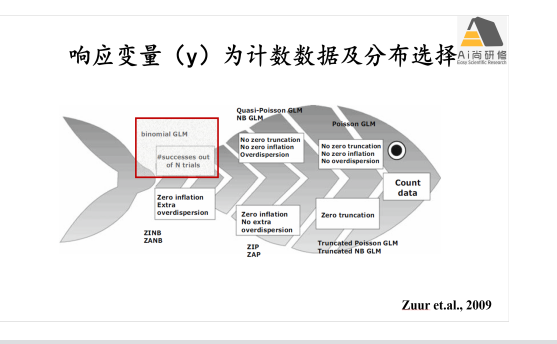
专题七:线性混合效应模型(lmm)与广义线性混合效应模型(glmm)-数据分层与嵌套分析
1) 混合效应的原理及分析流程与案例解析
2) 案例1分层数据物种多样性决定因素:线性混合效应模型(lmm)
3) 案例2蝌蚪“变态”与否(0,1)的多因素分析:广义线性混合效应模型(glmm)
4) 计数数据广义线性混合效应模型(glmm)
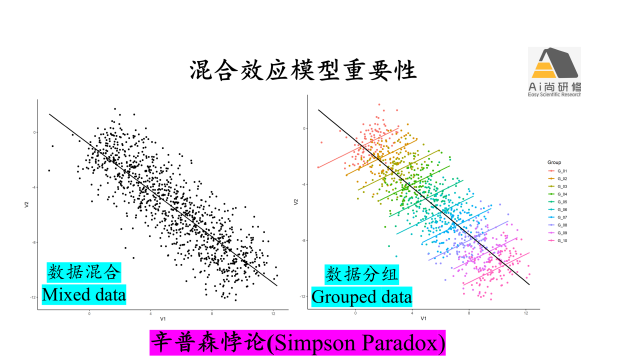

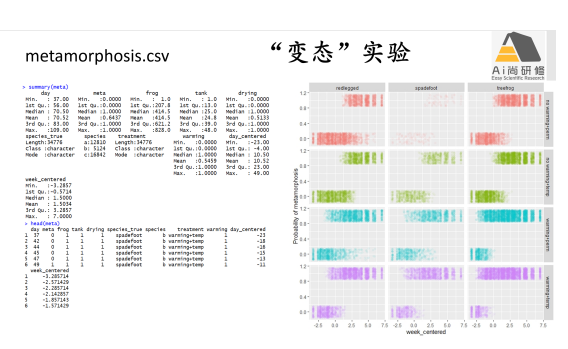
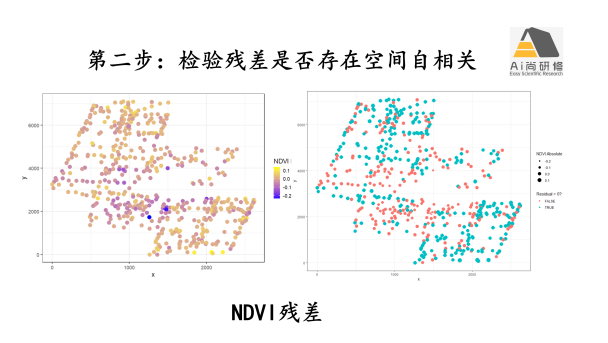
专题八:空间、时间及系统发育相关回归-数据自相关(autocorrelation)问题分析
1) 数据自相关问题:时间、空间和系统发育相关讲解
2) 案例1森林植物多样性分布格局的空间自相关修正
3) 案例2不同年份鸟类多度的时间自相关修正
4) 案例3系统发育相关在虾类多度分布分析中作用


专题九:结构方程模型(SEM):lavaan和piecewiseSEM-多变量直接和间接效应及因果关系
1)结构方程模型:定义、应用、估计方法、模型可识别规则及样本量要求等
2)案例1群落物种丰富度恢复的直接及间接效应(direct and indirect effects):SEM分析基本流程-lavaan vs piecwiseSEM
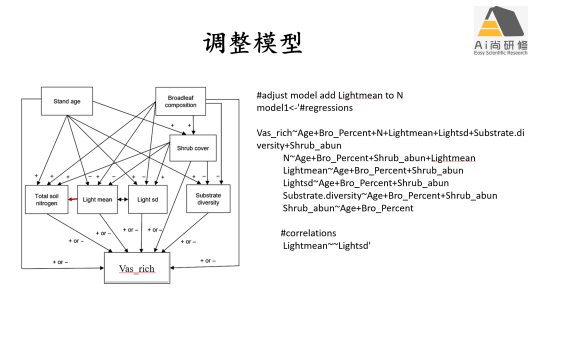
3)案例2环境异质性和资源可获得性对不同演替阶段林下维管植物多样性的影响:模型调整、比较、评估及结果展示
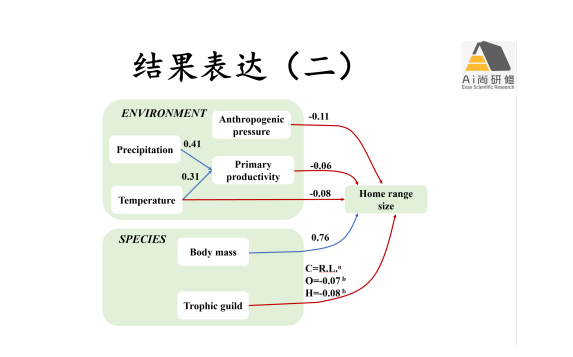
4)案例3人类活动、环境条件、物种属性对动物领域大小相对贡献(relative roles):分层数据、混合模型、分组分析及分类变量SEM实现

专题十:群落数据及统计分析结果作图(ggplot)排版及发表质量图输出
1) 群落数据及统计分析结果作图数据准备:结果提取、整理
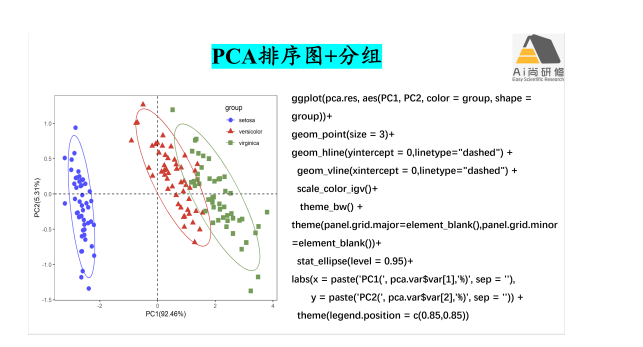
2) PCA、CA、PCoA及NMDS等非约束排序图:排序图和双序图(biplot)
3) RDA、db-RDA及CCA等约束排序图:三序图(triplot)和韦恩图(venn)
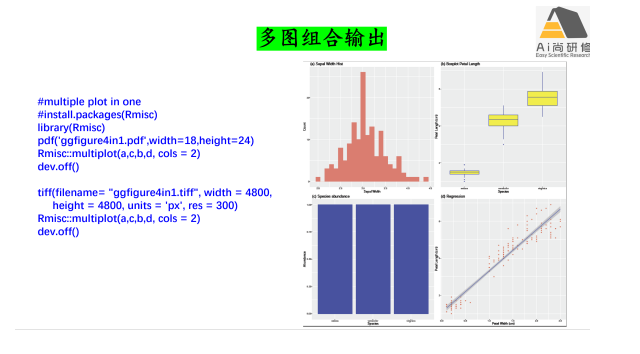
4) 回归和混合效应模型分析结果图:散点图、箱线图、柱状图及提琴图等
5) 结构方程模型结果图表达方式
这篇关于如何运用R语言在生物群落生态学中的数据统计分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







