本文主要是介绍Python3爬取粗饼网所中国魔方选手三阶单次成绩,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:最近刚入门Python,在网上各种乱逛,稍微涉猎了一下Python爬虫,就想自己爬个东西练练手,加上之前自己也算是个魔方玩家,所以就想着把所以中国魔方选手的成绩都爬取保存下来,之后再对其做分析。
Python版本:3.7.0
使用方式:resquests+beautifulsoup
网站:https://cubingchina.com/results/rankings
分析页面
打开成绩页面,发现所以的选手信息都在一张表格里,打开开发者工具,发现个有意思的东西:每个选手所在行的class不同,单数是odd,双数是even,所以待会儿定位数据位置的时候得稍微注意一下儿了。
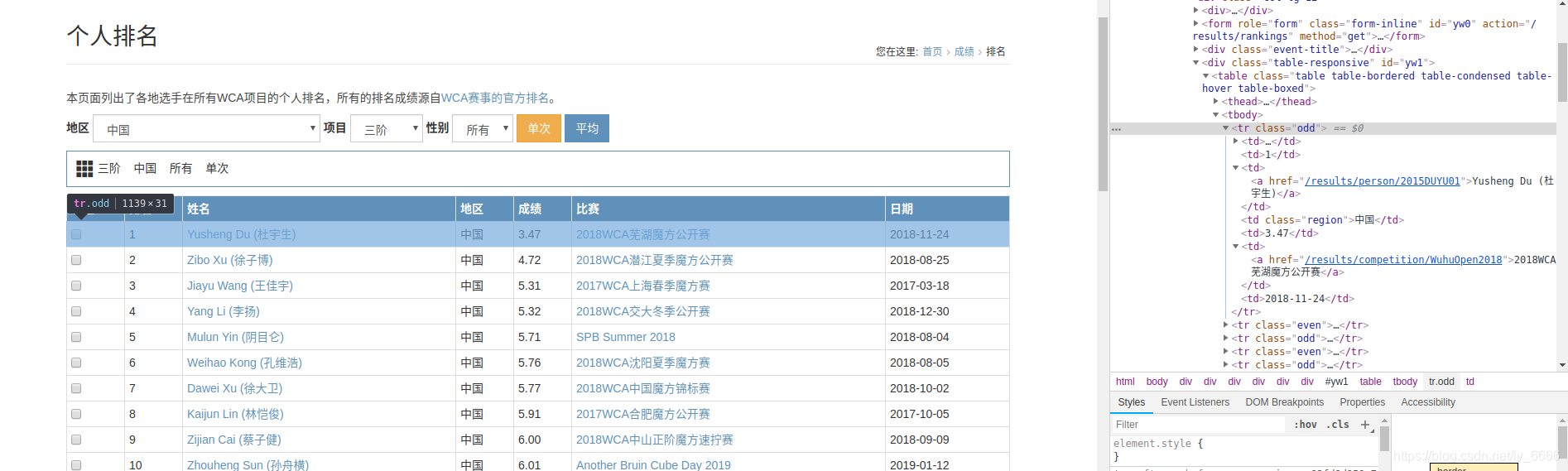
接着到底部,看到有下一页和末页的按钮,都在<li>标签下的<a>标签下,class分别是next和last

接着看后面的页面都是一样的,最后看一下最后一页,发现虽然下一页和末页的链接不能点击,但是在html文件里面是有链接的,这样就不好判断怎么是最后一页了。我处理的方式有点蠢,在抓取第一页的时候就提取出最后一页的地址,然后循环条件是下一页链接和末页链接不等,最后单独处理末页。
爬取数据
首先打开粗饼页面
import requestsurl = ‘https://cubingchina.com/results/rankings’
response = requests.get(url)
response.encoding='utf-8'
print(response)然后发现,403了,不让访问
请教了下学长,说可以尝试一下模拟header,然后加了这么一句
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'}
在请求的时候加上header,成功了

接着就把这块封装成一个函数`
def get_html(url):'''根据url返回相应的html对象'''headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'}response = requests.get(url, headers=headers)response.encoding='utf-8'html = response.text# print(response)return html
然后用beautifulsoup解析,用的是lxml方式(其实我还不明白这个是怎么用的)
from bs4 import BeautifulSoup
def get_soup(html):'''根据HTML返回beautifulsoup对象'''soup = BeautifulSoup(html, 'lxml')return soup
然后获取每一页100位选手的信息
我们需要的是选手的排名,姓名,成绩,比赛以及日期
def get_rank_list(soup):'''使用beautifulsoup解析网页,取得选手信息返回选手信息列表'''# 之前分析过,所以选手的信息在一张表格中,查看html代码获取表格的信息,提取出信息rank_text_list = soup.find('table', {'class': 'table table-bordered table-condensed table-hover table-boxed'})# 第一个tr是表头信息,所以就舍弃了rank_text_list = rank_text_list.find_all('tr')[1:]rank_list = []for rank_text in rank_text_list:# 所有的信息都在td标签里rank_text = rank_text.find_all('td')# 排名rank = rank_text[1].extract().text# 姓名name = rank_text[2].extract().text# 成绩result = rank_text[4].extract().text# 比赛competitive = rank_text[5].extract().text# 日期date = rank_text[6].extract().text# 把所有数据封装成一个元组,然后添加到选手成绩列表里item = (rank, name, result, competitive, date)rank_list.append(item)return rank_list
接着把爬到的数据写入到csv文件里
def writer_file(rank_list, flag=''):'''写入csv文件'''header = ('排名', '姓名', '成绩', '比赛', '日期')with open('333_single_China.csv', 'a', encoding='utf-8', newline='') as file:writer = csv.writer(file)if flag == 'first':writer.writerow(header)for rank in rank_list:writer.writerow(rank)
爬取完一个页面的信息后,得继续爬下一页
def get_next_url(soup):'''获取下一页地址'''url_text = soup.find('li', {'class': 'next'})url_text = url_text.find('a')# 因为是相对地址,所以还需要拼接一下网站的主地址,直接用字符串拼接是不是有点low啊(小声BB)main_url = 'https://cubingchina.com'url = main_url + url_text.get('href')return url
大体需要写好了,最后组合到main函数里
def main():start_url = 'https://cubingchina.com/results/rankings'# 先处理第一页,获取末页地址html = get_html(start_url)soup = get_soup(html)# print(soup)# 排名写入文件rank_list = get_rank_list(soup)# print(rank_list)writer_file(rank_list, 'first')print('第1页下载完成')# 获取下一页urlnext_url = get_next_url(soup)# 获取最后一页urllast_text = soup.find('li', {'class': 'last'})last_text = last_text.find('a')last_url = main_url + last_text.get('href')# 当下一页链接不等于末页链接是,接着运行i = 2while next_url != last_url:html = get_html(next_url)soup = get_soup(html)rank_list = get_rank_list(soup)writer_file(rank_list)next_url = get_next_url(soup)print('第{}页下载完成'.format(i))i += 1# 下载获取最后一页html = get_html(next_url)soup = get_soup(html)rank_list = get_rank_list(soup)writer_file(rank_list)print('第{}页下载完成'.format(i))
大概就是这样,爬出的数据如下,用excel处理了下,看着舒服点

最后把源码完整贴出来
'''功能:爬取粗饼网所有人三阶单次成绩作者:Davion版本:V1.0日期:2018/03/12
'''import requests
from bs4 import BeautifulSoup
import csvmain_url = 'https://cubingchina.com'def get_html(url):'''根据url返回相应的html对象'''headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'}response = requests.get(url, headers=headers)response.encoding='utf-8'html = response.text# print(response)return htmldef get_soup(html):'''根据HTML返回beautifulsoup对象'''soup = BeautifulSoup(html, 'lxml')return soupdef get_rank_list(soup):'''使用beautifulsoup解析网页,取得选手信息返回选手信息列表'''rank_text_list = soup.find('table', {'class': 'table table-bordered table-condensed table-hover table-boxed'})rank_text_list = rank_text_list.find_all('tr')[1:]rank_list = []for rank_text in rank_text_list:rank_text = rank_text.find_all('td')rank = rank_text[1].extract().textname = rank_text[2].extract().textresult = rank_text[4].extract().textcompetitive = rank_text[5].extract().textdate = rank_text[6].extract().textitem = (rank, name, result, competitive, date)rank_list.append(item)return rank_listdef writer_file(rank_list, flag=''):'''写入csv文件'''header = ('排名', '姓名', '成绩', '比赛', '日期')with open('333_single_China.csv', 'a', encoding='utf-8', newline='') as file:writer = csv.writer(file)if flag == 'first':writer.writerow(header)for rank in rank_list:writer.writerow(rank)def get_next_url(soup):'''获取下一页地址'''url_text = soup.find('li', {'class': 'next'})url_text = url_text.find('a')url = main_url + url_text.get('href')return urldef main():start_url = 'https://cubingchina.com/results/rankings'html = get_html(start_url)soup = get_soup(html)# print(soup)# 排名写入文件rank_list = get_rank_list(soup)# print(rank_list)writer_file(rank_list, 'first')print('第1页下载完成')# 获取下一页urlnext_url = get_next_url(soup)# 获取最后一页urllast_text = soup.find('li', {'class': 'last'})last_text = last_text.find('a')last_url = main_url + last_text.get('href')i = 2while next_url != last_url:html = get_html(next_url)soup = get_soup(html)rank_list = get_rank_list(soup)writer_file(rank_list)next_url = get_next_url(soup)print('第{}页下载完成'.format(i))i += 1# 下载获取最后一页html = get_html(next_url)soup = get_soup(html)rank_list = get_rank_list(soup)writer_file(rank_list)print('第{}页下载完成'.format(i))if __name__=="__main__":main()
新手上路,很多不成熟和错误的地方请各位谅解
感谢观看!
这篇关于Python3爬取粗饼网所中国魔方选手三阶单次成绩的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






