本文主要是介绍使用Chisel搭建Systolic Array,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近听到非常多人吹Chisel,为了方便快速做算法实现,就去尝试学了下,发现确实很香,有种相见恨晚的感觉。
今天是使用Chisel搭建个脉动阵列(Systolic Array, SA)[1],脉动阵列是神经网络中最基础也是最常用的组件之一。它主要是实现高效的矩阵乘法,而神经网络中到处都是矩阵乘法,从全连接层到卷积层(GEMM),都可以用矩阵乘法表示。UCB的Chipyard中专门集成了个脉动阵列的生成器Gemmini。
Gemmini考虑了很多的场景,比较复杂。本实现在参考Gemmini的基础上实现了个基础功能的用于全连接层的Weight-stationary的脉动阵列,即权重存储在PE内,只有输入激励在脉动阵列里传输。这样可以简化权重的加载。
SA是由许多个PE(Processing Element)组成的,每个PE执行的是乘加运算,然后将部分和的结果打拍后放入下一个PE,下一个PE将乘法结果与部分和相加得到新的部分和后传递到再下一个PE。最终在每列的最后一个PE得到总和结果,也就是一个神经元的输出。
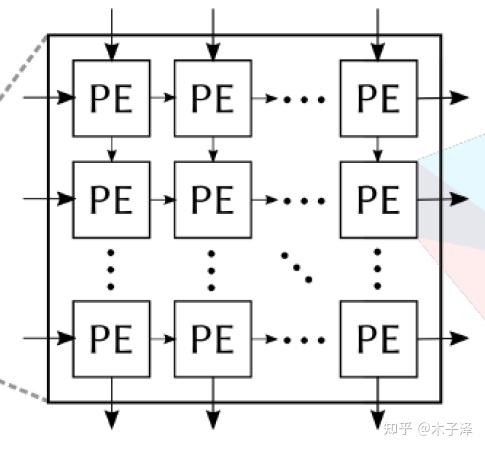
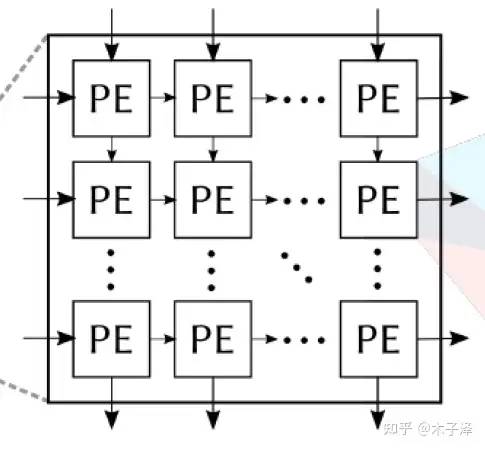
本实现中的PE采用的是Weight-Stationary架构,如下图所示。Weight存储在Register中,Weight与输入的Input Activation相乘的结果再与上方PE的部分和结果相加,再传入下一个PE,其中的MUX的目的是让部分和与权重共用一组总线,这样可以节省布线资源。在加载权重时,就不让部分和传递,而是让权重一层层传递下去。(注:这里没有将下方和右方的Register画出来)
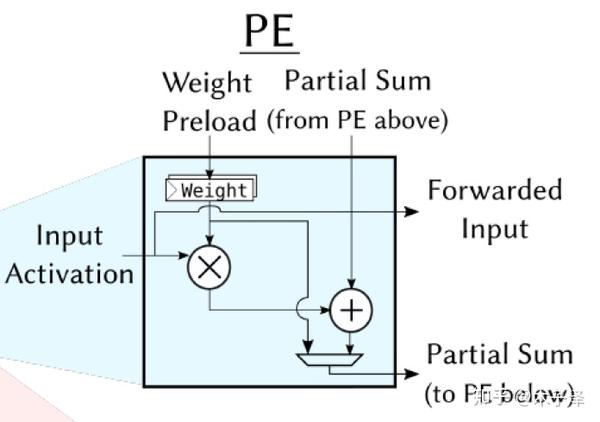
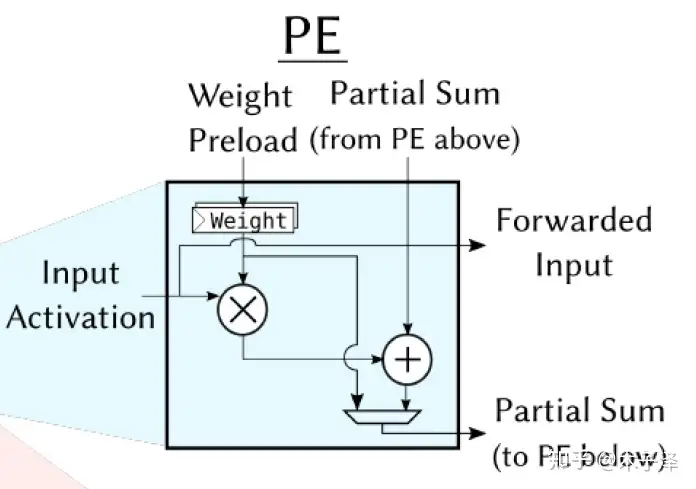
与Weight-Stationary相对的有Ouput-Stationary架构,就是每个PE中存储的是Output Activation,由于没有做实现,因此不展开叙述了。
首先实现PE,Chisel代码如下。这里默认读者有点Chisel基础,可以参考Chisel-book[2],并跑完Chisel Bootcamp[3]做入门学习。下面代码定义了5个输入输出,包括输入的激励inAct,传递到右边PE的输入激励的打拍结果outAct,权重和部分和Partial Sum共用的输入和输出线inWtPS和outWtPS,还有个inwtValid信号是告诉PE当前应该传递权重而不是部分和。这里将激励位宽与权重位宽作为了可配置的参数actWidth和weightWidth。
import chisel3._
import chisel3.util._
class PE(actWidth: Int = 16, weightWidth: Int = 16) extends Module{val io = IO(new Bundle{val inAct = Input(SInt(actWidth.W))val inWtPS = Input(SInt((actWidth+weightWidth).W))val outWtPS = Output(SInt((actWidth+weightWidth).W))val outAct = Output(SInt(actWidth.W)) // 向右传递
val inwtValid = Input((UInt(1.W))) })val parSumWidth = actWidth + weightWidth;// 不要初始化,避免复位
val weightReg = Reg(SInt(weightWidth.W))val actReg = Reg(SInt(actWidth.W))val parSumReg = Reg(SInt(parSumWidth.W))actReg := io.inAct;parSumReg := io.inWtPS + weightReg * actReg;io.outAct := actReg;// 会自动截低位,不用担心位宽,甚至还会在高位补符号位(有符号数)和0(无符号数)
when(io.inwtValid === 1.U){weightReg := io.inWtPSio.outWtPS := weightReg} .otherwise {weightReg := weightRegio.outWtPS := parSumReg}
}然后是实现Systolic Array,也就是例化多个PE,这里例化的个数由meshRows和meshColumns决定,分别表示Systolic Array的高度和宽度。例化时采用了fill函数,即List中有meshRows个元素,每个元素也是个List,含有meshColumns个PE,因此总PE个数是meshRows * meshColumns。
然后就是inwtValid线连接到每个PE上,这里使用了Scala的语法糖foreach(Scala推荐函数式编程,能不用for循环就不用for循环),在PEs.foreach(_.foreach(_.io.inwtValid := io.inwtValid)) 中,第一个foreach表示对每个PEs的元素(也是个List)做操作,操作仍然是_.foreach,因为List内每个元素仍然是个List,第二个foreach才是对单个PE做操作,指定inwtValid的连接。
import chisel3._
import chisel3.util._
class SystolicArray(actWidth: Int = 16, weightWidth: Int = 16,meshRows: Int = 4, meshColumns: Int = 4) extends Module{val io = IO(new Bundle{val inAct = Input(Vec(meshRows, SInt(actWidth.W)))val inWeight = Input(Vec(meshColumns, SInt(weightWidth.W)))val outSum = Output(Vec(meshColumns, SInt((actWidth+weightWidth).W)))val inwtValid = Input((UInt(1.W)))})val parSumWidth = actWidth + weightWidth; // PEs(r)(c)表示第r行,第c列的PE,从0开始
val PEs: Seq[Seq[PE]] = Seq.fill(meshRows, meshColumns)(Module(new PE(actWidth, weightWidth)))PEs.foreach(_.foreach(_.io.inwtValid := io.inwtValid));for(row <- 0 until meshRows){for(col <- 0 until meshColumns){// 第一行的输入连接到SA端口
if(row == 0) PEs(row)(col).io.inWtPS := io.inWeight(col)else PEs(row)(col).io.inWtPS := PEs(row-1)(col).io.outWtPS// 最后一行的输出连接到模块外
if(row == meshRows-1) io.outSum(col) := PEs(row)(col).io.outWtPS // 第一列
if(col == 0) PEs(row)(col).io.inAct := io.inAct(row)else PEs(row)(col).io.inAct := PEs(row)(col-1).io.outAct}}
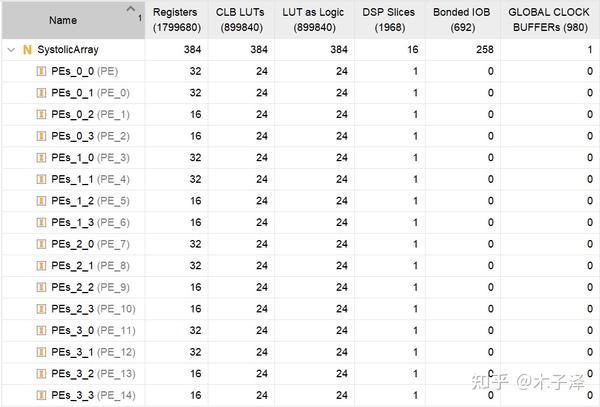
}使用vivado综合生成出来,占用资源如下,每个PE占用一个DSP
参考
- ^论文 http://www.eecs.harvard.edu/~htk/publication/1982-kung-why-systolic-architecture.pdf
- ^Chisel-book https://github.com/schoeberl/chisel-book
- ^Chisel Bootcamp https://github.com/freechipsproject/chisel-bootcamp
link
这篇关于使用Chisel搭建Systolic Array的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




