本文主要是介绍Python爬虫:全民小视频爬取,你想到了什么?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
本次目标
爬取全民小视频
https://quanmin.baidu.com/
确定目标网页
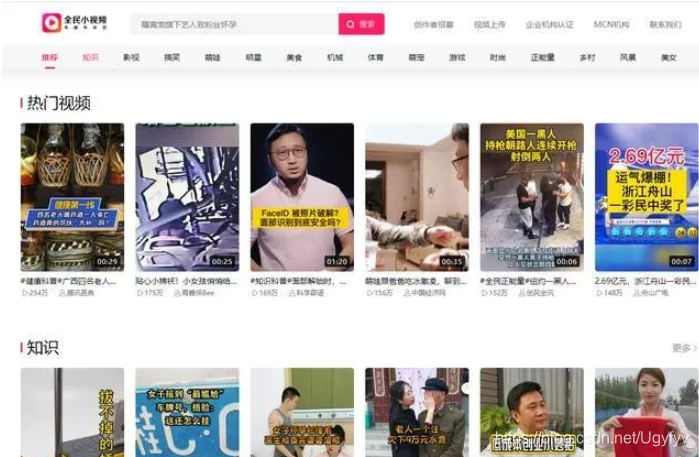
选择影视类目

右键选择检查,开发开发者工具
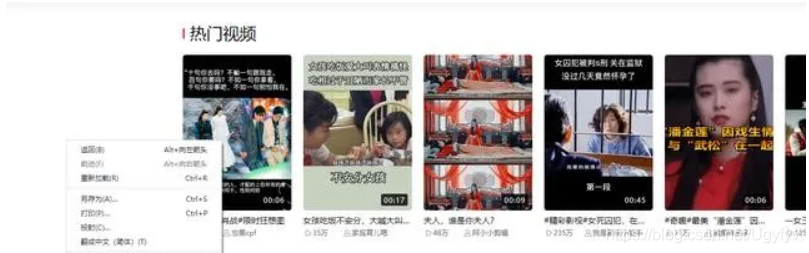
选择 Network,网页往下滑,可以看到数据加载
视频地址
视频名字
视频ID
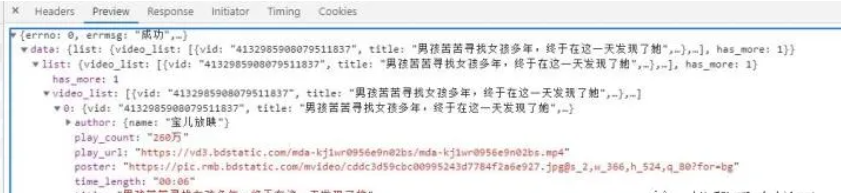
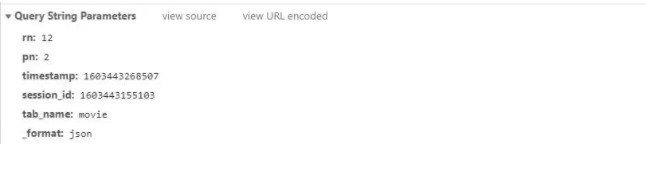
接口数据链接是通过pn的变化,实现翻页效果
如果想要爬取其他分类视频,把参数中tab_name 更改即可
环境
Python3.6
pycharm

开始代码
导入工具
1import pprint
2import requests
相关库可以用 pip install 安装
请求、解析、爬取网页数据,并保存
1url = 'https://quanmin.baidu.com/wise/growth/api/home/tabmorelist'2for page in range(1, 100):3 params = {4 'rn': '12',5 'pn': '{}'.format(page),6 'timestamp': '1603442730716',7 'session_id': '1603442719704',8 'tab_name': 'movie',9 '_format': 'json',
10 }
11 headers = {
12 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
13 }
14 response = requests.get(url=url, params=params, headers=headers)
15 html_data = response.json()
16 lis = html_data['data']['list']['video_list']
17 for li in lis:
18 play_url = li['play_url']
19 title = li['title']
20 filename = 'C:\\Users\\Administrator\\Desktop\\新建文件夹\\' + title + '.mp4'
21 response_2 = requests.get(url=play_url, headers=headers)
22 with open(filename, mode='wb') as f:
23 f.write(response_2.content)
24 print(title, play_url)
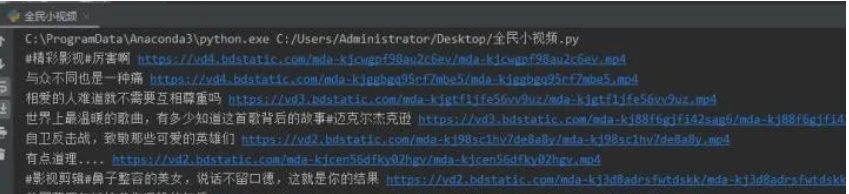
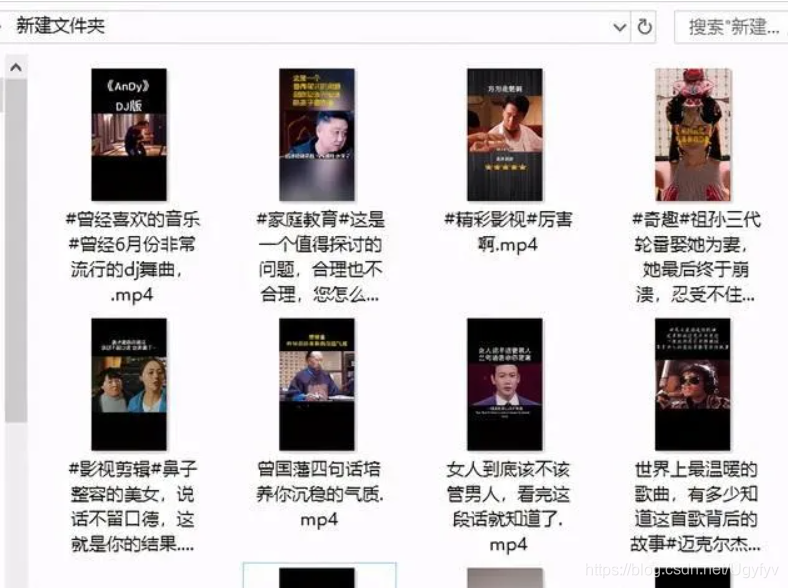
25运行代码,效果如下
这篇关于Python爬虫:全民小视频爬取,你想到了什么?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





