本文主要是介绍cmip6数据处理之降尺度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
专题一 CMIP6中的模式比较计划
1.1 GCM介绍全球气候模型(Global Climate Model, GCM),也被称为全球环流模型或全球大气模型,是一种用于模拟地球的气候系统的数值模型。这种模型使用一系列的数学公式来描述气候系统的主要组成部分,包括大气、海洋、冰冻土壤以及地表和海洋表面的生物地理过程。
GCM在空间和时间上的精度可以根据需求进行调整,通常的分辨率可以从几百公里到几公里,时间步长可以从几分钟到几小时。

阅读原文
1.2 CMIP介绍
CMIP,全称为气候模型比较计划(Climate Model Intercomparison Project),是由世界气候研究计划(World Climate Research Programme,WCRP)发起的一个国际合作项目。其目的是通过收集和比较各种全球气候模型(GCMs)的模拟结果,以理解过去的、现在的和未来的气候变化。
1.3相关比较计划介绍

专题二 数据下载
2.1方法一:手动人工

利用官方网站
2.2方法二:自动利用Python的命令行工具
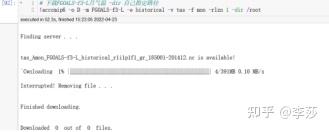
2.3方法三:半自动购物车

利用官方网站
2.4 裁剪netCDF文件
基于QGIS和CDO实现对netCDF格式裁剪

QGIS中的操作

裁剪效果
2.5 处理日期非365天的GCM以BCC为例处理
专题三 基础知识
3.1 Python基础
Python 是一种高级的、解释型的编程语言,其语法简洁明了,适合快速开发。在大气科学中,Python 以其丰富的科学计算和数据分析库备受青睐。这些库如 Numpy,Scipy,Pandas 和 Xarray 等,为处理大气科学数据提供了强大的支持。
●Numpy:Numpy 是 Python 中用于科学计算的核心库,提供了高性能的多维数组对象及相关工具。对于大气科学数据的处理,例如温度、压力、风速等通常都会使用到多维数组。Numpy 提供了丰富的函数库来处理这些数组,包括数学运算、逻辑运算、形状操作、排序、选择等操作。
●Scipy:Scipy 是基于 Python 的开源软件,用于科学计算中的数值积分和微分方程数值求解,线性代数,优化,信号处理等。在大气科学中,例如对气温、气压等数据进行傅立叶分析,求解大气动力学中的偏微分方程等,都可以使用 Scipy 来实现。
●Pandas:Pandas 是基于 Numpy 构建的,使数据清洗和分析工作变得更快更简单。Pandas 是专门为处理表格和混杂数据设计的,而 Numpy 更适合处理统一的数值数组数据。在大气科学中,例如对气象站的观测数据进行时间序列分析,处理混合类型的气象数据,以及对数据进行清洗、筛选和统计等操作,Pandas 都是非常有用的工具。
3.2 CDO基本操作
CDO(Climate Data Operator)是大气科学领域常用的一款气候和气象数据处理工具。它是一个功能强大的命令行工具,可以处理和分析格网和无格网数据,支持多种数据格式,包括netCDF、GRIB、SERVICE, EXTRA和IEG。CDO提供了一套丰富的函数库,可以用来进行各种常见的数据操作,
包括:●基础操作:如选择、提取和修改变量、维度、属性等。
●数值操作:如四则运算、统计运算、函数运算等。例如,可以计算数据的平均值、最大值、最小值、标准差等。●空间操作:如重新格网、插值、汇总、选择和提取地理区域等。
●时间操作:如选择和提取时间周期、计算时间平均或累积等。
3.3 Xarray的基本操作
Xarray 是一个用于处理多维数组数据的 Python 库,它在 numpy 的基础上提供了一系列用于数据操作和分析的高级接口,并能很好地支持 netCDF 这类基于网络的自描述数据格式,因此在大气科学和气候科学中被广泛使用。
Xarray 的主要特点包括:
●基于标签的数据操作:Xarray 使用维度名称而不是轴编号进行数据选择和操作,极大地增强了代码的可读性和可维护性。
●自动对齐数据:在进行运算时,Xarray 可以自动对齐不同数据集的变量(variables)和坐标(coordinates)。●分组运算和数据透视:Xarray 支持类似于 pandas 的分组运算(group-by)和数据透视(pivot)功能。
●l/O操作:Xarray 对多种数据格式提供了非常好的支持,尤其是对 netCDF 数据的读取和写入。
专题四 单点降尺度
4.1 Delta方法

Delta方法(Delta Change Method),也称为增量方法或差值方法,是气候模型降尺度的一种简单而常用的方法。该方法假设气候变化的幅度在未来相对于历史期间将保持恒定。因此,对于某一具体的未来时段,可以通过计算过去和现在气候的差值(即 delta),并将其应用到未来的气候预测上,来预估未来的气候状态。该方法可以应用于温度和降水等气候变量的预测。
4.2统计订正
概率分布函数(Probability Density Function, PDF)的订正。
这种方法的基本思想是:通过修改大尺度模型输出的PDF,使其更符合观测数据的PDF,从而获得更准确的小尺度气候变量。

4.3机器学习方法
降尺度是将粗尺度的全球气候模型(GCM)输出数据转换为地面更精细尺度的过程。机器学习方法因其在处理复杂模式识别和高维数据问题的强大能力,已经被成功应用于降尺度技术。在气候学领域,机器学习已被成功用于将粗尺度的气候模型输出(例如,温度和降水)与其他环境变量(例如,地形和土壤类型)关联,以获得更高分辨率的气候预测。
实现步骤
●建立特征
● 建立模型
●模型评估

4.4多算法集成方法多算法的集成


贝叶斯模型平均 (Bayesian Model Averaging, BMA)
贝叶斯模型平均是一种统计方法,用于根据观察数据确定各种模型的后验概率。与选择一个最好的模型相反,贝叶斯模型平均考虑了所有可能的模型,然后根据每个模型的后验概率进行加权平均。Python+pymc3实现
专题五 统计方法的区域降尺度
5.1 Delta方法

5.2 基于概率订正方法的
专题六 基于WRF模式的动力降尺度
动态降尺度通常使用更高分辨率的区域气候模型(RCM),这些模型在更大尺度的全球气候模型驱动下运行。其中,WRF(Weather Research and Forecasting)模型是目前使用最广泛的区域气候模型之一。 WRF模型是一个灵活的、大气环流模型,适合用于各种尺度的气候和气象研究。它的主要特点是具有高分辨率(可达到几公里),并且可以考虑到许多重要的地球物理过程,如云的形成、降水、陆面过程、海洋过程、边界层过程、辐射、化学过程等。
6.1制备CMIP6的WRF驱动数据
利用cdo工具对gcm的输出文件进行重新编码制备wrf的驱动数据
6.1.1针对压力坐标系的数据制备
6.1.2针对sigma坐标系GCM数据制备
6.1.3 WPS处理

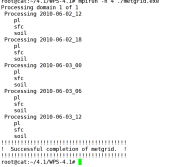
6.2 WRF模式运行
![]()
6.3 模式的后处理
● 提取变量
●变量的统计
●变量的可视化


专题七 典型应用案例-气候变化1
7.1针对风速进行降尺度

7.2针对短波辐射降尺度

专题八 典型应用案例-气候变化2ECA极端气候指数计算
ECA (European Climate Assessment) 是欧洲的一个气候评估项目,其在全球范围内发布了一系列的极端气候事件指数。这些指数被广泛用于气候变化研究,特别是在研究极端天气和气候事件方面。
ECA 的极端气候指数主要包括以下几类:
温度指数:这些指数主要用于度量温度的极端情况,例如热日数(TX90p,年中最高气温超过90百分位数的天数)、冷日数(TN10p,年中最低气温低于10百分位数的天数)、热夜数(TN90p,年中最低气温超过90百分位数的天数)、冷夜数(TN10p,年中最低气温低于10百分位数的天数)等。
降水指数:这些指数主要用于度量降水的极端情况,例如最大连续5日降水量(RX5day)、大于或等于10mm的降水日数(R10mm)、大于或等于20mm的降水日数(R20mm)、降水强度(SDII)等。这些指数对于理解和预测极端气候事件的影响非常重要,因为极端气候事件(如热浪、干旱、洪水等)往往比平均气候变化带来更大的影响。因此,对这些指数的研究有助于我们更好地理解和适应气候变化。
lConsecutive dry days index

lConsecutive frost days index per time period

lConsecutive summer days index per time period

lConsecutive wet days index per time period

专题九 典型应用案例-生态领域预估生长季开始和结束时间
1、建立气象数据与VIPPHEN遥感物候数据中生长季开始和结束
2、在未来气候情景下预估生长季长季开始、结束和长度
专题十 典型应用案例-水文、生态模式数据
● SWAT数据制备
●Biome-BGC数据
Biome-BGC是利用站点描述数据、气象数据和植被生理生态参数,模拟日尺度碳、水和氮通量的模型,其研究的空间尺度可以从点尺度扩展到陆地生态系统。案例中以单点模拟方式制备CMIP6的气象数据。

这篇关于cmip6数据处理之降尺度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!