本文主要是介绍CVPR2020论文翻译:CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CVPR2020: CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement
题目:通过全局和局部优化进行超高分辨率的图像分割

论文地址:https://arxiv.org/abs/2005.02551
代码地址:https://github.com/hkchengrex/CascadePSP
作者团队:香港科技大学&腾讯
摘要:
目前最先进的语义分割方法几乎都是在固定分辨率范围内对图像进行训练。这些分割对于非常高分辨率的图像是不准确的,因为使用低分辨率分割的双三次上采样并不能充分地沿对象边界捕获高分辨率细节。在本文中,我们提出了一种新的方法来解决不使用任何高分辨率训练数据的高分辨率分割问题。关键的一步是我们的CascadePSP网络,它可以在任何可能的情况下优化和修正局部边界。虽然我们的网络是用低分辨率分割数据训练的,但是我们的方法适用于任何分辨率,即使是对于大于4K的高分辨率图像。我们对不同的数据集进行了定量和定性的研究,结果表明CascadePSP可以在不需要任何微调的情况下,使用我们的改进模块显示像素精确的分割边界。因此,我们的方法可以看作是类不可知的。最后,我们展示了我们的模型在多类分割场景分析中的应用。
1.介绍:
商品相机和显示器的分辨率显著提高,4K超高清(3840×2160)成为行业高标准。尽管对高分辨率媒体的需求很大,但许多最先进的计算机视觉算法在处理高像素图像时面临着各种挑战。图像语义分割是计算机视觉的一项重要任务。面向低分辨率图像的深度学习语义分割模型(例如PASCAL或COCO数据集)通常不能推广到更高分辨率的场景。尤其是,这些模型通常使用GPU内存对像素数量线性化了,这使得几乎不可能直接训练4K 超高清分割。由于需要像素精度的标注,难以获得高分辨率的语义分割训练数据,更不用说这些高分辨率的训练数据了,为了在高分辨率图像上训练模型,需要更大的感受野来捕获足够的语义。看似可行的解决方法包括下采样和裁剪,但前者删除细节,而后者破坏图像上下文。
本文提出了一种通用的分割细化模型CascadePSP,它将任意给定的分割从低分辨率细化到高分辨率。我们的模型是独立训练的,可以很容易地附加到任何现有的方法中来改进它们的分割,可以生成更精细和更精确的对象分割掩码。我们的模型以初始掩码作为输入,它可以是任何算法的输出,以提供粗略的目标定位。然后我们的CascadePSP将输出一个精细的掩码。我们的模型是以一种级联的方式设计的,以一种从粗到细的方式生成精确的分割。早期级别的粗略输出预测对象结构,该结构将用作后期级别的输入,以细化边界细节。图1显示了模型不仅输出一个在很高的像素上的掩码,同时改进和修正错误的边界以产生更精确的结果。

图1.高分辨率图像(3492×2328)的分割,左:Deeplab V3+产生的分割掩码,右图:由我们的算法改进的分割掩码。
为了在非常高分辨率的图像上进行评估,我们对一个高分辨率数据集进行了注释,该数据集包含50个验证和100个测试对象,其语义类别与PASCAL中的相同,被称为BIG dataset。我们在PASCAL VOC 2012、BIG和ADE20K上测试了我们的模型。对于没有使用数据集本身进行微调的单个模型,我们在这些数据集和模型中实现了对最新方法的一致改进。我们表明,我们的模型不必针对特定的数据集或特定模型的输出进行训练。相反,通过扰动标签来进行数据增强就足够了。我们也展示了我们的模型能够被拓展到场景解析,以实现具有直接适应性的密集多类语义分割。我们的主要贡献可以概括为:
•我们提出了CascadePSP ,这是一种通用的级联分割优化模型,可以对任何给定的输入分割进行优化,在不进行微调的情况下提高最新分割模型的性能。
•我们进一步证明,我们的方法可以用于产生高质量和非常高分辨率的分割,而这是以前基于深度学习的方法从未实现过的。
•我们介绍了BIG dataset,它可以作为非常高分辨率语义图像分割任务的精确评估数据集。
2.相关工作:
语义分割
文献[31]首次将完全卷积神经网络(FCN)引入到语义分割中,取得了显著的进展。虽然FCNs从下到上捕获信息,但是具有广阔视野的上下文信息对于像素标记任务也很重要,并且被许多分割模型所利用[3、5、14、17、32、39、51],包括使用多尺度输入的图像金字塔方法[5、9、14、22、23、36]或通过空间池[29、53]6积[3、4、6、21、42、49]。我们选择PSPNet[53]在我们的网络中进行金字塔池化,因为相关模块独立于输入分辨率,因此提供了一种简单而有效的方法来捕获上下文信息,即使训练和测试分辨率与我们的情况有很大不同。编码器-解码器模型也被广泛应用于分割方法[1,6,21,25,27,33,37,42]。它们首先降低空间维度以捕获高层语义,然后使用解码器恢复空间范围。跳过连接[12,37,40]可以添加,以产生更清晰的边界,我们也使用了。
语义分割模型通常有很大的输出跨距比如4或者8[2, 3, 4] 由于内存和计算限制。带跨距的输出通常双倍放大到目标大小,导致边界标签不准确。最近,文献[7]的作者提出了全局局部网络(GLNet)来解决这一问题,它使用一个具有局部精细结构网络的全局信息分支。但是,它们仍然需要高分辨率的训练图像,而这些图像不适用于大多数任务。
该方法采用编码器-解码器模型,通过细化级联获得更好的语义和边界信息,有助于高效地生成高分辨率的分割。该公式也使我们的方法具有很强的鲁棒性,并且可以推广到不需要微调的高分辨率数据。
精细分割
基于FCN的方法通常不会产生非常高质量的分割。研究人员已经用图形模型如CRF[2,3,23,20,30,54]或区域生长[10]来解决这个问题。它们通常遵循低级颜色边界,而没有充分利用高级语义信息,无法修复较大的错误区域。基于传播的方法[26]由于计算和内存限制,无法处理非常高分辨率的数据。单独的细化模块也用于提高边界精度[35,46,50]。他们为端到端的训练模式。大型模型容易过度拟合[50],而浅层精细化网络[35,47]的精细化能力有限。与此相反,我们的方法具有很高的模型容量,并且可以独立训练来修复只使用对象的分割。
级联网络
多尺度分析利用了许多计算机视觉任务中的大尺度和小尺度特征,如边缘检测[15,45]、检测[24,28,41]和分割[7,22,52]。特别是,许多方法[22、45、52]在每个阶段预测独立的结果并将它们合并以获得多尺度信息。我们的方法不仅融合了粗尺度的特征,而且将它们作为下一个更精细层次的输入之一。我们将证明,添加粗输出作为下一个级别的输入不会改变我们的公式,因此相同的网络可以递归地用于更高分辨率的细化。
3. CascadePSP
在这一部分中,我们首先描述了我们的单一细化模块,然后介绍了我们的级联方法,该方法利用多个细化模块进行高分辨率分割。
3.1. 精细模块
如图2所示,我们的细化模块在不同的尺度上对图像和多个不完美的分割掩码进行细化分割。多尺度输入允许模型捕捉不同层次的结构和边界信息,从而允许网络在最好的水平上从不同的尺度去精细分割去学习自适应地融合掩码特征。

图2.精细模块(RM)。单个RM的网络结构,以三个等级的分割为输入,在不同分支中不同输出步长的分割进行细化。红线表示跳越连接。在本文中,我们使用8、4和1的输出跨距。
所有低分辨率的输入分割都被双线性上采样到相同的大小,并与RGB图像相连。以ResNet-50[16]为骨干,利用PSPNet[53]从输入中提取8幅步幅特征图。我们遵循[1,2,3,6]的金字塔池大小,如[53]所示,这有助于捕获全局上下文。除了最后的步长1输出,我们的模型还生成中间的步长8和步长4的分割,致力于修补输入分割的总体结构。我们跳过步长2以提供纠正局部错误边界的灵活性。
为了重建在提取过程中丢失的像素级图像细节,我们采用了从骨干网跳接的方法,并使用上采样块融合特征。我们串联了跳跃连接的特征和从主干双线性上采样的特征,接着用两个ResNet块处理它们。使用2层1×1 conv生成分割输出,后面跟着sigmoid激活函数。
Loss
对于较粗糙的步长8输出,我们使用交叉熵损失,对于较精细的步长1输出,我们使用L1+L2损失,对于中间的步长4输出,我们使用交叉熵和L1+L2损失的平均值得出最佳结果。对于不同的步幅,采用不同的损失函数,因为粗精处理只关注全局结构而忽略局部细节,而精细化则通过依赖局部线索来达到像素级的精度。为了鼓励更好的边界细化,在步长1输出上也使用了分割梯度幅度的L1损失。分割梯度由3×3均值滤波器和Sobel算子进行估计[18]。梯度损失使得输出在像素级更好地与对象边界相结合。我们用α给其增加权重,在我们的实验中设为5。梯度损失可以写成:
其中fm(·)表示3×3平均滤波器,∇表示由Sobel算子近似的梯度算子,n为像素总数,xi和yi分别为第i个像素的真值分割和输出分割。我们的最终损失可以写成:

其中Ls CE、Ls L1+L2和Ls grad分别表示输出步长s的交叉熵损失、L1+L2损失和梯度损失。
精细模块消融实验
我们使用标准分割度量IoU来评估我们的方法。为了强调边界准确性的感性重要性,提出了一种新的平均边界精度测量方法(mBA)。对于不同大小图像的稳健估计,我们在[3,w+h/300]中以均匀间隔取样5个半径,从真值边界计算每个半径内的分割精度,然后平均这些值。表1显示,我们的模型在IoU方面产生了最显著的改进,在边界精度方面甚至更显著。
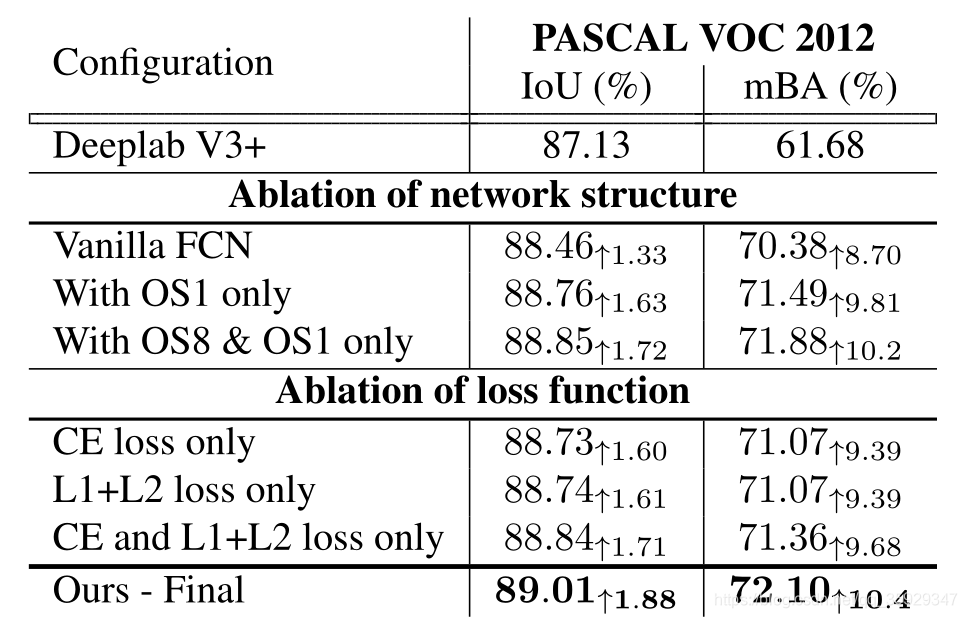
表1。细化模块消融实验。利用所提出的三级级联和损失函数,我们获得了比输入分割模型更高的增益。
通过多级级联,模块可以将不同的细化阶段委托给不同的尺度。如图3所示,3级模型使用中间的小规模分割(将在第3.2节中详细说明)来更好地捕获对象结构。尽管每个模型有着相同的感受野,与一级模型相比,三级模型可以更好地利用结构线索产生更详细的分割。

图3。三级输入模型和一级输入模型的区别。三级输入模型使用小尺度的中间产物(下一行,左二),虽然不准确,但可以捕获结构信息(如触须),以便在后期进行改进。
3.2.全局和局部级联求精
在测试中,我们使用全局步骤和局部步骤,通过使用相同的训练精化模块来执行高分辨率分割精化。具体来说,全局步骤考虑整个被调整了大小的图像来修复结构,而局部步骤使用图像裁剪以全分辨率细化细节。相同的求精模块可以递归地用于更高分辨率的求精。
3.2.1全局步骤
图4详细说明了全局步骤的设计,该步骤使用3级级联优化整个图像。由于测试过程中的全分辨率图像往往无法适合GPU进行处理,因此我们在保持相同长宽比的情况下,对输入进行降采样,使长轴具有长度L。
级联的输入由输入的分割初始化,输入分割被复制以保持输入通道维度不变。在级联的第一级之后,其中一个输入通道将被双线性上采样粗输出所代替。这将重复到最后一级,其中输入由初始分割和前一级的所有输出组成。
这种设计使我们的网络能够逐步修正分割错误,同时在初始分割中保持细节。在多个层次上,我们可以粗略地描绘目标,并在粗层次上修正较大的误差;在细层次上,我们可以使用粗层次提供的更稳健的特征来关注边界精度。
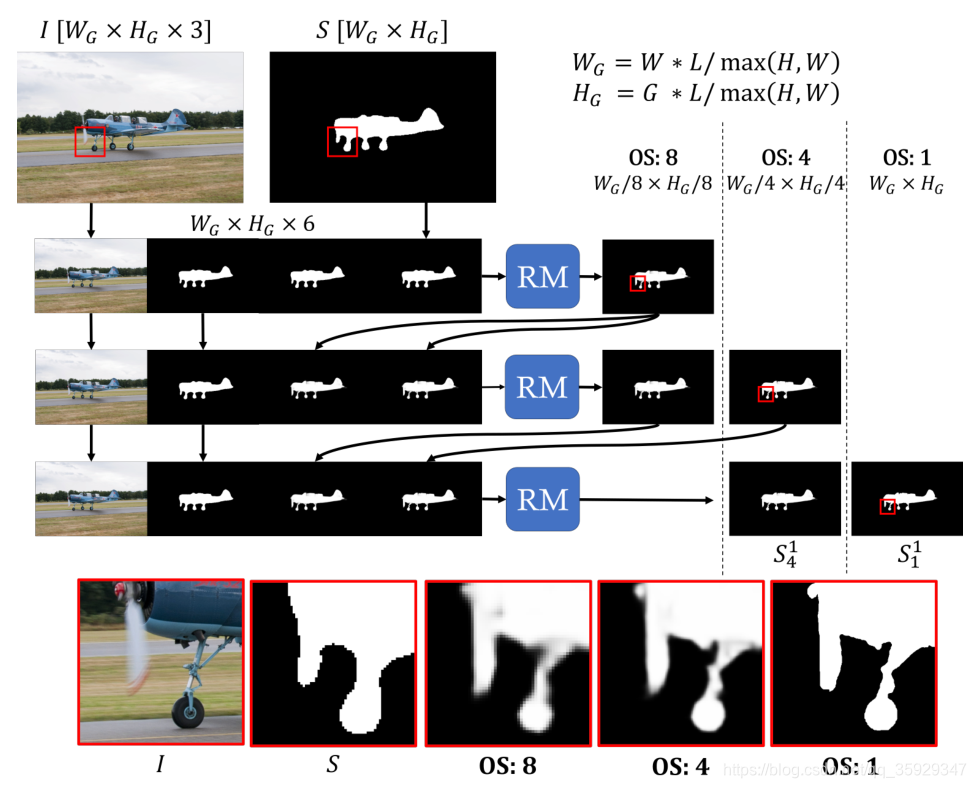
图4。全局步骤使用相同的优化模块(RM)对整个图像进行优化,以执行输出跨距(OS)为8、4和1的三级级联。对级联进行了联合优化,在大的输出步长下捕捉目标结构,在小的输出步长下捕捉精确边界(即具有更高的分辨率)。
3.2.2局部步骤
图5说明了局部步骤的详细信息。由于内存限制,即使使用现代gpu,也无法在一次处理中处理非常高分辨率的图像。同时,训练数据和测试数据之间尺度的急剧变化也会导致分割质量的下降。我们利用我们的级联模型首先使用下采样图像执行全局细化,然后使用来自高分辨率图像的图像裁剪执行局部细化。这些裁剪使本地步骤能够在不需要高分辨率训练数据的情况下处理高分辨率图像,同时由于全局步骤而考虑图像上下文。
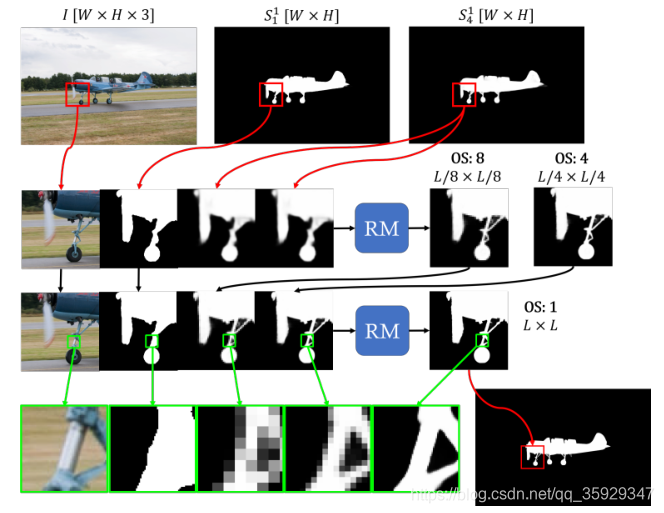
图5。局部步骤从全局步骤获取输出,并通过由相同的优化模块构造的两级级联(输出步长分别为4和1)将其馈送出去。此图显示了一个图像裁剪的过程,如红线所示,绿线显示了我们改进的视觉效果。所有图像裁剪的输出将作为最终输出进行融合。
在局部步骤中,模型取全局步骤最后一级的两个输出,分别表示为S4和S1。两个输出都被双线性调整到图像W×H的原始大小。两个输出都被双线性调整到图像W×H的原始大小。该模型采用L×L大小的图像裁剪,裁剪输出的每一侧将有16个像素被切掉,以避免边界伪影,图像边框除外。以L/2-32的步幅均匀地进行裁剪,使得大多数像素被四个裁剪覆盖,并且超出图像边界的无效裁剪被移动以与图像的最后一行/列对齐。然后将图像裁剪块分别送入输出步长为4和1的二级级联。在融合过程中,由于图像上下文的不同,来自不同图块的输出可能不一致,我们通过平均所有的输出值来解决这个问题。
3.2.3选择L
图6显示了当选择不同的L时,测试期间GPU内存使用和优化质量(mBA)之间的关系。在我们的实验中,我们选择了L=900和3.16GB的GPU内存使用量,以平衡增加GPU内存使用量和降低性能增益之间的权衡。在我们对大型验证集的实验中,使用更高的L是不必要的,而且会占用额外的内存。在低内存设置中,可以使用较小的L(例如500)来产生稍差的(0.6%mBA)精细结果,内存占用率(1.16gb)要低得多。注意,GPU内存的使用仅与L有关,而与图像分辨率无关,因为融合步骤可以在CPU上容易地执行。
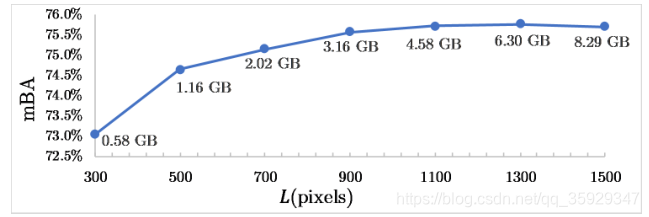
图6。BIG验证集中L和mBA的选择关系。随着L的增加,GPU内存使用量随着性能增益的减小而增加。
3.2.4整体和局部细化的消融研究
表2显示了全局步骤和局部步骤对于高分辨率分割细化都是必不可少的。注意,当我们移除全局步骤时,IoU下降更为显著,这表明全局步骤主要负责修复对IoU提升贡献更大的整体结构,而由于图像上下文不足,仅局部步骤无法达到。

表2。整体和局部步骤的消融实验。输入分割取自大型验证集上的DeepLab V3+。使用这两个步骤可以显示最佳结果。
在没有局部步长的情况下,虽然IoU只略有下降,但由于全局步长不能提取高分辨率的细节,边界精度下降更为明显。
图7研究了不同分辨率输入的局部步长的重要性:我们在调整BIG验证集的大小所生成的各种大小的分割中评估了有或无局部步长的方法。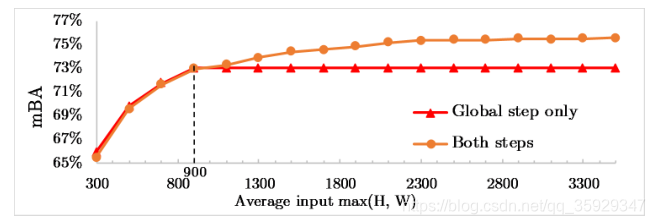
图7。我们在不同的输入分辨率下评估了我们的方法。全局步长不受益于高分辨率输入,因为它受L=900的限制。局部步骤对于高分辨率精细化处理大于L的输入以及考虑到受限的内存开销至关重要。
当全局步骤足够用于低分辨率输入时,局部步骤对于尺寸大于改变点900的精确高分辨率细化至关重要。因此,对于max(H,W)≥900的输入,我们同时使用全局和局部步长,对于较低分辨率的输入,我们只使用全局步长。
3.3. Training
为了学习对象信息,我们以类不可知的方式在数据集集合上训练模型。我们将MSRA-10K[8]、DUT-OMRON[48]、ECSSD[38]和FSS-1000[44]合并,生成一个36572的分割数据集,其语义类比普通数据集(如PASCAL(20类)或COCO(80类))要多样化得多。使用这个数据集(>1000个类)可以使我们的模型更加健壮,并且可以推广到新的类。在训练过程中,我们随机选取224×224个图像裁剪,通过扰动真值来产生输入分割。输入经过一个三级级联,就像在全局步骤中一样,在每个级别计算损失。虽然裁剪尺寸小于用于测试的L,但我们的模型设计有助于弥合这一差距。全卷积特征抽取器提供了平移不变性,而金字塔池模块提供了重要的图像上下文,允许我们的模型扩展到更高的分辨率,而没有显著的性能损失。小裁剪的使用加快了我们的训练过程,使数据准备变得更加容易,因为用于分割的高分辨率训练数据的获取成本高昂。对于泛化性,我们避免使用现有模型生成的分割输出进行训练,这可能导致对特定模型的过度拟合。相反,被扰动的真值应该描绘出不同的形状和由其他方法产生的不准确分割的输出,这有助于我们的算法对不同的初始分割更加鲁棒。我们通过对轮廓进行二次采样,然后进行随机膨胀和腐蚀,从而生成这样的扰动分割。这种扰动的例子如图8所示。

图8。蓝色:FSS-1000的地面真值标签[44]。红色:扰动标签,我们用它作为输入来训练我们的模型。
3. Experiments
在本节中,我们使用PASCAL VOC 2012[13]、BIG(我们的高分辨率数据集)和ADE20K[55]对结果进行了定量评估。我们评估我们的模型,在不同的设置没有任何微调,并显示我们的模型所做的改进。
4.1. Dataset and Evaluation Method
尽管PASCAL VOC 2012数据集在图像分割任务中得到了广泛的应用,但它的像素分割并不完美同时边界附近的区域被标记为“空白”。为了更准确地评估,我们重新标记了来自PASCAL VOC 2012验证集的500个分割,以便在空隙边界区域内找到准确的边界。图9显示了一个重新标记的示例。
图9。PASCAL VOC 2012验证集中的分段结果。左图:PASCAL VOC 2012的真实标签示例。红线显示空边界标签。右:对同一图像重新标记分割。
缺乏高分辨率图像分割数据集是高分辨率图像分割模型评估的难点之一。为了解决这一问题,我们提出了一个具有50个验证和100个测试对象的大数据集、高分辨率的语义分割数据集。图像分辨率在2048×1600到5000×3600之间。数据集中的每个图像都由专业人员仔细标记,同时保持与PASCAL VOC 2012相同的指导原则,没有空白区域。重新标记的PASCAL验证集和大数据集都可以在我们的项目网站上找到。评估中使用的其他数据集没有被修改。我们使用标准分割度量IoU和边界度量mBA来评估我们的方法。
4.2. 实现细节
我们用PyTorch[34]实现了我们的模型。我们使用带有ResNet-50骨干网的PSPNet作为我们的基础网络。为了进一步增加数据的多样性,进行了数据增强,包括真值的扰动、图像翻转和裁剪。我们使用Adam优化器[19],其权重衰减为10-4,30K次迭代的学习率为3×10-4,然后再使用3×10-5次迭代的学习率,其批大小为9。总训练时间约16小时,两个1080Ti。局部步骤只在感兴趣的区域中执行,对于图1,完整的细化过程大约需要6.6s。除非另有说明,我们对所有实验都使用相同的训练模型。
4.3. 分割输入
我们的方法可以只使用对象信息来细化输入分割。注意,我们的模型在训练中从未见过以下任何数据集。在本节中,我们将重点讨论单个对象的细化效果,意味着类别竞争并没有提及。在这里,我们比较和评估了我们的精化模型对在PASCAL VOC 2012数据集上训练的各种语义分割模型的输出的效果。我们的方法比常用的多尺度测试更有效,实验结果在补充材料中进一步显示。
PASCAL VOC 2012
由于输入模型是在PASCAL VOC 2012数据集中训练的,因此不需要调整大小来获得输出,然后将其输入到我们的优化模型中。这些图像的分辨率较低,因此我们只能使用全局步长直接对其进行细化。我们在表3的上半部分报告了类不可知的IoU和边界精度。结果表明,该方法在任何情况下都能提高分割质量,尤其是在边界区域。

图10。红色:由Deeplab V3+生产。紫色:由我们的算法改进的分割。
BIG dataset
由于内存限制,现有的分割方法大多不能直接在全分辨率BIG数据集上进行评价。因此,我们通过将调整了大小的图像输入到现有模型中来获得初始分割。在保持长宽比的前提下,对输入图像进行降采样,使长轴为512像素,对输出图像进行双三次升采样,使分割结果达到原来的分辨率。在表3的下半部分,我们展示了我们在具有高分辨率分割的BIG测试集上的结果。
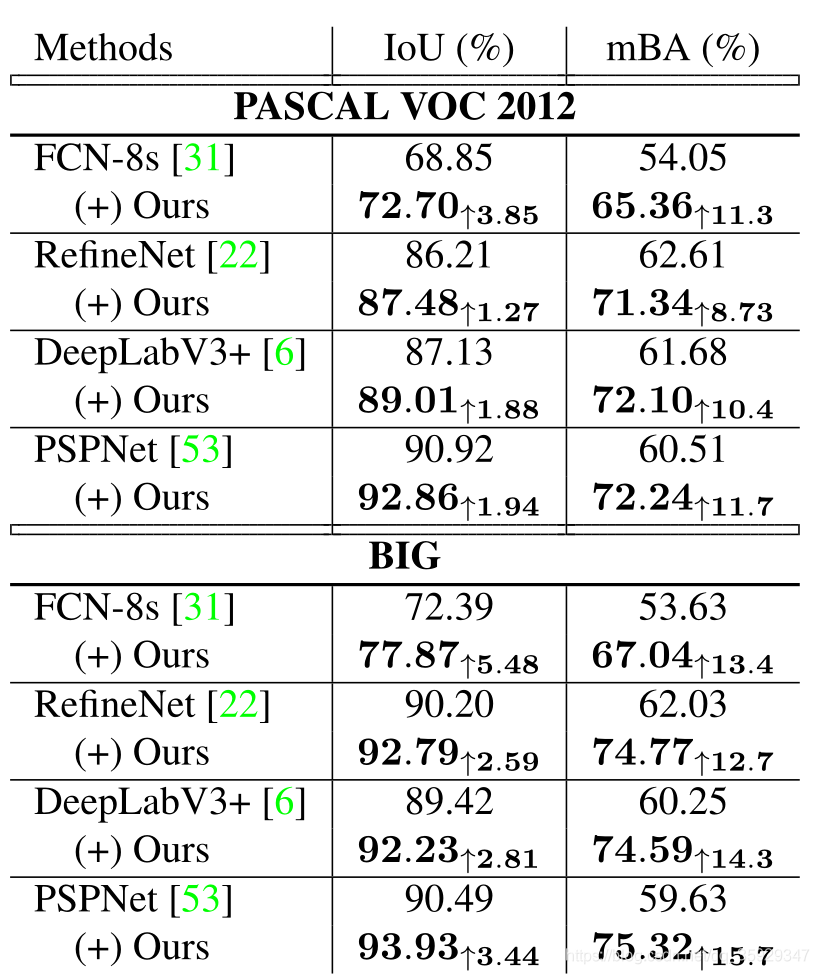
表3。不同语义分割方法的比较。它们的结果是使用各自的官方实现和最好的模型生成的。原始模型的低分辨率输出被双三次上采样到原始分辨率进行评估。
请注意,即使我们从未见过任何高分辨率的训练图像,我们也能够在这些尺度上产生高质量的改进。图14显示了我们改进的视觉效果。

图11。我们方法的失败案例。DeeplabV3+错误地将脚的大区域标记为前景。尽管我们的改进仍然很好地依附于颜色边界,但由于缺乏语义信息,它产生了错误的分割。
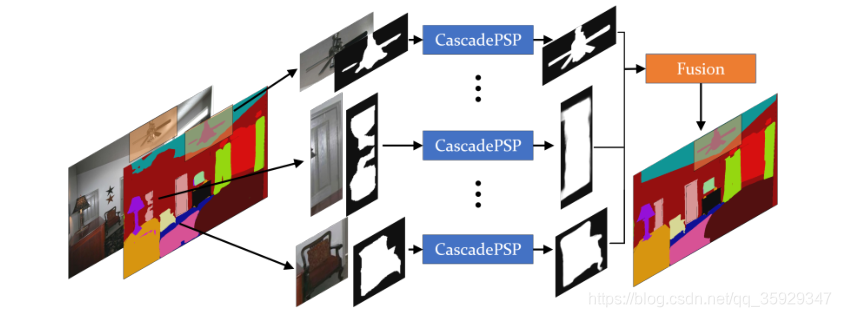
图12。CascadePSP在场景分析中的分治策略。
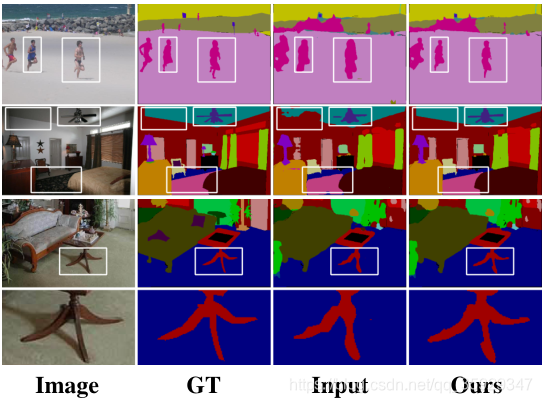
图13。ADE20K验证集中的优化结果。前两行:PSPNet。下面两行:RefineNet。

图14。大测试集上的视觉比较。奇数行显示整个图像,偶数行显示放大的裁剪。输入来自DeeplabV3+、RefineNet、PSPNet和FCN-8s,自上而下。
图14显示了我们改进的视觉效果。尽管超分辨率模型[11,43]对于上采样分段掩码似乎是合理的,但错误分割的输入(如图13中缺失的桌腿和图14中婴儿的手)无法通过超分辨率进行校正。我们的方法依赖于输入分割和底层线索,不具备特定的语义能力。图11显示了一个失败案例,其中输入错误太大,我们的方法无法消除。
4.4. 场景解析
为了将 CascadePSP 扩展到场景分析,在稠密类别的场景下,类别竞争可能会产生问题,我们提出了一种分而治之的方法,利用我们的预训练网络独立地细化每个语义对象,然后使用融合函数对结果进行整合。图12概述了我们的策略。
我们通过使用25%填充的roi,为每个语义对象独立地细化足够大的连接组件。为了处理重叠区域,天真的方法将在输出置信度上使用argmax,这将导致在所有类分数都较低的区域产生噪声结果。相反,我们的融合函数是一个modified argmax,在这里如果所有输入的类别的置信度比0.5低,我们回到原来的分割。在这里,我们在ADE20K[55]的验证集上评估我们的模型。由于ADE20K数据集包含的“素材”背景类(见补充材料)的客观性不强,与我们的训练数据相差太大,因此我们降低了它们的输出分数,将重点放在前景细化上。请注意,优化前景对象仍然有助于背景优化,因为argmax操作将两个置信度分数都考虑在内。表4列出的结果表明,我们的模型产生了更高质量的分割。图13显示了样本定性评估。
表4。在ADE20K验证集上对不同方法进行改进与否的比较。
5. Conclusion
我们提出了一个通用的分割细化框架CascadePSP,它可以在不需要任何微调的情况下对任何输入分割进行细化,从而获得更高的精度。CascadePSP执行高分辨率(高达4K)分割细化,即使我们的模型从未见过任何高分辨率的训练图像。在没有任何微调的情况下,使用一个针对低分辨率数据的优化模块,所提出的全局步骤对整个图像进行细化,并为后续的局部步骤提供足够的图像上下文以执行高质量的全分辨率细化。我们希望这项工作能为今后更高分辨率的计算机视觉任务做出贡献。
感谢
感谢张敬扬在科大交换学期所进行的卓有成效的讨论。
References
[1] Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla.
Segnet: A deep convolutional encoder-decoder architecture
for image segmentation. TPAMI, 2017. 2
[2] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos,
Kevin Murphy, and Alan L Y uille. Semantic image segmen-
tation with deep convolutional nets and fully connected crfs.
In ICLR, 2015. 2
[3] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos,
Kevin Murphy, and Alan L Y uille. Deeplab: Semantic image
segmentation with deep convolutional nets, atrous convolu-
tion, and fully connected crfs. TPAMI, 2017. 2
[4] Liang-Chieh Chen, George Papandreou, Florian Schroff, and
Hartwig Adam. Rethinking atrous convolution for seman-
tic image segmentation. arXiv preprint arXiv:1706.05587,
2017. 2
[5] Liang-Chieh Chen, Yi Yang, Jiang Wang, Wei Xu, and
Alan L Y uille. Attention to scale: Scale-aware semantic im-
age segmentation. In CVPR, 2016. 2
[6] Liang-Chieh Chen, Y ukun Zhu, George Papandreou, Florian
Schroff, and Hartwig Adam. Encoder-decoder with atrous
separable convolution for semantic image segmentation. In
ECCV, 2018. 1, 2, 6
[7] Wuyang Chen, Ziyu Jiang, Zhangyang Wang, Kexin Cui,
and Xiaoning Qian. Collaborative global-local networks for
memory-efficient segmentation of ultra-high resolution im-
ages. In CVPR, 2019. 2
[8] Ming-Ming Cheng, Niloy J. Mitra, Xiaolei Huang, Philip
Hilaire Sean Torr, and Shi-Min Hu. Global contrast based
salient region detection. TPAMI, 2015. 5
[9] Jifeng Dai, Kaiming He, and Jian Sun. Convolutional feature
masking for joint object and stuff segmentation. In CVPR,
2015. 2
[10] Philipe Ambrozio Dias and Henry Medeiros. Semantic seg-
mentation refinement by monte carlo region growing of high
confidence detections. In ACCV, 2018. 2
[11] Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou
Tang. Image super-resolution using deep convolutional net-
works. In PAMI, 2015. 7
[12] Michal Drozdzal, Eugene V orontsov, Gabriel Chartrand,
Samuel Kadoury, and Chris Pal. The importance of skip con-
nections in biomedical image segmentation. In Deep Learn-
ing and Data Labeling for Medical Applications, 2016. 2
[13] Mark Everingham, S. M. Ali Eslami, Luc V an Gool, Christo-
pher K. I. Williams, John Winn, and Andrew Zisserman. The
pascal visual object classes challenge – a retrospective. In
IJCV, 2014. 5
[14] Clement Farabet, Camille Couprie, Laurent Najman, and
Yann LeCun. Learning hierarchical features for scene la-
beling. TPAMI, 2012. 2
[15] Jianzhong He, Shiliang Zhang, Ming Yang, Yanhu Shan, and
Tiejun Huang. Bi-directional cascade network for perceptual
edge detection. In CVPR, 2019. 2
[16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Deep residual learning for image recognition. In CVPR,
2016. 3
[17] Xuming He, Richard S Zemel, and MiguelÁ Carreira-
Perpi˜ nán. Multiscale conditional random fields for image
labeling. In CVPR, 2004. 2
[18] Nick Kanopoulos, Nagesh V asanthavada, and Robert L
Baker. Design of an image edge detection filter using the
sobel operator. IEEE Journal of solid-state circuits, 1988. 3
[19] Diederik Kingma and Jimmy Ba. Adam: A method for
stochastic optimization. In ICLR, 2014. 6
[20] Philipp Krähenbühl and Vladlen Koltun. Efficient inference
in fully connected crfs with gaussian edge potentials. In
NIPS, 2011. 2
[21] Hanchao Li, Pengfei Xiong, Jie An, and Lingxue Wang.
Pyramid attention network for semantic segmentation. In
BMVC, 2018. 2
[22] Guosheng Lin, Anton Milan, Chunhua Shen, and Ian
Reid. Refinenet: Multi-path refinement networks for high-
resolution semantic segmentation. In CVPR, 2017. 2, 6, 7
[23] Guosheng Lin, Chunhua Shen, Anton V an Den Hengel, and
Ian Reid. Efficient piecewise training of deep structured
models for semantic segmentation. In CVPR, 2016. 2
[24] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He,
Bharath Hariharan, and Serge Belongie. Feature pyramid
networks for object detection. In CVPR, 2017. 2
[25] Chenxi Liu, Liang-Chieh Chen, Florian Schroff, Hartwig
Adam, Wei Hua, Alan L Y uille, and Li Fei-Fei. Auto-
deeplab: Hierarchical neural architecture search for semantic
image segmentation. In CVPR, 2019. 2
[26] Sifei Liu, Shalini De Mello, Jinwei Gu, Guangyu Zhong,
Ming-Hsuan Yang, and Jan Kautz. Learning affinity via spa-
tial propagation networks. In NIPS, 2017. 2
[27] Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia.
Path aggregation network for instance segmentation. In
CVPR, 2018. 2
[28] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian
Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C
Berg. Ssd: Single shot multibox detector. In ECCV, 2016. 2
[29] Wei Liu, Andrew Rabinovich, and Alexander C Berg.
Parsenet: Looking wider to see better. In ICLR, 2016. 2
[30] Ziwei Liu, Xiaoxiao Li, Ping Luo, Chen-Change Loy, and
Xiaoou Tang. Semantic image segmentation via deep parsing
network. In ICCV, 2015. 2
[31] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully
convolutional networks for semantic segmentation. In
CVPR, 2015. 2, 6
[32] Mohammadreza Mostajabi, Payman Yadollahpour, and Gre-
gory Shakhnarovich. Feedforward semantic segmentation
with zoom-out features. In CVPR, 2015. 2
[33] Hyeonwoo Noh, Seunghoon Hong, and Bohyung Han.
Learning deconvolution network for semantic segmentation.
In ICCV, 2015. 2
[34] Adam Paszke, Sam Gross, Soumith Chintala, Gregory
Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban
Desmaison, Luca Antiga, and Adam Lerer. Automatic dif-
ferentiation in PyTorch. In NIPS Autodiff Workshop, 2017.
6
[35] Chao Peng, Xiangyu Zhang, Gang Y u, Guiming Luo, and
Jian Sun. Large kernel matters–improve semantic segmenta-
tion by global convolutional network. In CVPR, 2017. 2
[36] Pedro HO Pinheiro and Ronan Collobert. Recurrent convo-
lutional neural networks for scene labeling. In ICML, 2014.
2
[37] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net:
Convolutional networks for biomedical image segmentation.
In MICCAI, 2015. 2
[38] Jianping Shi, Qiong Yan, Li Xu, and Jiaya Jia. Hierarchical
image saliency detection on extended cssd. TPAMI, 2015. 5
[39] Jamie Shotton, John Winn, Carsten Rother, and Antonio Cri-
minisi. Textonboost for image understanding: Multi-class
object recognition and segmentation by jointly modeling tex-
ture, layout, and context. In IJCV, 2009. 2
[40] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep
high-resolution representation learning for human pose esti-
mation. In CVPR, 2019. 2
[41] Yi Sun, Xiaogang Wang, and Xiaoou Tang. Deep convolu-
tional network cascade for facial point detection. In CVPR,
2013. 2
[42] Panqu Wang, Pengfei Chen, Ye Y uan, Ding Liu, Zehua
Huang, Xiaodi Hou, and Garrison Cottrell. Understanding
convolution for semantic segmentation. In WACV, 2018. 2
[43] Xintao Wang, Ke Y u, Shixiang Wu, Jinjin Gu, Yihao Liu,
Chao Dong, Y u Qiao, and Chen Change Loy. Esrgan: En-
hanced super-resolution generative adversarial networks. In
ECCV Workshop, 2018. 7
[44] Tianhan Wei, Xiang Li, Yau Pun Chen, Y u-Wing Tai, and
Chi-Keung Tang. FSS-1000: A 1000-class dataset for few-
shot segmentation. CoRR, abs/1907.12347, 2019. 5, 6
[45] Saining Xie and Zhuowen Tu. Holistically-nested edge de-
tection. In ICCV, 2015. 2
[46] Ning Xu, Brian Price, Scott Cohen, and Thomas Huang.
Deep image matting. In CVPR, 2017. 2
[47] Ning Xu, Brian Price, Scott Cohen, Jimei Yang, and Thomas
Huang. Deep grabcut for object selection. In BMVC, 2017.
2
[48] Chuan Yang, Lihe Zhang, Huchuan Lu, Xiang Ruan, and
Ming-Hsuan Yang. Saliency detection via graph-based man-
ifold ranking. In CVPR, 2013. 5
[49] Fisher Y u and Vladlen Koltun. Multi-scale context aggrega-
tion by dilated convolutions. In ICLR, 2016. 2
[50] Chi Zhang, Guosheng Lin, Fayao Liu, Rui Yao, and Chunhua
Shen. Canet: Class-agnostic segmentation networks with it-
erative refinement and attentive few-shot learning. In CVPR,
2019. 2
[51] Hang Zhang, Kristin Dana, Jianping Shi, Zhongyue Zhang,
Xiaogang Wang, Ambrish Tyagi, and Amit Agrawal. Con-
text encoding for semantic segmentation. In CVPR, 2018. 2,
7
[52] Hengshuang Zhao, Xiaojuan Qi, Xiaoyong Shen, Jianping
Shi, and Jiaya Jia. Icnet for real-time semantic segmentation
on high-resolution images. In ECCV, 2018. 2
[53] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang
Wang, and Jiaya Jia. Pyramid scene parsing network. In
CVPR, 2017. 2, 3, 6, 7
[54] Shuai Zheng, Sadeep Jayasumana, Bernardino Romera-
Paredes, Vibhav Vineet, Zhizhong Su, Dalong Du, Chang
Huang, and Philip Hilaire Sean Torr. Conditional random
fields as recurrent neural networks. In ICCV, 2015. 2
[55] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela
Barriuso, and Antonio Torralba. Scene parsing through
ade20k dataset. In CVPR, 2017. 5, 7
这篇关于CVPR2020论文翻译:CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








